2015-ben megjelent a Korolev Algorithm projekt a bináris opciók piacán, weboldala az algoritm-korolev.com, amely egy automatikus kereskedési rendszer. Mint a szerzők állítják, használatához minimális pénzügyi piacismerettel kell rendelkezni, hiszen egy teljes értékű kereskedési robotról van szó, amely automatikusan köti meg a tranzakciókat. A tanácsadó sikeres működésének fő feltétele a szükséges számítógépes képességek rendelkezésre állása.
A projekt fejlesztője, Denis Korolev és Maxim Nikitin olyan rendszert hozott létre, amely meghatározza a számítógép teljesítményét, és ha a szükséges követelmények teljesülnek, a felhasználó a projekt résztvevőjévé válik. A program telepítése után a számítógépek nagy szegmensekké egyesülnek, amelyek fenntartható trendet alkotnak. Ez lehetőséget ad a rendszer minden résztvevőjének, hogy pénzt keressen. A bináris opciók választása a kereseti módszerek elérhetőségének és a jelentős nyereségnek köszönhető.
A szerzők arra biztatják a projekt résztvevőit, hogy váljanak anyagilag függetlenné, és csak magukért dolgozzanak. Denis Korolev és Maxim Nikitin fiatal informatikai szakemberek, akiknek fiatalságuk ellenére sikerült saját terméket létrehozniuk, és több mint 2 millió dollárt keresni mindössze 14 hónap alatt.
A projekttel dolgozó kereskedő napi nyeresége elérheti az 500 dollárt is, a nagy teljesítményű számítógépek tulajdonosai pedig ennek többszörösére számíthatnak. A tanácsadó nemcsak személyi számítógéphez, hanem okostelefonhoz, táblagéphez és egyéb mobil eszközökhöz is alkalmas.
Hogyan működik a Koroljov algoritmus?
Minden ügyfél, aki meglátogatja az oldalt, átesik számítógépe ellenőrzésén, és eredményt kap a lehetséges napi nyereségről. Ezután előfizetővé kell válnia, és kereskedési számlát kell regisztrálnia az egyik pénzügyi közvetítőnél. A szerzők között megbízható cégek a WhiteOption és az Ubinary brókerek.
A kezdeti betét összege minimális lehet, de az ajánlott befektetések 300 dollártól kezdődnek. A rendszerben résztvevők száma több mint 1000 fő. A projekt sikerét az egyes résztvevők által hagyott számos videó értékelés igazolja.
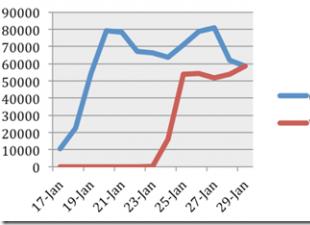
A weboldal tartalmaz egy táblázatot a napi tranzakciós statisztikákkal. Ezekből az adatokból az következik, hogy a legjövedelmezőbb szerződéseket devizapárokon kötik, és egy résztvevő átlagos nyeresége több mint 200 dollár tranzakciónként. A program ingyenes, a szerzők ugyanannyit keresnek, mint minden résztvevő. A nagy számú előfizető garantálja a sikert az egész csapat számára.
Milyen vélemények vannak az interneten?
A Korolev Algorithm projekt csalóként szerepel számos internetes forrásban. Valójában a szerzők csak brókerek ügynökei, és a bevonzott kereskedők betéteiből áttételi díjakért dolgoznak. A projekt weboldalán található vélemények nem igazak, és fizetett alapon készülnek. Minden kereskedési statisztikát a szerzők „rajzolnak”, hogy vonzzák a hiszékeny befektetőket.
2017. augusztus 22-én a Yandex hivatalosan bejelentette egy új „Korolev” keresési algoritmus elindítását (a városról nevezték el, mint a legtöbb korábbi keresési algoritmus). A komplex lekérdezések felismerésére szolgáló mechanizmuson alapul, amely az öntanuló neurális hálózat elvén működik. Ez azt jelenti, hogy a Yandexnek azonosítania kell a jelentésben releváns dokumentumokat, még akkor is, ha nem tartalmazzák a kérésben szereplő szavakat.
Miben különbözik Palekhtől?
2016 novemberében a Yandex elindította a „Korolev” elődjét - a „Palek” keresési algoritmust. Az új algoritmus fő különbsége a technikai megvalósítás javítása mellett, hogy a teljes dokumentumban képes felismerni a hasonló „jelentéseket”, nem csak a böngészőablakban megjelenő címet.
Miért valósították meg a Koroljov algoritmust?
A Yandex régóta gondolkodik azon a problémán, hogy a releváns dokumentumokat a nem teljesen természetes nyelven feltett, alacsony gyakoriságú lekérdezések nagy csoportjából azonosítsa. Ez a lekérdezések nagy listája, például:
— [melyik képen elolvad az óra]
- [ahol a kölnit feltalálták]
— [melyik filmben bolondul meg az író a szállodában]
A fő probléma az, hogy a megfelelő dokumentumok esetleg nem tartalmazzák a kérésben szereplő szavakat. Ennek megoldására és megfelelőbb eredmények felmutatására a „Korolev” algoritmus – egy öntanuló neurális hálózat – létrehozása született. Amint azt a Yandex maga is biztosítja, a gépi tanuláson alapuló neurális hálózat javítja a „jelentések” megértését, amelyeket a személy a lekérdezések bevitelekor sejtet.
Hogyan működik ez az algoritmus a gyakorlatban?
A Yandex által leírt megközelítés természetesen jól hangzik, de sokkal érdekesebb a konkrét eredményeket nézni a keresési eredmények között.
Először is vegyünk egy kérést, amelyet maga a Yandex hirdetett:
[kép a kavargó égboltról]
A jobb oldali objektumválaszokban a Yandex helyesen határozta meg, mit értünk kérésünk alatt. A helyes válaszokat a Yandex.Images-ben is jelezte. A kimenet többi része az új algoritmussal kapcsolatos hírekből áll. Nyilvánvalóvá válik: ebben a helyzetben a Yandex hagyományos módszereket használ a relevancia meghatározására, és a Korolev algoritmus nem működik az eredmények kiadására.
Próbáljuk meg másképp, és tegyük fel a következő lekérdezést:
[ahol megjelent az első parlament]

Ebben az esetben érdekes eredményt láthat. Az objektumválaszokban az „Anglia” érték jelent meg. Magában a keresési eredményekben különböző webhelyek találhatók, amelyek a lekérdezésből származó szavakat tartalmazzák.
Az objektumválaszokban szereplő algoritmus akkor működik, ha tudni akarjuk:
- Hol jelent meg a „parlament” szó?
– ahol megjelent az első képviselő- és törvényhozó testület, az úgynevezett „parlament”.
Az algoritmus nem működik:
- ha tudni akarjuk, hol jelent meg az első törvényhozó testület.
Általánosan elfogadott, hogy az első parlament Izlandon jelent meg, de nem „parlamentnek”, hanem „mindennek” nevezték. A keresési eredmények között (a fenti képernyőképen) láthatja a kérésünkre adott helyes választ. Csak azért jelent meg, mert a cikk címében a kérésből származó szavak szerepelnek.
Fontos megérteni:
A keresőmotor csak akkor tudja megérteni a lekérdezést, ha minden szónak egy világos jelentése van.
Ha egy szónak több jelentése van, mint a mi esetünkben a „parlament”, akkor problémák adódhatnak.
Végezzünk még egy kísérletet:
[dal a warringtoni támadásról]

A kérés a lehető legpontosabb, és csak egy konkrét válasz adható rá: a The Cranberries „Zombie” című dala.
Ha kicsit megváltoztatod a lekérdezést és megadod [dal az 1993-as terrortámadásról], láthatja, hogy a kereső szétválasztja a találatokat: a válaszok egy része a dalról szól, néhány pedig a terrortámadásról. A Yandex nem egészen érti, hogy pontosan miről szeretnénk információt kapni.

Ha még általánosabbá tesszük a lekérdezést, akkor egyáltalán nem lesz helyes válasz:
[dal az angliai terrortámadásról]

A kimenet teljes egészében a terrortámadásról szóló hírekből áll, és szó sincs az elhangzott jelentésről.
Most írjuk be a lekérdezést:
[film, amelyben egy író megőrül egy szállodában]

Ebben az esetben láthatja, hogy az algoritmus működik. A Yandex megérti, hogy mit akarunk találni, és egyúttal jelzi, hogy ennek a kérésnek két jelentése van (két szándék): a „The Shining” és az „1408” film. Itt is fontos, hogy a lekérdezésből származó szavak ne jelenjenek meg az oldalakon. Ebben az esetben az algoritmus működik.
Most próbáljunk meg beírni egy kérést:
[film, amelyben Travolta táncol]

A legnépszerűbb filmek opciói az objektumválaszokban találhatók, de a keresési eredmények között nem.
A válaszok pontosabbak lesznek, ha módosítja a lekérdezést:
[film, amelyben Travolta fiatalon táncol]

A helyes opció csak tárgyválasz és Wikipédia-oldal formájában látható. A kimenet többi része messze van a kívánt eredménytől.
Változtassuk meg újra a lekérdezést, és írjuk be:
[film, amelyben Travolta egy bárban táncol]

Amint látjuk, az algoritmus meghibásodik. Ez azért történik, mert rendkívül nehéz határozott választ adni erre a kérésre. Például a „Pulp Fiction” című filmben a tánc egy étteremben, a „Saturday Night Fever” című filmben egy klubban játszódik. De van egy „Michael” film, amelyben Travolta egy bárban táncol. Ha többször is teszteli a keresési eredményeket, hogy megtalálja a kívánt filmet, releváns találatok jelennek meg.

Milyen következtetéseket lehet ebből levonni?
- Az algoritmus csak a nagy információs oldalak (például a Wikipédia vagy a Kinopoisk) oldalain és az objektumválaszokban mutatja meg munkáját a keresési eredmények között.
- Az algoritmus csak olyan egyszerű lekérdezéseket ért meg, amelyek egy jelentést tartalmaznak.
- A „Korolev” jobban működik, ha népszerű információkat keres (például a „film” lekérdezéshez a legnépszerűbbet, a leghíresebbet mutatja - azt, amelyről a legtöbb információ található az indexben).
- Az algoritmus csak információkéréssel működik.
- Az algoritmus valóban öntanuló, és ismételt hívásokkal az eredmények jobbak lesznek.
A SEO esetében az algoritmus most keveset ad. A legtöbb lekérdezésnél a szöveges tényező nagy jelentőséggel bír. Ahol az új algoritmus működik, a Yandex az ismertebb oldalakat részesíti előnyben, például a Wikipediát. A kis projekteknek nehéz lesz versenyezni velük. Az ilyen lekérdezések magas helyezési képessége csak akkor jelenik meg, ha az algoritmus teljesebb tudásbázissal rendelkezik a felhasználók vágyairól és preferenciáiról. Ehhez azonban most szüksége lesz:
— olyan szöveges tartalmat hozzon létre, amely a lehető legtöbb szót tartalmazza, amely meghatározza az oldal témáját;
— a viselkedési tényezők javítása, hogy a keresőmotor biztosan tudja, hogy az oldal hasznos lesz a felhasználó számára.
Hogy nem csak az oldal címét, hanem az oldal teljes tartalmát is elemzi, mielőtt a lekérdezés eredményét megjeleníti a felhasználónak.
Már csak egy hét telt el, még korai következtetéseket levonni, de ennek ellenére megkérdeztük a SEO közösség képviselőit az új algoritmussal kapcsolatos elvárásaikról és a SEO mesterek munkájában bekövetkezett változásokról.
Kirill Nikolaev, a WEBLAB stúdió műszaki igazgatója:
Közvetlenül Palekh megjelenése után világossá vált az új algoritmus fejlesztésének további vektora. Közvetlenül a bejelentés előtt heves viták folytak arról, hogy mi fog történni (a legnépszerűbb lehetőség: az első oldal – online közvetlen), de legbelül mindannyian tudtuk, mire számíthatunk. A Yandex növelte a számokat, és ez jó hír. Ha korábban 150 dokumentum volt a RAM-ban a népszerű kérésekhez, most a számuk meghaladta a 200 000-et, nagyon szorgalmasan a tolokai speciális ügynökök segítségével. Ahhoz, hogy ebben a 200 000-ben legyél, jó viselkedési (ami logikus) és hasonló szemantikával kell rendelkezned, ami arra készteti az embert, hogy újult erővel térnek vissza a tartalomlopások napjai. És az online boltok katalógusaiban a hosszú lapok idői is azt mondják nekünk: „Helló, Andrey!”
Viszont tudtommal a népszerű lekérdezések mátrixa a következő frissítés idejére tárolódik az adatbázisban, míg a kisfrekvenciás/alacsony gyakoriságú lekérdezések mátrixa menet közben jön létre.
Nem szabad arra számítani, hogy olyan kolosszális változások következnek be a keresési eredményekben, mint a Snezhinsk 2009-es indulása után, ezért hagyjuk a HF/MF lekérdezéseket, és beszéljünk hétköznapibb dolgokról.
Engem személy szerint ez a kijelentés érdekelt a legjobban:
"...az új algoritmus nem csak egy weboldal szövegét hasonlítja össze a keresési lekérdezéssel, hanem más olyan lekérdezésekre is figyel, amelyek az adott oldalra juttatják az embereket." Az ipar számára ez két dolgot jelenthet:
1. Jó: a szemantika még körültekintőbb megválasztása, még szorgalmasabb klaszterezés meghozza gyümölcsét. A szövegtényezők fontosságban és relevanciában vezető szerepet töltenek be, a munka nehezebbé válik, de az eredmény jobb lesz.
2. Rossz: egy dokumentum indexeléséhez legfeljebb 32 ezer karakter lehet szöveget írni. Arra számíthatok tehát, hogy most valamelyik boltban a katalógusleírás alatt a vízszállításról szóló novellák olvashatók, melyekben van kezdet, fejlődés, csúcspont, végkifejlet és epilógus. Ez logikus, mert ez a legegyszerűbb módszer a szemantika kiterjesztésére. Persze túlzok, mert jól látszik, hogy a TOP valamelyest másképp alakul, de nagyon gyanítom, hogy a mi „tartalomkirályaink” így fogják fel.
Nos, ezen kívül csak eldobok egy gondolatot: mi van, ha nem írsz át szövegeket, és nem vesztegeti az időt bonyolult dolgokra, hanem megpróbálja hozzáértően generálni a forgalmat a kisfrekvenciás/alacsonyfrekvenciás kérésekre? Érdekes terep a kísérletezéshez.
A Yandex fejlődik, és mi is növekszünk vele.
Ez király. El szeretném képzelni milyen lesz 5-10-15 év múlva.
Ha jó SEO akarsz lenni, tanulj meg hardvert.
Ez csodálatos. Várom a BM új kurzusait „Szemantikai vektorok az üzleti életben” témában. De komolyan, a szakma egyre nehezebb, ami jó hír. Remélem, hamarosan eltűnnek azok a személyek, akik „Dmitrij Sahov (egy jól ismert SEO szakember) legújabb kutatása” szerint összeállított adatbázisokon linkelnek.
Még mélyebben merüljön el a szöveges tényezőkben
A BM kurzusainál jobban csak a szemantikai és klaszterezési neurális hálózatok kiválasztását várom a Chekushintól. És persze Devaki tanfolyam.
Alaev Alexander, az "Alaich and Co" webstúdió igazgatója:
A Yandex egy új algoritmust dobott ki nagy zajjal és izgalommal. Azt hittem, hogy az optimalizáló életem visszavonhatatlanul megváltozik, de... sietek megnyugtatni mindenkit - semmi sem változott!
Az új Yandex algoritmus célja a „hosszú” információs lekérdezések eredményeinek javítása (az ilyen lekérdezések jellemzőek a hangalapú keresésre). A Yandex a neurális hálózatával elkezdett érteni és jelentés szerint keresni, vagyis nem csak a kulcsszavak alapján, hanem a jelentésük alapján is. A „Paleh” folytatása, amely csak a dokumentumcímek alapján kereste a jelentéseket, a „Koroljov” a teljes dokumentumban keresi a jelentéseket. De ezt már tudod, ha megnézted az előadást, vagy olvastál az alapján publikációkat.
Beszéljünk arról, hogy ez milyen hatással lesz a webmesterek és keresőoptimalizálók életére. Ismétlem – dehogy. Az új algoritmus semmilyen módon nem befolyásolja a kereskedelmi kéréseket. Ha valaki vásárolni vagy rendelni akar valamit, akkor biztosan tudja, mi az. És ha nem is tudja, akkor mindenesetre, vagyis egy laptopra, nem azt fogja kérdezni, hogy „két félből álló kompakt asztali számítógép”, hanem először megtudja, mi ennek a dolognak a neve.
Koroljevnek pozitívan kell reagálnia a minőségi információs oldalakra. De a generált, szinonimizált és hasonló szövegeknek el kell veszíteniük a forgalmat, ha volt egyáltalán. Szerintem a témában elmerülés nélkül megírt átírás és szövegírás is megszenvedheti, átadva a helyét a jobb minőségű szövegeknek, igaz, a megfelelő kulcsszavak megfelelő mennyiségben történő használata nélkül.
Amint látja, nem mondtam semmi újat, de az oldalaknak, mint korábban, jó minőségűnek kell lenniük az emberek számára!
Alexander Ozhigbesov, projektmenedzserozhgibesov.net:
Azáltal, hogy új algoritmusokat vezet be a keresésbe, a Yandex apró, de magabiztos lépéseket tesz a kérés értelmének megértése és ugyanazon értelmes válasz megtalálása felé – így mutatja be Palekh és Korolev nekünk a vállalatnál. Valójában ez a 13-ban elindított Google algoritmus - Hummingbird másolata, de érdemes reálisan felmérni a vállalat rendelkezésre álló teljesítményét. A Yandex holnap nem tud minden egyedi kérésre választ adni, és nem tudja újraépíteni a keresési eredményeket. A cég hibája az, hogy újdonságként mutatták be az algoritmust, bár a Google korábban és ilyen „orosz” pátosz nélkül csinálta, de ez mindenképpen erős eredmény, és biztos vagyok benne, hogy a jövőben a neurális hálózatok képesek lesznek megmutatni nekünk a ideális keresés, ha Abban az időben a hazai kereső nem teszi fizetőssé a keresési eredmények teljes első oldalát. De ez sem különösebben ijesztő, osszuk el újra a prioritásokat, és méretezzük a szemantikát a kontextushoz.
Milyen változások várnak az optimalizálókra, és lesz-e egyáltalán?
Palekh és Koroljev után jelenleg nincs különösebb változás a népszerű e-kereskedelemben. Miközben a Yandex az MNC-n teszteli algoritmusait, nem számíthatunk drasztikus változásokra a cégek szabályozásában és módszereiben. Itt a keresőoptimalizálóknak nincs miért aggódniuk, a hosszú és egyedi lekérdezések csak információs témákban és komplex kereskedelmi szolgáltatásokban vannak jelen. Palekh és Koroljev feladata azonban nem az aktuális rangsorolási paraméterek pótlása, hanem összetett kérdésekre próbálnak értelmes választ adni, így egyáltalán nem szükséges olyan lekérdezéseket kiválasztani, mint a „Piros ruha, átlátszó bugyival”. Személyes véleményem az, hogy a tartalom minőségi írására és strukturálására, az azt követő elemzésekre és további optimalizálásra törekszem és törekszem a jövőben is, így az algoritmus nem okoz kárt komoly kereskedelmi projektekben, mint pl. Minusinszk.
A „Korolev” a Yandex keresőmotor algoritmusa, amelyen a keresés új verziója alapul. 2017 augusztusában indult. Ez a „Palek” algoritmus logikus folytatása. A keresési statisztikákra és a felhasználói viselkedésre kiképzett neurális hálózat összehasonlítja a lekérdezés és a weboldalak jelentését és lényegét, ami lehetővé teszi az összetett lekérdezések jobb megválaszolását.
Működés elve
A Korolev keresési algoritmus a korábban létrehozott Palekh-től eltérően nemcsak a címet, hanem az egész oldalt elemzi. A jelentés meghatározása az indexeléssel egyidejűleg történik, ami jelentősen növeli a feldolgozott oldalak sebességét és számát.
Számos lépéssel biztosítják, hogy a felhasználó választ kapjon. Mindegyiknél sorba rendezik a dokumentumokat, és a legjobbak továbblépnek a következő szakaszba. A szint emelkedésével egyre nehezebb algoritmusokat használnak.
Az utolsó szakasz felgyorsítása és az elemzett dokumentumok mennyiségének növelése érdekében egy további indexet vezettek be, amely tartalmazza a felhasználói lekérdezésekből származó népszerű szavak és párjaik indexelési szakaszában számított hozzávetőleges relevanciáját. Ez lehetővé tette számunkra, hogy jelentősen növeljük a mélységet - kérésenként akár 200 ezer dokumentumot.
A feltett kérdés és az oldal jelentésének összehasonlítása mellett az algoritmus figyelembe veszi, hogy a felhasználók milyen egyéb lekérdezéseket használtak egy adott dokumentum megtekintéséhez, ami további szemantikai kapcsolatok kialakítását teszi lehetővé.
Az algoritmus egy neurális hálózatot használ, amely anonimizált statisztikákra van kiképezve. A hétköznapi felhasználók részt vesznek a neurális hálózat képzésében. Ha korábban csak a Yandex munkatársai és értékelői vettek részt ebben, most bárki részt vehet a rangsorolási képletet felépítő Matrixnet gépi tanulási módszer betanításában, a Yandex.Toloka-beli feladatok elvégzésével.
A „Korolev” a többszavas lekérdezéseket a jelentés tisztázásával kezeli, és ezek általában információs, alacsony és mikrofrekvenciás, gyakran hangalapú kereséssel meghatározottak. A válasz olyan oldalak lehetnek, ahol a lekérdezésben használt szavak egy része teljesen hiányzik.

Közvetlenül azután, hogy a keresési eredmények jobb oldalán számos pontosító lekérdezés indult, a felhasználókat arra kérték, hogy értékeljék a kérdésre adott válasz minőségét, és jelöljék meg a sikeresebb webhelyet.
Hatás a SEO-ra
A Koroljov keresési algoritmus a legnagyobb hatással az összetett, bőbeszédű és gyakran egyedi megfogalmazású információkérésekre. Azonban észrevették, hogy azok a webhelyek, amelyeken előfordul néhány szó a lekérdezésből, gyakran magasabb pozíciókat kapnak.
A Koroljov algoritmusnak eddig gyakorlatilag nincs hatása a szokásos kereskedelmi lekérdezések keresési eredményeire. Azonban az, hogy a Yandex egyre inkább a jelentés megértésére összpontosít, azt sugallja, hogy ez idő kérdése. Ezért:
- jobban oda kell figyelnünk a tartalom információtartalmára, annak értékére, a felhasználó számára hasznosságára, vízhányás nélkül;
- a „hányinger” szöveg korszaka, a kulcskifejezések pontos előfordulása a múlté válik;
- az LSI szövegírás alapelveinek alkalmazása témameghatározó szavakkal, szinonimákkal stb. ígéretesebb, mint a hagyományos kulcsszóbevitel, és valahol további forgalmat vonzhat;
- nagy figyelmet kell fordítania a szemantikai jelölésekre, hogy segítsen a Yandexnek helyesen megérteni az oldalak tartalmát;
- Fontos a viselkedési tényezők magas szintjének fenntartása (látogatási idő, nézési mélység stb.).
A Yandex „űrbemutatója” nemcsak az index szerkezetének megváltoztatása, hanem egyfajta emlékeztető is arra, hogy tartalmat kell létrehoznia az emberek számára, nem csak a keresési eredmények manipulálására.
Tegnap a Yandex a bemutatóján hivatalosan is bejelentette az új Korolev algoritmus elindítását.
Elmondom, hogyan történt ez, és mit adott nekünk az új Yandex algoritmus.
Íme a bemutató tényleges adása:
Nem hárfázom el ezt a sok pátoszt, ami nem prezentáció volt, és elmondom a lényeget:
- A Koroljov algoritmus nem tegnap, hanem 2-6 hónapja indult el. Azt hiszem, mindenki megérti, hogy lehetetlen egy új algoritmust pillanatok alatt elindítani.
Azok. Az új Yandex algoritmus már régóta érvényben van, mindeddig csak tesztelt és hibakereső volt.
2. Ez egyáltalán nem új algoritmus. Egyáltalán nem. Ez a Palekh algoritmus, amelyben egyszerűen nem 150, hanem 2000 eredmény összehasonlítását tették lehetővé.
Nos, és konkrétan a Koroljev és Palekh közötti különbségről, a Yandex alkalmazottja hivatalosan mindent elmagyarázott nekünk:
Lényegében semmi sem változott. Csak a Yandex pátosza volt és semmi több.
Őszintén szólva nincs új algoritmus. Csak nem, ez minden. Még az organikus keresés is ugyanaz marad.
Ha új algoritmust vezetnének be, ingadozásokat látnánk a forgalomban. De nincsenek ilyen habozások.
Igen, elvileg nincs mit keresni.
A Yandex kimenet jelenleg így néz ki:

Pontosan mit keresel a kereséssel?!
Felül 4 közvetlen pozíció + 5. pozíció Piac, majd 4 közvetlen pozíció alul, jobb oldalon a Yandex.Market + Yandex.Bayan.
Mit kell itt keresni?
Mi a franc az a weboldal rangsoroló algoritmus? Mit kell rangsorolni?
Még egy új Yandex logót is rajzoltam:

Mi köze ehhez Koroljevnek? Úgy törődsz Koroljevvel, mint a Holddal. Úgy tettek, mintha nagy ember lennének.
Egyáltalán nem értem, mi történt. Ott volt a Yandex szokásos pátosza, és ennyi. Nincsenek globális változások a webhely rangsorolási algoritmusában.
Most menjünk végig magának ennek az algoritmusnak a bemutatásán.
Egy hónappal a prezentáció előtt a Yandex bejelentette, hogy beadhat egy jelentkezést a bemutató élőben történő megtekintésére a planetáriumban.
Én személyesen töltöttem ki a jelentkezést. És sokan kitöltötték. És mindannyian elutasítást kaptunk.
Valójában minden egyszerűbbnek bizonyult:
Csak összeszedték alkalmazottaikat, rokonaikat, ismerőseiket, barátnőiket és ismerőseik ismerőseit.
Miért is jelentkeztünk bármire is?! Nos, most már világos, hogy kit toboroz a Yandexhez.
De láthatóan túl sok ismerőst toboroztak, és sokan hülyén aludtak:
 Bassza meg, imádom az összes algoritmusodat, aludni akarok...
Bassza meg, imádom az összes algoritmusodat, aludni akarok...
Ez az ember, aki Sasha Sadovsky helyére jött: