Was ist uri. Was ist eine URL und wie wird damit gearbeitet? Der gefährlichste Spam ist persönlicher Natur
30.12.2020
Windows-Tutorials
Benutzer haben oft Fragen dazu, wie die URL einer Datei (Website) lautet, wie sie zu finden ist und welchen Wert eine solche Stütze hat. Unser Artikel liefert die notwendigen Antworten.
Was ist URL
Uniform Resource Locator steht für "Website Location Indicator". Eine URL-Kennung besteht aus einem Domänennamen und einem Pfad zu einer bestimmten Seite mit dem Namen ihrer Datei. Erfinder der URL war Tim Berners-Lee, Mitglied des European Nuclear War Council in Genf. Zum Zeitpunkt seiner Einführung im Jahr 1990 war eine Site-URL einfach die Adresse auf dem System, wo sich die Datei befindet. Um die URL der Website herauszufinden, schauen Sie einfach auf Adressleiste, und um die Dateiadresse zu ermitteln, müssen Sie zu gehen Kontextmenü indem Sie mit der rechten Maustaste auf das entsprechende Objekt klicken. Eine solche Adresse hat viele Vorteile, insbesondere die Verfügbarkeit der Navigation im Web, und hat auch einen Nachteil - die Fähigkeit, ausschließlich mit dem lateinischen Alphabet, einigen Symbolen und Zahlen zu arbeiten. Wenn es notwendig ist, das kyrillische Alphabet zu verwenden, wird eine spezielle Konvertierung durchgeführt.
Arten von URLs
Statisch - beinhaltet keine Änderungen an der Seite.
Dynamische URL – was das ist, können Sie verstehen, wenn Sie sich ein Suchformular oder ein anderes Navigationstool vorstellen, in dem Informationen in Abhängigkeit von eingehenden Anfragen generiert werden.
Eine Adresse mit einer Sitzungs-ID, die jedes Mal hinzugefügt wird, wenn Benutzer die Seite besuchen.
Die Bedeutung der URL in der SEO-Promotion
Suchmaschinen berücksichtigen die in der URL enthaltenen Schlüssel. Der größte Einfluss auf die Suchmaschinenwerbung Stichworte in der Domain und Subdomains.
Wenn die Seitenadresse informativ ist, erhöht sie auch das Ranking. Der Suchroboter wird es sehr wahrscheinlich als Antwort auf eine aktuelle Anfrage ausgeben.
Die URL, die der Abfrage entspricht, wird in hervorgehoben Suchergebnisse in fett, was zusätzliche Aufmerksamkeit erregt und die Klickrate erhöht.
Verschiedenen Quellen zufolge sind 50 bis 95 % aller E-Mails weltweit Spam von Cyber-Betrügern. Die Ziele des Versendens solcher Briefe sind einfach: den Computer des Empfängers mit einem Virus infizieren, Benutzerkennwörter stehlen, eine Person zwingen, Geld „für wohltätige Zwecke“ zu überweisen, persönliche Daten eingeben Bankkarte oder senden Sie Scans von Dokumenten.
Spam nervt oft auf den ersten Blick: krummes Layout, automatisch übersetzter Text, Passworteingabeformulare direkt in der Betreffzeile. Aber es gibt bösartige Briefe, die anständig aussehen, subtil mit den Emotionen einer Person spielen und keine Zweifel an ihrer Richtigkeit aufkommen lassen.
Der Artikel wird über 4 Arten von betrügerischen Briefen sprechen, die am häufigsten von Russen verfolgt werden.
1. Schreiben von „Regierungsorganisationen“



Betrüger können vorgeben, Steuer zu sein Pensionsfonds, Rospotrebnadzor, sanitäre und epidemiologische Station und andere Regierungsorganisationen. Zur Überzeugungskraft werden Wasserzeichen, Scans von Siegeln und Staatssymbolen in den Brief eingefügt. Meistens besteht die Aufgabe von Kriminellen darin, eine Person zu erschrecken und sie davon zu überzeugen, eine Datei mit einem Virus im Anhang zu öffnen.
Normalerweise ist es eine Ransomware oder ein Windows-Blocker, der den Computer deaktiviert und Sie auffordert, eine kostenpflichtige SMS zu senden, um die Arbeit wieder aufzunehmen. Eine schädliche Datei kann als Gerichtsbeschluss oder Vorladung getarnt werden, um den Leiter der Organisation anzurufen.
Angst und Neugier schalten das Bewusstsein des Nutzers aus. Buchhalterforen beschreiben Fälle, in denen Mitarbeiter von Organisationen Dateien mit Viren auf ihre Heimcomputer brachten, da sie sie aufgrund von Antivirenprogrammen im Büro nicht öffnen konnten.
Manchmal bitten Betrüger Sie, Dokumente als Antwort auf einen Brief zu senden, um Informationen über das Unternehmen zu sammeln, die für andere Betrugssysteme nützlich sind. Letztes Jahr gelang es einer Gruppe von Betrügern, viele Menschen zu betrügen, indem sie die Ablenkung „Fax-Papieranforderung“ verwendeten.
Als ein Buchhalter oder Manager das las, verfluchte er sofort das Finanzamt: „Da sitzen Mammuts, e-mine!“ und wechselte seine Gedanken vom Brief selbst zur Lösung Technische Probleme mit Versand.
2. Briefe von "Banken"


Windows-Blocker und Ransomware können sich in gefälschten Briefen nicht nur von Regierungsorganisationen, sondern auch von Banken verstecken. Die Meldungen „Auf Ihren Namen wurde ein Kredit aufgenommen, sehen Sie sich die Klage an“ können wirklich Angst machen und einen großen Wunsch hervorrufen, die Akte zu öffnen.
Auch kann eine Person dazu überredet werden, eine falsche Eingabe einzugeben persönliches Büro, indem er anbietet, die angesammelten Boni zu sehen oder einen Preis zu erhalten, den er in der Sberbank-Lotterie gewonnen hat.
Seltener senden Betrüger Rechnungen zur Zahlung von Servicegebühren und zusätzlichen Zinsen für ein Darlehen in Höhe von 50 bis 200 Rubel, die einfacher zu bezahlen als zu handhaben sind.
3. Briefe von "Kollegen"/"Partnern"
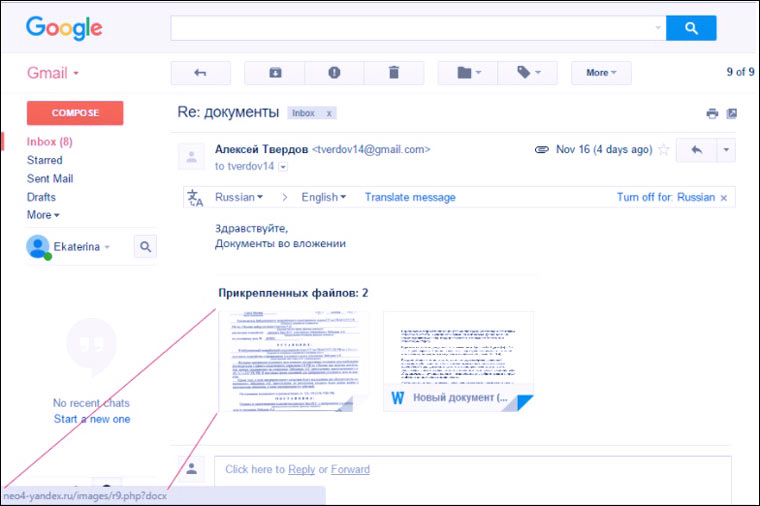
Manche Menschen erhalten im Laufe des Arbeitstages Dutzende von Geschäftsbriefen mit Dokumenten. Bei einer solchen Belastung können Sie leicht auf das „Re:“-Tag in der Betreffzeile hereinfallen und vergessen, dass Sie mit dieser Person noch nicht korrespondiert haben.
Vor allem, wenn auf dem Giftmischerfeld "Alexander Ivanov", "Ekaterina Smirnova" oder irgendetwas Einfaches steht Russischer Name die einem Menschen, der ständig mit Menschen arbeitet, absolut nicht in Erinnerung bleiben.
Wenn das Ziel von Betrügern nicht darin besteht, SMS-Zahlungen für das Entsperren von Windows zu sammeln, sondern einem bestimmten Unternehmen zu schaden, können Briefe mit Viren und Phishing-Links im Namen echter Mitarbeiter versendet werden. Eine Liste der Mitarbeiter kann in sozialen Netzwerken gesammelt oder auf der Website des Unternehmens eingesehen werden.
Wenn eine Person einen Brief von einer Person aus einer benachbarten Abteilung im Briefkasten sieht, dann schaut er nicht genau hin, er kann sogar Antivirus-Warnungen ignorieren und die Datei um jeden Preis öffnen.
4. Briefe von Google/Yandex/Mail


Google sendet manchmal E-Mails an Eigentümer Gmail-Boxen dass jemand versucht hat, sich bei Ihrem Konto anzumelden oder dass der Speicherplatz auf dem Google Drive. Betrüger kopieren sie erfolgreich und zwingen Benutzer, Passwörter auf gefälschten Websites einzugeben.
Gefälschte Briefe von der „Verwaltung des Dienstes“ werden auch von Benutzern von Yandex.Mail, Mail.ru und anderen E-Mail-Diensten empfangen. Standardlegenden sind: „Ihre Adresse wurde auf die schwarze Liste gesetzt“, „Passwort ist abgelaufen“, „Alle E-Mails von Ihrer Adresse werden in den Spam-Ordner verschoben“, „Schauen Sie sich die Liste der nicht zugestellten E-Mails an“. Wie in den vorherigen drei Absätzen sind die Hauptwaffen der Kriminellen die Angst und Neugier der Benutzer.
Wie kann man sich schützen?

Installieren Sie auf allen Ihren Geräten ein Antivirenprogramm, damit es automatisch blockiert wird bösartige Dateien. Wenn Sie es aus irgendeinem Grund nicht verwenden möchten, überprüfen Sie alle zumindest leicht verdächtigen E-Mail-Anhänge auf virustotal.com
Geben Sie Passwörter niemals manuell ein. Verwenden Sie Passwortmanager auf allen Geräten. Sie werden Ihnen niemals die Möglichkeit bieten, Passwörter auf gefälschten Websites einzugeben. Wenn Sie sie aus irgendeinem Grund nicht verwenden möchten, geben Sie sie manuell ein Seiten-URL auf dem Sie das Passwort eingeben werden. Dies gilt für alle Betriebssysteme.
Aktivieren Sie nach Möglichkeit die SMS-Passwortüberprüfung oder die Zwei-Faktor-Authentifizierung. Und natürlich sei daran erinnert, dass Sie keine Scans von Dokumenten, Passdaten und Geld an Fremde senden können.
Vielleicht dachten viele Leser beim Betrachten der Screenshots von Briefen: „Bin ich ein Dummkopf, Dateien aus solchen Briefen zu öffnen? Aus einer Entfernung von einer Meile kann man sehen, dass dies ein Set-up ist. Ich werde mich nicht um einen Passwort-Manager und eine Zwei-Faktor-Authentifizierung kümmern. Ich werde einfach vorsichtig sein."
Ja, die meisten betrügerischen E-Mails können mit bloßem Auge entdeckt werden. Dies gilt jedoch nicht, wenn sich der Angriff speziell gegen Sie richtet.
Der gefährlichste Spam ist persönlicher Natur

Wenn eine eifersüchtige Frau die E-Mails ihres Mannes lesen möchte, bietet Google ihr Dutzende von Websites an, die den Dienst „Hacking von E-Mails und Profilen in sozialen Netzwerken ohne Vorauszahlung“ anbieten.
Das Schema ihrer Arbeit ist einfach: Sie senden qualitativ hochwertige Phishing-E-Mails an eine Person, die sorgfältig verfasst und übersichtlich gestaltet sind und die persönlichen Merkmale einer Person berücksichtigen. Solche Betrüger versuchen aufrichtig, ein bestimmtes Opfer zu fangen. Sie erfahren vom Kunden ihr soziales Umfeld, Vorlieben, Schwächen. Es kann eine Stunde oder länger dauern, einen Angriff auf eine bestimmte Person zu entwickeln, aber der Aufwand zahlt sich aus.
Wenn das Opfer erwischt wird, senden sie dem Kunden einen Bildschirm der Box und fordern ihn auf, für seine Dienste zu zahlen (der Durchschnittspreis beträgt etwa 100 US-Dollar). Nach Geldeingang senden sie ein Passwort aus der Box oder einem Archiv mit allen Briefen.
Es kommt oft vor, dass, wenn eine Person einen Brief mit einem Link zu der Datei „Kompromittierendes Video über Tanya Kotova“ erhält ( versteckter Keylogger) von seinem Bruder, dann voller Neugier. Ist der Brief mit einem Text versehen, dessen Details einem begrenzten Personenkreis bekannt sind, so leugnet die Person sofort die Möglichkeit, dass der Bruder gehackt worden sein könnte oder sich jemand anderes für ihn ausgibt. Das Opfer entspannt sich und deaktiviert das gottverdammte Antivirenprogramm, um die Datei zu öffnen.
Auf solche Dienste können nicht nur eifersüchtige Ehefrauen zugreifen, sondern auch skrupellose Konkurrenten. In solchen Fällen ist der Preis höher und die Methoden dünner.
Verlassen Sie sich nicht auf Ihre Aufmerksamkeit und Ihren gesunden Menschenverstand. Lassen Sie sich für alle Fälle von einem emotionslosen Antivirus und einem Passwort-Manager versichern.
P.S. Warum schreiben Spammer solche „dummen“ E-Mails?
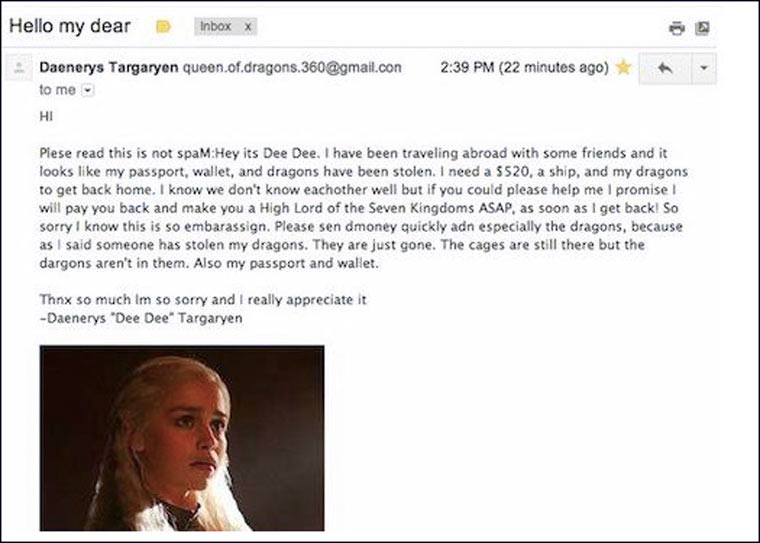
Sorgfältig gestaltete Betrugs-E-Mails sind eine relative Seltenheit. Wenn Sie in den Spam-Ordner gehen, können Sie von Herzen Spaß haben. Welche Art von Charakteren werden nicht von Betrügern erfunden, um Geld zu erpressen: der Direktor des FBI, die Heldin der Game of Thrones-Serie, ein Hellseher, der von höheren Mächten zu Ihnen geschickt wurde und der für $ das Geheimnis Ihrer Zukunft lüften möchte 15 Dollar, ein Mörder, der Sie bestellt hat, aber er bietet aufrichtig an, ihn zu bezahlen.
Eine Fülle von Ausrufezeichen, Knöpfe im Briefkasten, eine seltsame Absenderadresse, ein unbenannter Gruß, automatische Übersetzung, grobe Fehler im Text, ein klarer Overkill an Kreativität – Briefe im Spam-Ordner „schreien“ nur noch nach ihrer dunklen Herkunft.
Warum wollen Betrüger, die ihre Nachrichten an Millionen von Empfängern senden, nicht ein paar Stunden damit verbringen, einen ordentlichen Brief zu schreiben und 20 Dollar für einen Übersetzer zu sparen, um die Reaktion des Publikums zu erhöhen?
In einer Microsoft-Studie Warum sagen nigerianische Betrüger, dass sie aus Nigeria kommen? Die Frage „Warum versenden Betrüger weiterhin Briefe im Namen von Milliardären aus Nigeria, wenn die breite Öffentlichkeit seit 20 Jahren von ‚nigerianischen Briefen‘ weiß“, wird eingehend analysiert. Laut Statistik ignorieren mehr als 99,99 % der Empfänger solchen Spam.
Verirren kann man sich nicht nur im Wald, sondern auch online. Und dies kann durch den falschen Pfad oder die falsche Adresse verursacht werden, die zur Ressource führt. Sie wissen nicht, was eine URL ist? Bevor wir uns dann auf eine weitere Reise durch den virtuellen Raum begeben, beschäftigen wir uns mit dem System der elektronischen Adressen.
Was ist URL
Eine URL ist ein allgemein akzeptierter Standard zum Schreiben einer Adresse und zum Anzeigen des Standorts einer Ressource im Internet. Aus dem Englischen sein Name ( Uniform Resource Locator) wird als Uniform Resource Locator übersetzt. Sie finden eine frühere Dekodierung der Abkürzung URL - Universal Resource Locator (universeller Ressourcenfinder). Aber beide Bedeutungen ergänzen das Konzept der URL, anstatt sich zu überschneiden.
Das Grundformat eines URL-Struktureintrags sieht folgendermaßen aus:
://:@:/?#
- bezieht sich meistens auf das Protokoll.
login – Benutzeranmeldung, die für die Autorisierung auf der Ressource verwendet wird.
password - Benutzerpasswort für die Autorisierung.
host ist der Domänenname des Hosts.
port - der Host-Port, der während der Verbindung verwendet wird.
URL – der Pfad, in dem sich die angeforderte Ressource auf dem Server befindet.
Parameter und Anker– der Wert der Variablen und die Kennung einer bestimmten Ressource.
Das Übergeben des Werts von Variablen in der Abfragezeichenfolge ist nur mit der GET-Methode möglich.
Beachten Sie das URL-Format der Seitenadresse der angeforderten Ressource praktische Beispiele. Auf der Kundenseite Die URL wird in der Adressleiste des Browsers angezeigt:
Die häufigsten Optionen sind:
- http://en.wikipedia.org/wiki/Main_page- http wird verwendet, um die Anfrage zu senden ( Hypertext Transfer Protocol);
- https://ru.wikipedia.org/wiki/Main_page- Als Übertragungsverfahren wird https verwendet. Ist eine sichere Form des HTTP-Protokolls, das Verschlüsselung verwendet (SSL oder TLS);
- fttp://wikipedia.org/wiki/file.txt– Dateiübertragungsprotokoll fttp ;
- http://mail.ru/script.php?num=10&type=new&v=text– Übergeben von Variablenwerten in der Abfragezeichenfolge mithilfe der GET-Methode.
Jedes URL-Format ist in erster Linie eine Zeichenfolge. Es kann beinhalten:
2; Briefe.
2; Arabische Ziffern (0-9).
2; Reservierte Zeichen ("+", "=", "!" und andere).
2; Sonderzeichen - wir werden näher darauf eingehen.
Verwendung von Sonderzeichen in URLs
Solche allzu „Sonderzeichen“ werden natürlich nicht in der URL verwendet. Aber es gibt ein paar:
- ? – dient zur Trennung des Blocks mit den übergebenen Parametern im Query-String;
- & - trennt die übergebenen Parameter voneinander;
- = - trennt die Variable im Parameter von ihrem Wert;
- : - dient dazu, das Protokoll vom Rest der URL zu trennen;
- # - das Zeichen wird im lokalen Teil der Adresse verwendet. Ermöglicht Ihnen den Zugriff auf einen bestimmten Teil der angeforderten Seite;
- @ - Angegeben in den Benutzerregistrierungsdaten und bei der Datenübertragung mit dem mailto-Protokoll.
Aber das ist alles nur eine Theorie. Bevor wir den Rest lernen, schauen wir uns daher ein kleines praktisches Beispiel an.
bildhaftes Beispiel
Nehmen wir zur Verdeutlichung dieses einfache Anmeldeformular:
Hier ist ihr Code:
Anmeldeformular
In der ersten Zeile am Anfang des Formulars haben wir dafür eine Handler-Datei (php) und eine Methode zum Übertragen von Daten über die Server-URL geschrieben:
Hier ist nun der Handler-Dateicode (1.php):
Dein Nick:".$_GET["nick"]."
"; Echo"
Ihr Alter:".$_GET["Alter"]."
";
?>
Geben Sie die Daten in das Formular ein und senden Sie es zur Verarbeitung an den Server. Hier ist, was wir am Ende haben werden:
Achten Sie auf das URL-Format in der Adressleiste im ersten Screenshot. Nach Eingabe der Daten und Klick auf den Button „Daten senden“ werden die Werte aller Felder zur Verarbeitung an den Server gesendet. Und wir werden auf Seite 1.php umgeleitet, wo sich der Handler-Code befindet.
Bevor Sie sich das Ergebnis der Verarbeitung ansehen, werfen Sie einen Blick auf die Adressleiste in der zweiten Abbildung. Es zeigt die Werte der Felder an, die mit der GET-Methode zur Verarbeitung übermittelt wurden.
Die POST-Methode wird verwendet, um die an den Server gesendeten Daten zu verbergen. Dann würde die obige URL so aussehen:
http://localhost/home/1.php .
Website-URL-Format
Meistens verwenden Websites eine Baumsystem-URL. Das heißt, die richtige URL-Adresse besteht aus mehreren verschachtelten Elementen, von denen das letzte die gewünschte Webseite ist.
Nehmen wir zur Verdeutlichung eine bestimmte URL, die einer der Zweige der Adresse unserer Website ist:
https://www.html
Lassen Sie es uns Stück für Stück aufschlüsseln:
- www.site - dieser Teil ist Domänenname Seite? ˅. Wenn Sie es in die Adressleiste Ihres Browsers eingeben, gelangen Sie zur Hauptseite der Website. In den meisten Fällen ist dies der Index. html;
- Vorlagen- dieser Teil Die Adresse verweist auf einen bestimmten Abschnitt der Website. In unserem Fall ist dies der Abschnitt mit Vorlagen;
- page_2.html - ist das letzte Element der URL, die zur Webseite des thematischen Abschnitts der Ressource führt.
Meistens zeigen die URL-Adressen der Hauptabschnitte die Sitemap vollständig an. Aber nicht alles ist so einfach mit Weiterleitungen auf Websites, die auf der Grundlage beliebter Suchmaschinen (CMS) bereitgestellt werden.
Funktionen zum Erstellen von URLs in WordPress
In WordPress, wie in jeder Engine, die auf PHP basiert, ist die Generierung aller Seiten der Website dynamisch. Das heißt, ein Teil wird aus einer Vorlage genommen, der andere wird spontan auf der Grundlage mehrerer generiert ... Aber eine solche Volatilität hat einen erheblichen Nachteil - das Vorhandensein von Teilen übertragener Parameter in der URL.
Zudem verletzt dies nicht nur die ästhetische Komponente der Adressdarstellung, sondern wird auch von Suchmaschinen mehrdeutig wahrgenommen. Und dies kann sich negativ auf die Werbung für die Website auswirken:
Daher ist es besser, saubere URLs auf Ihrer Website zu verwenden. Aber wo bekomme ich sie her, wenn das CMS-System keine Möglichkeit bietet, sie zu bearbeiten?
Saubere URLs sind Adressen, die keine übergebenen Parameter (bei WordPress Datenbankabfrageelemente) enthalten, sondern nur den Pfad zum Dokument. Das heißt, https://www..html ist ein Beispiel für eine saubere URL.
Die einfachste Möglichkeit, die Anzeige von URLs in WordPress anzupassen, ist die Verwendung spezialisierter Plugins.
Streitigkeiten zu diesem Thema - wie schreibt man eine URL richtig, mit oder ohne Schrägstrich am Ende? - waren und werden sein. Die Argumente sind vielfältig und oft widersprüchlich. Und es gibt zwei Arten von Auszahlungen für eine falsche Darstellung eines Uniform Resource Locator (URL). Seitens der Suchmaschinen sind dies vermeintliche Strafen für doppelte Seiten. Aus Performance-Sicht handelt es sich dabei angeblich um eine extra vom Server automatisch generierte Weiterleitung auf die Seite des richtigen Eintrags.
Allerdings parsen technische Spezifikationen Internetstandards, insbesondere dem Dokument „RFC 1738 – Uniform Resource Locators (URL)“, müssen wir zugeben, dass beide Möglichkeiten zur Erfassung der Adresse einer Webressource formal korrekt sind, und die Sanktion für die Nutzung der einen oder anderen Option nichts mehr ist als eine Macke Suchmaschine oder Geschichten von Pseudo-SEO-shnikov.
Aus Gründen der Prägnanz scheint die Option ohne Schrägstrich am Ende richtiger zu sein, unabhängig davon, ob Ihr Link eine "Datei" auf dem Server oder einen "Ordner" anspricht, was im Folgenden indirekt bewiesen wird. Aber es gibt keine einzige Aussage in dem Dokument, dass eine andere Option falsch ist oder sich auf eine völlig andere Ressource bezieht.
Ich werde Sie nicht mit einer mehrseitigen Übersetzung des erwähnten RFC belasten, da erstens der Zweck der Frage Schrägstriche am Ende der URL waren und zweitens die Veröffentlichung an einfache Benutzer von Engines gerichtet ist, einschließlich dieser die sich nicht für alle Details interessieren, warten auf kurze Erklärungen und stichhaltige Beweise. Dementsprechend werde ich Auszüge aus diesem Dokument als Beweis zitieren und erläutern. Wen es nicht interessiert, kann sich gleich das Fazit am Ende des Artikels anschauen.
Allgemeine URL-Syntax
Zunächst möchte ich auf einen Auszug aus Abschnitt 2 hinweisen. Allgemeine URL-Syntax (allgemeine URL-Syntax). Ich gebe jeweils ein Textfragment in der Originalsprache und dann eine Übersetzung ins Russische.
URLs werden verwendet, um Ressourcen zu „lokalisieren“, indem sie eine abstrakte Identifizierung des Ressourcenorts bereitstellen. URLs werden verwendet, um Ressourcen zu „lokalisieren“, indem sie eine abstrakte Identifizierung des Ressourcenorts bereitstellen.
Das heißt, die URL selbst ist eine reine Abstraktion. Dass es uns äußerlich ähnlich erscheinen mag wie der Name einer Datei oder eines Ordners, bedeutet keineswegs einen physikalischen Hinweis auf genau diese oder jene Datei und nicht auf eine andere im Dateibereich des Servers. Dies wird später im Dokument ausdrücklich angegeben.
Die Notiz Generell ist es bei http-Links grundsätzlich falsch zu sagen, dass bspw.
- http://domain.com/Pfad/Unterpfad/Dateiname.txt- deutet angeblich auf eine Akte hin
- http://domain.com/path/subpath/- zeigt angeblich auf einen Ordner
- http://domain.com/path - verweist angeblich fälschlicherweise auf einen Ordner
Wir sind es nur gewohnt, das zu sagen, weil es praktisch ist, Links mit Dateien auf der Website zu verknüpfen. Tatsächlich verweisen alle diese Links auf eine Ressource und geben in keiner Weise die Art der Ressource an. Was sich hinter jeder Ressource verbirgt, also was für eine echte Datei oder welcher Ordner und welche Art von Inhalt ein solcher Link liefert, wird bereits durch die Serverkonfiguration festgelegt.
Es ist wichtig zu verstehen, dass es in Links so etwas wie „Datei“, „Ordner“, „Unterordner“, „Text“, „Bild“, „HTML“, „Skript“, „Stylesheet“ und so weiter nicht gibt. Kein Schrägstrich am Ende oder sein Fehlen bedeutet absolut nichts, bis der Link die Transformation innerhalb des Servers durchläuft und er selbst entscheidet, wohin der Link tatsächlich führt und welche Art von Inhalt sich dahinter verbirgt. Nur diese Entscheidung bezieht sich auf die interne Architektur des Servers.
Hierarchische Schemata
Das Folgende ist ein Auszug aus Abschnitt 2.3 Hierarchische Schemata und relative Verknüpfungen.
Einige URL-Schemata (wie FTP-, http- und Dateischemata) enthalten Namen, die als hierarchisch betrachtet werden können; die Komponenten der Hierarchie werden durch "/" getrennt. Einige URL-Schemata (wie ftp, http und file) enthalten Namen, die als hierarchisch angesehen werden können; Hierarchieelemente werden durch "/" getrennt.
Das heißt, es wird argumentiert, dass es in getrennten Adressschemata nicht verboten ist, dass die Inhalte des Ressourcenlokalisierers hierarchisch impliziert werden, und es wurde noch nicht festgelegt, dass die Hierarchie mit irgendeiner Form, beispielsweise einer Datei, äquivalent ist.
Allgemeine Netzwerkdiagramm-Syntax
Nachfolgend ein Auszug aus Ziffer 3.1. Common Internet Scheme Syntax (gemeinsame Netzwerk-Schema-Syntax).
//:@:/Einige oder alle Teile" :@", ":",
":", und "/ " kann ausgeschlossen werden. Einige oder alle Teile " :@", ":",
":" und "/ “ kann ausgeschlossen werden.
Die Notiz Dies ist übrigens eine Antwort auf eine Frage, die sich von der hier betrachteten Frage ableitet. Oft streiten sie sich zu diesem Thema: Wie gebe ich einen Link zu einer Domain (Host) - ohne Schrägstrich am Ende oder mit Schrägstrich?
Wie richtig http://domain.com/ oder http://domain.com ?
Und so und so richtig. Es ist nur so, dass der erste Schrägstrich nach dem Hostnamen dazu da ist, den Pfadnamen vom Hostnamen zu trennen. Im selben Absatz des Dokuments heißt es:
URL-Pfad Der Rest des Locators besteht aus schemaspezifischen Daten und ist als "URL-Pfad" bekannt. Es liefert die Details, wie auf die angegebene Ressource zugegriffen werden kann. Beachten Sie, dass das „/“ zwischen dem Host (oder Port) und dem URL-Pfad NICHT Teil des URL-Pfads ist. Der Rest des Locators besteht aus schemaspezifischen Daten und wird als "url-path" (URL-Pfad) bezeichnet. Es enthält Details darüber, wie auf die angegebene Ressource zugegriffen werden kann. Beachten Sie, dass das Zeichen „/“ zwischen dem Host (oder Port) und dem URL-Pfad nicht Teil des URL-Pfads ist.
Sie müssen dieses abschließende Zeichen in keiner Weise einfügen oder es nicht einfügen, wenn der URL-Pfad eine leere Zeichenfolge ist (wie viele von uns sagen würden, wenn die URL auf das Stammverzeichnis der Site verweist). Niemand hat das Recht, Sie "für zwei Takes der Hauptseite" zu bestrafen, weil Sie laut Spezifikation in beiden Fällen die URL auf dieselbe Ressource verlinken.
Lass uns weitermachen ein weiterer Auszug aus dem gleichen Absatz.
Die URL-Pfad-Syntax hängt vom verwendeten Schema ab, ebenso wie die Art und Weise, wie es interpretiert wird. Die URL-Pfad-Syntax hängt vom verwendeten Schema sowie von der Art und Weise ab, wie es interpretiert wird.
Dies ist eine weitere Bestätigung dafür, dass jedes Lokalisierungsschema sein eigenes Konzept von "Hierarchie" und der Art und Weise hat, wie es interpretiert wird.
Hierarchie
Bei einigen Dateisystemen entspricht das zur Bezeichnung der hierarchischen Struktur der URL verwendete "/" dem Trennzeichen, das zum Aufbau einer Dateinamenhierarchie verwendet wird, und daher sieht der Dateiname ähnlich wie der URL-Pfad aus. Dies bedeutet NICHT, dass die URL ein Unix-Dateiname ist. Das Zeichen "/" wird verwendet, um die hierarchische Struktur der URL gemäß dem beim Aufbau der Dateinamenhierarchie verwendeten Trennzeichen anzuzeigen, und daher sieht der Dateiname in einigen Dateisystemen wie der URL-Pfad aus. Aber das bedeutet nicht, dass die URL ein Unix-ähnlicher Dateiname ist.
Obwohl dieser Absatz für das ftp-Schema gilt, gelten seine Aussagen auch für andere Schemata (http, gopher, prospero usw.). Nur im Dateischema bedeutet der Schrägstrich logischerweise dasselbe wie zB in Dateinamen file://server_or_device/path/subpath/filename.txt.
http
Eine HTTP-URL hat die Form: http:// :/?wo und Sind wie in Abschnitt 3.1 beschrieben. Wenn: Wird weggelassen, ist der Port standardmäßig 80. Es ist kein Benutzername oder Passwort zulässig. Ist ein HTTP-Selektor und ist eine Abfragezeichenfolge. Das Ist optional, ebenso wie die und dem vorangestellten "?". wenn auch nicht Noch vorhanden ist, kann das „/“ auch weggelassen werden. Innerhalb der Und Komponenten, "/", ";", "?" sind reserviert. Das Zeichen „/“ kann innerhalb von HTTP verwendet werden, um eine hierarchische Struktur zu kennzeichnen. Die URL des http-Schemas hat folgende Form: http:// :/?wo und Wie in Abschnitt 3.1 beschrieben. Wenn ein: Ausgelassen, der Standardport wird als 80 angenommen. Der Benutzername oder das Passwort ist ungültig. Es ist ein HTTP-Selektor und - Abfragezeichenfolge. Es ist optional, wie es ist zusammen mit dem vorangestellten "?"-Zeichen. Wenn weder Weder nicht vorhanden sind, kann das Zeichen „/“ auch weggelassen werden. In Elementen Und Figuren "/", ";", "?" sind reserviert. Das Zeichen „/“ kann in HTTP verwendet werden, um eine hierarchische Struktur zu definieren.
Die Notiz Es besagt auch, dass Sie einen Link ohne nachgestellten Schrägstrich angeben können. In diesem Fall haben wir über eine Situation gesprochen, in der der Linkpfad leer ist – zeigt auf das Stammverzeichnis des Hosts.
Formale Notation
Und zum Schluss noch ein Auszug aus Paragraph 5. BNF für bestimmte URL-Schemata (formale Notation für bestimmte URL-Schemata).
Optionale Teile sind hier in eckigen Klammern angegeben. Ein Sternchen vor einer Klammer bezeichnet 0 oder mehr Wiederholungen des Fragments, wie in den Klammern angegeben. Der senkrechte Strich ist als ODER zu verstehen.
Hostport = host [ ":" port ] ... ... httpurl = "http://" hostport [ "/" hpath [ "?" Suche]] hPfad= hsegment *[ "/" hsegment ] hsegment = *[ uchar | ";" | ":" | "@" | "&" | "=" ] Suche = *[ uchar | ";" | ":" | "@" | "&" | "=" ] ... ... lowalpha = "a" | "b" | "c" | "d" | "e" | "f" | "g" | h | "ich" | "j" | "k" | "l" | "m" | "n" | "o" | p | "q" | "r" | "s" | "t" | "du" | "v" | "w" | "X" | "j" | "z" hialpha = "A" | "B" | "C" | "D" | "E" | "F" | "G" | "H" | "Ich" | "J" | "K" | "L" | "M" | "N" | "O" | "P" | Q | "R" | "S" | "T" | U | "V" | W | "X" | "J" | "Z" alpha = niedrigalpha | Hialpha-Ziffer = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" sicher = "$" | "-" | "_" | "." | "+" extra = "!" | "*" | """ | "(" | ")" | "," Hex = Ziffer | "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" | "c" | "d" | "e" | "f" escape = "%" hex hex unreserved = alpha | digit | safe | extra uchar = unreserved | escape
Achten Sie darauf, wie genau das hpath-Element nach den Regeln gebildet wird - der Pfad des Links. Die hsegment-Elemente eines Pfades – die Segmente – werden durch einen Schrägstrich getrennt. Als würde er auf die wichtige Idee hinweisen, dass der Schrägstrich den Pfad in hierarchische Teile unterteilt und immer im Inneren ist. Grundsätzlich ist nicht ausgeschlossen, dass das letzte Element von hsegment ein leerer String sein kann (dies folgt aus seiner Definition) und dann unabsichtlich ein schließender Schrägstrich am Ende der URL erscheint.
Fazit
Das Unterteilen eines Pfads in Segmente mit einem Schrägstrich impliziert das Vorhandensein nicht leerer Namen dieser Segmente. Dementsprechend erscheint ein Link mit einem Schrägstrich am Ende unlogisch (obwohl nicht verboten) in dem Sinne, dass er auf ein letztes Segment des Pfads zu verweisen scheint, dieses Segment aber in keiner Weise benennt. So wie der Link unlogisch (aber auch nicht verboten) ist http://domain.com/level1////levelX, die Zwischenpfadsegmente nicht benennt, wenn der Pfad nicht als Parametersatz, sondern als hierarchische Struktur betrachtet wird.
Umgangssprachlich lässt sich der semantische Inhalt der beiden Links wie folgt erklären:
- - Adressen zum Standardstartpunkt der zweiten Ebene der Hierarchie
- - adressiert an einen undefinierten Punkt innerhalb der zweiten Hierarchieebene, d.h. als würde dem Server die Aufgabe übertragen, dass "wir uns auf die zweite Hierarchieebene beziehen, und Sie selbst bestimmen, welchen Punkt Sie als Standard betrachten erste in diesem Level."
Aus alledem folgt, was ähnlich wie Links ist
- http://domain.com
- http://domain.com/
Adressieren Sie den Besucher zum Stammverzeichnis der Website und zum Beispiel zu Links
- http://domain.com/level1/level2
- http://domain.com/level1/level2/
adressieren Sie den Besucher auf der zweiten Ebene der Ressourcenhierarchie. Und dass ein bestimmter Server den Schrägstrich am Ende auf seine eigene Weise interpretieren und intern auf den Standard-Startpunkt des Levels umleiten kann - etwa auf die Datei index.html - ist schon ein Sonderfall einer bestimmten Konfiguration. Genau wie bei der Implementierung des menschenlesbaren URL-Systems definieren alle Umleitungseinträge, die das mod_rewrite-Servermodul verwenden, ihr eigenes (einer bestimmten Engine innewohnendes) Konzept der hierarchischen Struktur der URL, in der Pfadelemente mit Abfrageparametern gleichgesetzt werden können und nichts damit zu tun haben Dateistruktur Website (klassisches Beispiel: http://domain.com/ru/path , das Element ru ist ein Parameter der aktuellen Sprache, kein Ordner auf der Website).
Ich betone, dass dies das interne Wissen des Servers aufgrund seiner Konfiguration sowie der auf der Site installierten Engine ist. Ein externer Dienst, beispielsweise dieselbe Suchmaschine, kann keine Vermutungen anstellen und hat keine Ahnung, ob und wie sich Links mit und ohne Schrägstrich unterscheiden, es sei denn, der Site-Server ist speziell so konfiguriert, dass auf solchen Links unterschiedliche Inhalte angezeigt werden.
Notiz
Auf der Implementierungsebene ist das Problem der Schrägstriche am Ende nicht von grundlegender Bedeutung, was von vielen namhaften Portalen bestätigt wird. Bei manchen enden alle Links mit einem Schrägstrich, bei anderen ohne Schrägstrich. Die Hauptsache ist, dass sich der Inhalt der Links nicht als unterschiedlich herausstellt, und für Yandex müssen Sie auch eine 301-Weiterleitung von den Links registrieren, die Sie nicht verwenden (z. B. mit einem Schrägstrich enden), zu den von Ihnen verwendeten Links . Tatsache ist, dass diese Suchmaschine nach unbestätigten Behauptungen des Yandex-Supportdienstes angeblich Fehler machen und keine Schrägstrich-ohne-Schrägstrich-Adressen in eine Adressen "kleben" (einprägen) oder mit einiger Verzögerung in eine kleben kann.

Hier ist ein Beispiel für die Implementierung einer solchen Weiterleitung mithilfe der .htaccess-Stammdatei:
# wenn die Eingabe-URL mit einem Schrägstrich (em, ami) endet, # die 301. Weiterleitung auf die Seite ohne Schrägstrich setzen RewriteCond %(REQUEST_URI) ^/.+/$ RewriteRule ^(.*?)/+$ http:/ /%(HTTP_HOST)/$1
Google (wiederum nach nicht experimentell bestätigten Informationen) sind diese Weiterleitungen nicht wichtig, da es angeblich weiß, wie man solche Adressen korrekt und ohne Weiterleitungen einfügt.
Denken Sie daran Es gibt viele Menschen, die sich als SEO-Spezialisten bezeichnen. Aber nicht alle sind so. Zudem wird über das Thema SEO oft ohne entsprechende Kenntnisse und Vernunft spekuliert, einfach in der Erwartung, dass man auch auf diesem Gebiet unwissend ist, so dass man leicht irgendwelchen „Nudeln“ glauben kann. Wenn Ihnen mitgeteilt wird, dass einige Ihrer Seiten "aus dem Index gefallen sind", verwenden Sie die sehr gute Empfehlung von Yandex: Über eventuelle Indexierungsfehler können Sie sich im Yandex.Webmaster-Dienst informieren. In diesem Dienst können Sie immer eine Liste Ihrer Seiten in der Suche und eine Liste der Seiten sehen, die aus irgendeinem Grund von der Suche ausgeschlossen wurden. Google hat einen ähnlichen Dienst. Vertrauen Sie diesem Wissen und nicht der Meinung von Pseudo-Spezialisten, die irgendwo aus dem Ohr etwas gehört haben und Ihnen auf dieser Grundlage empfehlen, das zu tun, was sie für das einzig Richtige halten.
Hier Ein sehr interessanter Beitrag, Little Known SEO Facts, veröffentlicht im April 2017. Es gibt eine große Studie mit vielen Screenshots, die mit dem Ziel begann, einige populäre Urteile im Bereich der Suchmaschinenwerbung auf ihre Gültigkeit zu testen und die Ergebnisse dem durchschnittlichen Seitenbetreiber anhand verständlicher Beispiele zu vermitteln. Dieselbe Studie demonstriert dem jungen Leser ganz nebenbei eine Reihe offensichtlicher, profaner und eher unscheinbarer, aber dennoch überraschender Merkmale organischer Suchergebnisse Google-Suchen und Jandex.
Hier Auch wenn der folgende Link wenig mit SEO zu tun hat, wird er dennoch attraktiv für SEO-Meister sein, die jetzt nach zusätzlichen Aufträgen suchen. Unter dem Link ist ein kommerzielles Angebot platziert, die Jungs haben eine interessante Möglichkeit gefunden, die Seite zu nutzen. Privatunternehmen wird angeboten, eine Online-Plakatwand zu einem bestimmten Thema zu erstellen, unter deren Kontrolle die Website oder besser gesagt ihr erster Bildschirm wie eine Bannerstrecke auf Außenwerbetafeln aussieht. Auf dem Smartphone drehte ich den Bildschirm, die Dehnung wurde vertikal und nahm die gesamte Bildschirmfläche ein, drehte mich zurück, wurde horizontal und wieder Vollbild. Und unter dem ersten Bildschirm befindet sich ein Textanhang, wo Benutzer normalerweise nicht scrollen, aber die Suchmaschine sieht diesen Text gut. So kaufen die smartesten Pinocchios der regionalen Wirtschaft diese preiswerten Online-Werbetafeln als gewinnbringende Alternative kontextbezogene Werbung und das Yandex- und Google-Display-Netzwerk. Und um das Beste aus dem Abhängen im Lokal zu machen Suchindex, um ihren Schild zu fördern, sind sie bereit, sofort Geld für einen Haufen SEO-Texte zu steppen, was nach einer nicht sauren Menge riecht. Den Gerüchten nach zu urteilen, rutschen Bestellungen für 30 Kilo Rubel durch, und da die Jungs ihre Partner an SEOs auslagern, können Sie hier Partnerschaftsbrücken bauen und gute Einnahmen erzielen.
: Ich wollte das immer verstehen, aber seine Bedeutung war so gering, dass es immer einen Grund gab, es nicht zu tun :)
Und Sie haben sich gefragt: URL - was ist das?
Ich stoße immer wieder darauf, aber ich wollte den Unterschied zwischen den Begriffen URI, URL, URN, und dann plötzlich einem Post (leider schon in Vergessenheit geraten) trotzdem nicht verstehen, entschied ich – ich lese es selbst, und erzähle anderen, obwohl sich, wie oben erwähnt, nichts daran ändern wird, aber ich buchstabiere manchmal gerne, also lese den vernünftigen Übersetzer:
Haben Sie schon einmal auf die Adressleiste in Ihrem Browser geachtet? Was ist das? URI, URL oder URN? Viele von uns unterscheiden nicht zwischen URI, URL, URN, und einige von uns haben noch nie von den Begriffen URI und URN gehört, alle verwenden nur den Begriff URL. Versuchen wir das gemeinsam herauszufinden.
Erklärung der Abkürzungen
URI - Uniform Resource Identifier (uniform Kennung Ressource)
URL - Uniform Resource Locator (unified Standortfinder Ressource)
URN - Einheitlicher Ressourcenname (uniform Name Ressource)
Achtung, hier liegt die Wahrheit in den kleinen Dingen, aber bisher ist nichts klar, irgendein Durcheinander. Gehen wir weiter.
Definition
URI: Gibt den Namen und die Adresse einer Ressource im Web an. Generell unterteilt in URL und URN, also sind URL und URN die Bestandteile einer URI.
URL: Die Adresse einer Ressource im Web. Die URL definiert den Speicherort der Ressource und den Zugriff darauf.
URN: Der Name einer Ressource im Web. Der Sinn einer URN besteht darin, dass sie nur den Namen eines bestimmten Elements definiert, das an mehreren bestimmten Stellen zu finden ist.
Es gibt nichts Besseres als ein konkretes Beispiel
URI = http://site/2009/09/uri-url-urn.html
URL = http://site
URL=/2009/09/uri-url-urn.html
Zusammenfassen
URI ist das Konzept eines abstrakten Bezeichners, während URL und URN konkrete Implementierungen von Adressen und Namen sind.
Ich hoffe es ist allen klar. Seien Sie clever!
Die Wahrnehmung eines jeden von uns ist daher individuell - argumentieren und lesen Sie die Diskussionen in den Kommentaren zum Artikel, es gibt viele interessante Dinge.