Il metodo della forza bruta è un approccio diretto alla risoluzione
problema, di solito basato direttamente sull'affermazione del problema e sulle definizioni dei concetti che utilizza.
Un algoritmo di forza bruta per risolvere un problema di ricerca generale è chiamato ricerca sequenziale. Questo algoritmo confronta semplicemente gli elementi di un dato elenco con la chiave di ricerca a turno fino a quando non viene trovato un elemento con il valore della chiave specificato (ricerca riuscita) o viene esaminato l'intero elenco ma l'elemento richiesto non viene trovato (ricerca non riuscita). Spesso viene utilizzato un semplice trucco aggiuntivo: se aggiungi la chiave di ricerca alla fine dell'elenco, la ricerca andrà sicuramente a buon fine, quindi puoi rimuovere il controllo di completamento dell'elenco in ogni iterazione dell'algoritmo. Quello che segue è lo pseudocodice di tale versione migliorata; si presume che i dati di input siano sotto forma di un array.
Se l'elenco originale è ordinato, è possibile utilizzare un ulteriore miglioramento: la ricerca in tale elenco può essere interrotta non appena si incontra un elemento che non sia inferiore alla chiave di ricerca. La ricerca sequenziale fornisce un'eccellente illustrazione dell'approccio della forza bruta, con i suoi caratteristici punti di forza (semplicità) e di debolezza (bassa efficienza).
È abbastanza ovvio che il tempo di esecuzione di questo algoritmo può variare ampiamente per lo stesso elenco di dimensione n. Nel peggiore dei casi, ad es. quando l'elenco non contiene l'elemento desiderato o quando l'elemento si trova per ultimo nell'elenco, l'algoritmo eseguirà il maggior numero di operazioni di confronto di chiavi con tutti gli n elementi dell'elenco: C(n) = n.
1.2. L'algoritmo di Rabin.
L'algoritmo di Rabin è una modifica dell'algoritmo lineare, si basa su un'idea molto semplice:
“Immagina che nella parola A, la cui lunghezza è m, cerchiamo un pattern X di lunghezza n. Ritagliamo una "finestra" di dimensione n e la spostiamo lungo la parola di input. Ci interessa sapere se la parola nella "scatola" corrisponde al modello dato. Confrontando le lettere per molto tempo. Invece, fissiamo qualche funzione numerica su parole di lunghezza n, quindi il problema si ridurrà al confronto dei numeri, che è senza dubbio più veloce. Se i valori di questa funzione sulla parola nella "finestra" e sul campione sono diversi, non c'è corrispondenza. Solo se i valori sono gli stessi, è necessario verificare successivamente la corrispondenza lettera per lettera.
Questo algoritmo esegue un passaggio lineare attraverso la linea (n passaggi) e un passaggio lineare attraverso l'intero testo (m passaggi), quindi il tempo di esecuzione totale è O(n+m). Allo stesso tempo, non prendiamo in considerazione la complessità temporale del calcolo della funzione hash, poiché l'essenza dell'algoritmo è che questa funzione è così facilmente calcolabile che il suo funzionamento non influisce sul funzionamento complessivo dell'algoritmo.
L'algoritmo di Rabin e l'algoritmo di ricerca sequenziale sono algoritmi con il minor costo di manodopera, quindi sono adatti per l'uso nella risoluzione di una certa classe di problemi. Tuttavia, questi algoritmi non sono i più ottimali.
1.3. Algoritmo di Knuth-Morris-Pratt (kmp).
Il metodo KMP utilizza la preelaborazione della stringa richiesta, ovvero: sulla sua base viene creata una funzione di prefisso. In questo caso, viene utilizzata la seguente idea: se il prefisso (aka suffisso) di una stringa di lunghezza i è più lungo di un carattere, allora è anche il prefisso di una sottostringa di lunghezza i-1. Pertanto, controlliamo il prefisso della sottostringa precedente, se non corrisponde, il prefisso del suo prefisso e così via. In questo modo, troviamo il prefisso desiderato più grande. La prossima domanda a cui rispondere è: perché il tempo di esecuzione della procedura è lineare, perché ha un ciclo annidato? Ebbene, in primo luogo, l'assegnazione della funzione di prefisso avviene esattamente m volte, il resto delle volte la variabile k cambia. Pertanto, il tempo di esecuzione totale del programma è O(n+m), cioè tempo lineare.
e funzione successiva: function show(pos, path, w, h) ( var canvas = document.getElementById("canID"); // ottiene l'oggetto canvas var ctx = canvas.getContext("2d"); // ha una proprietà di contesto drawing var x0 = 10, y0 = 10; // la posizione dell'angolo in alto a sinistra della mappa canvas.width = w+2*x0; canvas.height = h+2*y0; // ridimensiona la tela (leggermente più grande di w x h) ctx .beginPath(); // inizia a disegnare una polilinea ctx.moveTo(x0+pos.x,y0+pos.y)// passa alla 0a città for(var i=1; i Un esempio di il risultato della chiamata di funzione è mostrato a destra.Il significato dei comandi di disegno dovrebbe essere chiaro dal loro nome e dai commenti nel codice.Prima viene disegnata una polilinea chiusa (percorso del commesso viaggiatore).Quindi i cerchi delle città e sopra loro i numeri delle città. Lavorare con un fossato in JavaScript è alquanto macchinoso e in futuro useremo la classe disegno, che semplifica questo lavoro e allo stesso tempo ti consente di ottenere immagini in formato svg.
Busto nel timer
L'implementazione dell'algoritmo di ricerca per trovare il percorso più breve nel timer non è difficile. Per memorizzare il percorso migliore in un array minWay, scrivi una funzione per copiare i valori degli elementi dell'array src in una matrice des:
Funzione copy(des, src) ( if(des.length !== src.length) des = new Array(src.length); for(var i=0; i
Ho un problema di matematica che risolvo per tentativi ed errori (penso che si chiami forza bruta) e il programma funziona bene quando sono presenti più parametri, ma man mano che vengono aggiunte più variabili/dati, l'esecuzione richiede sempre più tempo.
Il mio problema è che mentre il prototipo funziona, è utile per migliaia di variabili e grandi set di dati; quindi, mi chiedo se gli algoritmi di forza bruta possono essere ridimensionati. Come posso avvicinarmi al ridimensionamento?
3 risposte
In generale, è possibile quantificare la scalabilità di un algoritmo utilizzando una notazione di output di grandi dimensioni per analizzare il suo tasso di crescita. Quando dici che il tuo algoritmo è in esecuzione sotto "forza bruta", non è chiaro fino a che punto si ridimensionerà. Se la tua soluzione di "forza bruta" funziona elencando tutti i possibili sottoinsiemi o combinazioni del set di dati, quasi sicuramente non sarà ridimensionata (avrà una complessità asintotica di O(2n) o O(n!), rispettivamente). Se la tua soluzione di forza bruta funziona trovando tutte le coppie di elementi e testandole, può scalare abbastanza bene (O(n 2)). Tuttavia, senza Informazioni aggiuntive come funziona il tuo algoritmo è difficile da dire.
Per definizione, gli algoritmi di forza bruta sono stupidi. Starai molto meglio con un algoritmo più intelligente (se ne hai uno). Un algoritmo migliore ridurrà il lavoro che deve essere svolto, si spera nella misura in cui puoi farlo senza richiedere il "ridimensionamento" su più macchine.
Indipendentemente dall'algoritmo, arriva un punto in cui la quantità di dati o la potenza di elaborazione richiesta è così grande che è necessario utilizzare qualcosa come Hadoop. Ma in generale, stiamo davvero parlando di big data qui. Al giorno d'oggi puoi già fare molto con un PC.
L'algoritmo per risolvere questo problema è chiuso al processo che studiamo per la divisione matematica manuale, così come per la conversione da decimale a un'altra base, come ottale o esadecimale, tranne per il fatto che nei due esempi viene considerata una sola soluzione canonica.
Per assicurarsi che la ricorsione venga completata, è importante ordinare l'array di dati. Per essere efficienti e limitare il numero di ricorsioni, è anche importante iniziare con valori di dati più elevati.
Concretamente, ecco l'implementazione ricorsiva di Java per questo problema, con una copia del vettore del risultato coeff per ogni ricorsione, come previsto in teoria.
Importa java.util.Array; public class Risolutore ( public static void main(String args) ( int target_sum = 100; // prerequisito: valori ordinati !! int data = new int ( 5, 10, 20, 25, 40, 50 ); / / vettore risultato, da init a 0 int coeff = new int; Arrays.fill(coeff, 0); partialSum(data.length - 1, target_sum, coeff, data); ) private static void printResult(int coeff, int data) ( for ( int i = lunghezza coeff. - 1; i >= 0; i--) ( if (coeff[i] > 0) ( System.out.print(data[i] + " * " + coeff[i] + " "); ) ) System.out.println(); ) private static void parzialeSum(int k, int sum, int coeff, int data) ( int x_k = data[k]; for (int c = sum / x_k ; c >= 0; c--) ( coeff[k] = c; if (c * x_k == sum) ( printResult(coeff, data); continue; ) else if (k > 0) ( // risultato contestuale in parameters , local to method scope int newcoeff = Arrays.copyOf(coeff, coeff.length); partialSum(k - 1, sum - c * x_k, newcoeff, data); // ciclo for su "c" continua con precedente contenuto coeff ) ) ) )
Ma ora questo codice è in un caso speciale: ultimo esame il valore per ciascun coefficiente è 0, quindi non è necessaria alcuna copia.
Come stima della complessità, possiamo utilizzare la profondità massima delle chiamate ricorsive come data.length * min(( data )) . Ovviamente non si ridimensiona bene e la memoria di traccia dello stack (opzione -Xss JVM) sarà il fattore limitante. Il codice potrebbe non riuscire con un errore per un set di dati di grandi dimensioni.
Per evitare queste carenze, il processo di "terminazione" è utile. Consiste nel sostituire lo stack di chiamate del metodo con uno stack di programma per memorizzare il contesto di esecuzione per un'elaborazione successiva. Ecco il codice per questo:
Importa java.util.Array; importare java.util.ArrayDeque; importare java.util.Coda; public class NonRecursive ( // prerequisito: valori ordinati!! private static final int data = new int ( 5, 10, 20, 25, 40, 50 ); // Contesto per memorizzare il calcolo intermedio o una classe statica della soluzione Context ( int k; int sum; int coeff; Context(int k, int sum, int coeff) ( this.k = k; this.sum = sum; this.coeff = coeff; ) ) private static void printResult(int coeff ) ( for (int i = coeff.lunghezza - 1; i >= 0; i--) ( if (coeff[i] > 0) ( System.out.print(data[i] + " * " + coeff[ i] + " "); ) ) System.out.println(); ) public static void main(String args) ( int target_sum = 100; // vettore risultato, init to 0 int coeff = new int; Arrays.fill( coeff, 0); // coda con i contesti per elaborare la coda
Dal mio punto di vista, è difficile essere più efficienti in una singola esecuzione di un thread: il meccanismo dello stack ora richiede copie dell'array coeff.
La ricerca di una sottostringa in una stringa viene eseguita secondo un determinato schema, ad es. una sequenza di caratteri la cui lunghezza non supera la lunghezza della stringa originale. Il compito della ricerca è determinare se una stringa contiene un determinato modello e indicare la posizione (indice) nella stringa se viene trovata una corrispondenza.
L'algoritmo della forza bruta è il più semplice e lento e consiste nel controllare tutte le posizioni del testo per vedere se corrispondono all'inizio del pattern. Se l'inizio del pattern corrisponde, la lettera successiva nel pattern e nel testo viene confrontata, e così via, con la risposta più semplice e lenta, indipendentemente dal fatto che esista o meno un tale elemento senza specificare l'indice è già ordinato per non una corrispondenza completa del modello o una differenza nella lettera successiva.
int BFSearch(char*s, char*p)
for (int i = 1; strlen(s) - strlen(p); i++)
for (int j = 1; strlen(p); j++)
se (p[j] != s)
se (j = strlen(p))
La funzione BFSearch cerca la sottostringa p nella stringa se restituisce l'indice del primo carattere della sottostringa oppure 0 se la sottostringa non viene trovata. Sebbene in generale questo metodo, come la maggior parte dei metodi di forza bruta, sia inefficace, in alcune situazioni è abbastanza accettabile.
Il più veloce tra gli algoritmi scopo generale, progettato per cercare una sottostringa in una stringa, è l'algoritmo Boyer-Moore, sviluppato da due scienziati: Boyer (Robert S. Boyer) e Moore (J. Strother Moore), la cui essenza è la seguente.
Algoritmo Boyer-Moore
La versione più semplice dell'algoritmo Boyer-Moore consiste nei seguenti passaggi. Nella prima fase, viene costruita una tabella degli spostamenti per il campione desiderato. Il processo di costruzione della tabella sarà descritto di seguito. Successivamente, l'inizio della stringa e il pattern vengono combinati e il test inizia dall'ultimo carattere del pattern. Se l'ultimo carattere del pattern e il carattere della stringa ad esso corrispondente, quando sovrapposti, non corrispondono, il pattern viene spostato rispetto alla stringa del valore ottenuto dalla tabella di offset e il confronto viene eseguito nuovamente, a partire da l'ultimo carattere del pattern. Se i caratteri corrispondono, viene confrontato il penultimo carattere del modello e così via. Se tutti i caratteri del campione corrispondono ai caratteri sovrapposti della stringa, la sottostringa è stata trovata e la ricerca è terminata. Se qualche carattere (non l'ultimo) del pattern non corrisponde al carattere corrispondente della stringa, spostiamo il pattern di un carattere a destra e ricominciamo dall'ultimo carattere. L'intero algoritmo viene eseguito fino a quando non viene trovata un'occorrenza del modello desiderato o viene raggiunta la fine della stringa.
Il valore di spostamento in caso di mancata corrispondenza dell'ultimo carattere viene calcolato secondo la regola: lo spostamento del pattern deve essere minimo, per non perdere l'occorrenza del pattern nella stringa. Se il carattere stringa specificato è presente nel modello, il modello viene spostato in modo che il carattere stringa corrisponda all'occorrenza più a destra di quel carattere nel modello. Se il modello non contiene affatto questo carattere, il modello viene spostato di un importo pari alla sua lunghezza, in modo che il primo carattere del modello venga sovrapposto al carattere successivo della stringa che è stata testata.
Il valore di offset per ogni carattere del pattern dipende solo dall'ordine dei caratteri nel pattern, quindi è conveniente calcolare gli offset in anticipo e memorizzarli come un array unidimensionale, dove ogni carattere dell'alfabeto corrisponde a un offset relativo all'ultimo carattere del motivo. Spieghiamo tutto quanto sopra semplice esempio. Lascia che ci sia un insieme di cinque caratteri: a, b, c, d, e e devi trovare un'occorrenza del modello "abbad" nella stringa "abeccacbadbabbad". I seguenti diagrammi illustrano tutte le fasi dell'esecuzione dell'algoritmo:
Tavola offset per il pattern “abbad”.
Inizio ricerca. L'ultimo carattere del modello non corrisponde al carattere stringa sovrapposto. Sposta il campione a destra di 5 posizioni:
Tre caratteri del modello corrispondevano, ma il quarto no. Sposta il motivo a destra di una posizione:
L'ultimo carattere di nuovo non corrisponde al carattere stringa. In accordo con la tabella degli spostamenti, spostiamo il campione di 2 posizioni:
Ancora una volta, spostiamo il campione di 2 posizioni:
Ora, secondo la tabella, spostiamo il campione di una posizione e otteniamo l'occorrenza desiderata del campione:
Implementiamo l'algoritmo specificato. Innanzitutto è necessario definire il tipo di dati "tabella offset". Per una tabella di codici di 256 caratteri, la definizione della struttura sarebbe simile a questa:
BMTable MakeBMTable(carattere *p)
per (i = 0; io<= 255; i++) bmt->bmtarr[i] = strlen(p);
per (i = strlen(p); i<= 1; i--)
se (bmt->bmtarr] == strlen(p))
bmt->bmtarr] = strlen(p)-i;
Ora scriviamo una funzione che esegua la ricerca.
int BMSearch(int startpos, char *s, char *p)
pos = startpos + lp - 1;
mentre (pos< strlen(s))
if (p != s) pos = pos + bmt->bmtarr];
per (i = lp - 1; i<= 1; i--)
se (p[i] != s)
ritorno(pos - lp + 1);
La funzione BMSearch restituisce la posizione del primo carattere della prima occorrenza del pattern p nella stringa s. Se la sequenza p in s non viene trovata, la funzione restituisce 0. Il parametro startpos consente di specificare la posizione nella stringa s da cui iniziare la ricerca. Questo può essere utile se vuoi trovare tutte le occorrenze di p in s. Per cercare dall'inizio della stringa, impostare startpos su 1. Se il risultato della ricerca è diverso da zero, per trovare l'occorrenza successiva di p in s, impostare startpos su "il risultato precedente più la lunghezza del pattern".
Ricerca binaria (binaria).
La ricerca binaria viene utilizzata quando l'array ricercato è già ordinato.
Le variabili lb e ub contengono, rispettivamente, i limiti sinistro e destro del segmento dell'array in cui si trova l'elemento desiderato. La ricerca inizia sempre con lo studio dell'elemento centrale del segmento. Se il valore desiderato è inferiore all'elemento centrale, è necessario passare alla ricerca nella metà superiore del segmento, dove tutti gli elementi sono inferiori a quello appena selezionato. In altre parole, il valore di ub diventa (m - 1) e metà dell'array originale viene controllata nell'iterazione successiva. Pertanto, a seguito di ogni controllo, l'area di ricerca viene dimezzata. Ad esempio, se nell'array sono presenti 100 numeri, dopo la prima iterazione l'area di ricerca viene ridotta a 50 numeri, dopo il secondo - a 25, dopo il terzo a 13, dopo il quarto a 7, ecc. Se la lunghezza dell'array è n, allora log 2 n confronti sono sufficienti per cercare gli elementi nell'array.
Metodi di sviluppo dell'algoritmo n Metodo della forza bruta ("di petto") n Metodo di decomposizione n Metodo di riduzione della dimensione del problema n Metodo di trasformazione n Programmazione dinamica n Metodi avidi n Metodi di riduzione della ricerca n … © Pavlovskaya T. A. (SPb NRU ITMO) 1

 Approccio a forza bruta n Un approccio diretto alla risoluzione di un problema, di solito basato direttamente sull'affermazione del problema e sulle definizioni dei concetti da essa utilizzati facile da usare n Raramente produce algoritmi belli ed efficienti n Il costo dello sviluppo di un algoritmo più efficiente può essere inaccettabile se devono essere risolte solo poche istanze di problemi n Può essere utile per risolvere piccole istanze di problemi. n Può servire come misura per determinare l'efficacia di altri algoritmi © Pavlovskaya T. A. (SPb NRU ITMO) 3
Approccio a forza bruta n Un approccio diretto alla risoluzione di un problema, di solito basato direttamente sull'affermazione del problema e sulle definizioni dei concetti da essa utilizzati facile da usare n Raramente produce algoritmi belli ed efficienti n Il costo dello sviluppo di un algoritmo più efficiente può essere inaccettabile se devono essere risolte solo poche istanze di problemi n Può essere utile per risolvere piccole istanze di problemi. n Può servire come misura per determinare l'efficacia di altri algoritmi © Pavlovskaya T. A. (SPb NRU ITMO) 3
 n Esempio: ordinamento per selezione e ordinamento a bolle 28 -5 ©Pavlovskaya T. A. (NRU ITMO di San Pietroburgo) 16 0 29 3 -4 56 4
n Esempio: ordinamento per selezione e ordinamento a bolle 28 -5 ©Pavlovskaya T. A. (NRU ITMO di San Pietroburgo) 16 0 29 3 -4 56 4
 L'enumerazione esaustiva è un approccio di forza bruta ai problemi combinatori. Presuppone: n generazione di tutti gli elementi possibili dall'area di definizione del problema n selezione di quelli che soddisfano i vincoli imposti dalla condizione problematica n ricerca dell'elemento desiderato (ad esempio, ottimizzando il valore della funzione obiettivo del problema). Esempi: Il problema del commesso viaggiatore: trova il percorso più breve attraverso Considera tutti i sottoinsiemi dato insieme su n oggetti dati a N città, in modo che ogni città sia visitata, calcola solo il peso totale di ciascuna di esse per determinarne l'ammissibilità, una volta e la destinazione finale è quella originaria. scegliere dal sottoinsieme consentito con il peso massimo. n Ottenere tutti i percorsi possibili, generando tutti i problemi dello Zaino: dati N elementi di peso e costo dati uno zaino in grado di supportare il peso W. Caricare uno zaino di permutazioni di n - 1 città intermedie, calcolando con il costo massimo. la lunghezza dei percorsi corrispondenti e trovare il più breve di essi. Questi sono problemi NP-difficili (nessun algoritmo è noto per risolverli in tempo polinomiale). n © Pavlovskaya T. A. (SPb NRU ITMO) 5
L'enumerazione esaustiva è un approccio di forza bruta ai problemi combinatori. Presuppone: n generazione di tutti gli elementi possibili dall'area di definizione del problema n selezione di quelli che soddisfano i vincoli imposti dalla condizione problematica n ricerca dell'elemento desiderato (ad esempio, ottimizzando il valore della funzione obiettivo del problema). Esempi: Il problema del commesso viaggiatore: trova il percorso più breve attraverso Considera tutti i sottoinsiemi dato insieme su n oggetti dati a N città, in modo che ogni città sia visitata, calcola solo il peso totale di ciascuna di esse per determinarne l'ammissibilità, una volta e la destinazione finale è quella originaria. scegliere dal sottoinsieme consentito con il peso massimo. n Ottenere tutti i percorsi possibili, generando tutti i problemi dello Zaino: dati N elementi di peso e costo dati uno zaino in grado di supportare il peso W. Caricare uno zaino di permutazioni di n - 1 città intermedie, calcolando con il costo massimo. la lunghezza dei percorsi corrispondenti e trovare il più breve di essi. Questi sono problemi NP-difficili (nessun algoritmo è noto per risolverli in tempo polinomiale). n © Pavlovskaya T. A. (SPb NRU ITMO) 5

 Metodo di scomposizione Conosciuto anche come divide et impera: n Un'istanza dell'attività è suddivisa in diverse istanze più piccole della stessa attività, idealmente della stessa dimensione. n Le istanze più piccole del problema vengono risolte (di solito in modo ricorsivo, sebbene a volte venga utilizzato qualche altro algoritmo per le istanze piccole). n Se necessario, la soluzione al problema originale si trova combinando soluzioni di istanze più piccole. Il metodo di scomposizione è ideale per il calcolo parallelo. © Pavlovskaya T.A. (SPb NRU ITMO) 7
Metodo di scomposizione Conosciuto anche come divide et impera: n Un'istanza dell'attività è suddivisa in diverse istanze più piccole della stessa attività, idealmente della stessa dimensione. n Le istanze più piccole del problema vengono risolte (di solito in modo ricorsivo, sebbene a volte venga utilizzato qualche altro algoritmo per le istanze piccole). n Se necessario, la soluzione al problema originale si trova combinando soluzioni di istanze più piccole. Il metodo di scomposizione è ideale per il calcolo parallelo. © Pavlovskaya T.A. (SPb NRU ITMO) 7
 Equazione di decomposizione ricorsiva n Nel caso generale, un'istanza di un problema di dimensione n può essere suddivisa in più istanze di dimensione n/b, e di cui è necessario risolvere. n Equazione di decomposizione ricorsiva generalizzata: (1) n Per semplicità, si assume che la dimensione di n sia uguale alla potenza di b. n L'ordine di crescita dipende da a, b e f. © Pavlovskaya T.A. (SPb NRU ITMO) 8
Equazione di decomposizione ricorsiva n Nel caso generale, un'istanza di un problema di dimensione n può essere suddivisa in più istanze di dimensione n/b, e di cui è necessario risolvere. n Equazione di decomposizione ricorsiva generalizzata: (1) n Per semplicità, si assume che la dimensione di n sia uguale alla potenza di b. n L'ordine di crescita dipende da a, b e f. © Pavlovskaya T.A. (SPb NRU ITMO) 8
 Il principale teorema di decomposizione (1) n Si può specificare la classe di efficienza dell'algoritmo senza risolvere l'equazione ricorsiva stessa. n Questo approccio permette di stabilire l'ordine di crescita della soluzione senza determinare le incognite. © Pavlovskaya T.A. (San Pietroburgo NRU ITMO) 9
Il principale teorema di decomposizione (1) n Si può specificare la classe di efficienza dell'algoritmo senza risolvere l'equazione ricorsiva stessa. n Questo approccio permette di stabilire l'ordine di crescita della soluzione senza determinare le incognite. © Pavlovskaya T.A. (San Pietroburgo NRU ITMO) 9
 Mergesort Ordina l'array specificato suddividendolo in due metà, ordinando ciascuna metà in modo ricorsivo e unendo le due metà ordinate in un array ordinato: Mergesort (A) se n>1 Prima metà A -> nell'array B Seconda metà A -> in array C Mergesort(B) Mergesort(C) Merge(B, C, A) // unione ©Pavlovskaya T. A. (NRU ITMO di San Pietroburgo) 10
Mergesort Ordina l'array specificato suddividendolo in due metà, ordinando ciascuna metà in modo ricorsivo e unendo le due metà ordinate in un array ordinato: Mergesort (A) se n>1 Prima metà A -> nell'array B Seconda metà A -> in array C Mergesort(B) Mergesort(C) Merge(B, C, A) // unione ©Pavlovskaya T. A. (NRU ITMO di San Pietroburgo) 10
Src="http://present5.com/presentation/54441564_438337950/image-11.jpg" alt="(!LANG:Mergesort (A) if n>1 Prima metà di A -> all'array B Seconda metà di A"> Mergesort (A) if n>1 Первая половина А -> в массив В Вторая половина А > в массив С Mergesort(B) Mergesort(C) Меrgе(В, С, А) ©Павловская Т. А. (СПб НИУ ИТМО) 11!}
 Unione di array n Due indici di array dopo l'inizializzazione puntano ai primi elementi degli array da unire. n Gli elementi vengono confrontati e quello più piccolo viene aggiunto al nuovo array. n Viene incrementato l'indice dell'elemento più piccolo (punta all'elemento immediatamente successivo a quello appena copiato). Questa operazione viene ripetuta fino all'esaurimento di uno degli array da unire. Gli elementi rimanenti della seconda matrice vengono aggiunti alla fine della nuova matrice. © Pavlovskaya T.A. (SPb NRU ITMO) 12
Unione di array n Due indici di array dopo l'inizializzazione puntano ai primi elementi degli array da unire. n Gli elementi vengono confrontati e quello più piccolo viene aggiunto al nuovo array. n Viene incrementato l'indice dell'elemento più piccolo (punta all'elemento immediatamente successivo a quello appena copiato). Questa operazione viene ripetuta fino all'esaurimento di uno degli array da unire. Gli elementi rimanenti della seconda matrice vengono aggiunti alla fine della nuova matrice. © Pavlovskaya T.A. (SPb NRU ITMO) 12
 Merge sort analysis n Lascia che la lunghezza del file sia una potenza di 2. n Numero di confronti tra chiavi: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 caso peggiore (numero di confronti di chiavi di unione) n caso peggiore Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n-1 Cw (n ) (n log n) – secondo il main Teorema © Pavlovskaya T. A. (SPb NRU ITMO) (1) 13
Merge sort analysis n Lascia che la lunghezza del file sia una potenza di 2. n Numero di confronti tra chiavi: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 caso peggiore (numero di confronti di chiavi di unione) n caso peggiore Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n-1 Cw (n ) (n log n) – secondo il main Teorema © Pavlovskaya T. A. (SPb NRU ITMO) (1) 13
 n Il numero di confronti chiave eseguiti da merge sort è nel peggiore dei casi molto vicino al numero minimo teorico di confronti per qualsiasi algoritmo di ordinamento basato sul confronto. n Lo svantaggio principale del merge sort è la necessità di memoria aggiuntiva, la cui quantità è linearmente proporzionale alla dimensione dei dati di input. © Pavlovskaya T.A. (SPb NRU ITMO) 14
n Il numero di confronti chiave eseguiti da merge sort è nel peggiore dei casi molto vicino al numero minimo teorico di confronti per qualsiasi algoritmo di ordinamento basato sul confronto. n Lo svantaggio principale del merge sort è la necessità di memoria aggiuntiva, la cui quantità è linearmente proporzionale alla dimensione dei dati di input. © Pavlovskaya T.A. (SPb NRU ITMO) 14
 Quicksort A differenza del mergesort, che separa gli elementi di un array in base alla loro posizione nell'array, quicksort separa gli elementi di un array in base ai loro valori. 28 56 © Pavlovskaya T. A. (San Pietroburgo NRU ITMO) 1 0 29 3 -4 16 15
Quicksort A differenza del mergesort, che separa gli elementi di un array in base alla loro posizione nell'array, quicksort separa gli elementi di un array in base ai loro valori. 28 56 © Pavlovskaya T. A. (San Pietroburgo NRU ITMO) 1 0 29 3 -4 16 15
 Descrizione dell'algoritmo n Selezionare un elemento pivot n Eseguire una permutazione di elementi per ottenere una partizione quando tutti gli elementi fino a una certa posizione s non superano l'elemento A [s] e gli elementi dopo la posizione s non sono inferiori a esso. n Ovviamente, dopo la divisione, A [s] è nella posizione finale e possiamo ordinare i due sottoarray di elementi prima e dopo A [s] indipendentemente (usando lo stesso metodo o un metodo diverso) © Pavlovskaya T. A. (SPb NRU ITMO) 16
Descrizione dell'algoritmo n Selezionare un elemento pivot n Eseguire una permutazione di elementi per ottenere una partizione quando tutti gli elementi fino a una certa posizione s non superano l'elemento A [s] e gli elementi dopo la posizione s non sono inferiori a esso. n Ovviamente, dopo la divisione, A [s] è nella posizione finale e possiamo ordinare i due sottoarray di elementi prima e dopo A [s] indipendentemente (usando lo stesso metodo o un metodo diverso) © Pavlovskaya T. A. (SPb NRU ITMO) 16
 La procedura di permutazione degli elementi n Metodo efficace, basato su due passaggi di sottoarray: da sinistra a destra e da destra a sinistra. Ad ogni passaggio, gli elementi vengono confrontati con il pivot. n Passaggio da sinistra a destra (i) salta gli elementi inferiori al pivot e si ferma al primo elemento non inferiore al pivot. n Passa da destra a sinistra (j) salta gli elementi maggiori di pivot e si ferma al primo elemento non maggiore di pivot. n Se gli indici di scansione non si intersecano, scambiamo gli elementi trovati e continuiamo i passaggi. n Se gli indici si intersecano, scambiamo l'elemento pivot con Aj ©Pavlovskaya T. A. (SPb NRU ITMO) 17
La procedura di permutazione degli elementi n Metodo efficace, basato su due passaggi di sottoarray: da sinistra a destra e da destra a sinistra. Ad ogni passaggio, gli elementi vengono confrontati con il pivot. n Passaggio da sinistra a destra (i) salta gli elementi inferiori al pivot e si ferma al primo elemento non inferiore al pivot. n Passa da destra a sinistra (j) salta gli elementi maggiori di pivot e si ferma al primo elemento non maggiore di pivot. n Se gli indici di scansione non si intersecano, scambiamo gli elementi trovati e continuiamo i passaggi. n Se gli indici si intersecano, scambiamo l'elemento pivot con Aj ©Pavlovskaya T. A. (SPb NRU ITMO) 17
 Efficienza di quicksort n Caso migliore: tutte le partizioni sono nel mezzo dei sottoarray corrispondenti n Caso peggiore, tutte le partizioni sono tali che uno dei sottoarray è vuoto e la dimensione del secondo è 1 inferiore alla dimensione dell'array da partizionato (dipendenza quadratica). n Nel caso medio, assumiamo che il partizionamento possa essere eseguito in ciascuna posizione con la stessa probabilità: Cavg 2 n ln n 1, 38 n log 2 n © Pavlovskaya T. A. (SPb NRU ITMO) 18
Efficienza di quicksort n Caso migliore: tutte le partizioni sono nel mezzo dei sottoarray corrispondenti n Caso peggiore, tutte le partizioni sono tali che uno dei sottoarray è vuoto e la dimensione del secondo è 1 inferiore alla dimensione dell'array da partizionato (dipendenza quadratica). n Nel caso medio, assumiamo che il partizionamento possa essere eseguito in ciascuna posizione con la stessa probabilità: Cavg 2 n ln n 1, 38 n log 2 n © Pavlovskaya T. A. (SPb NRU ITMO) 18
 Miglioramenti dell'algoritmo n metodi di selezione del pivot migliorati n passaggio a un ordinamento più semplice per sottoarray piccoli n rimozione della ricorsione Nel loro insieme, questi miglioramenti possono ridurre il tempo di esecuzione dell'algoritmo del 20-25% (R. Sedgwick) © Pavlovskaya T. A. (SPb NRU ITMO) 19
Miglioramenti dell'algoritmo n metodi di selezione del pivot migliorati n passaggio a un ordinamento più semplice per sottoarray piccoli n rimozione della ricorsione Nel loro insieme, questi miglioramenti possono ridurre il tempo di esecuzione dell'algoritmo del 20-25% (R. Sedgwick) © Pavlovskaya T. A. (SPb NRU ITMO) 19
 Binary tree traversal Questo è un altro esempio di utilizzo del metodo di scomposizione n Forward traversal visita prima la radice dell'albero, quindi i sottoalberi sinistro e destro. n In una traversata simmetrica, la radice viene visitata dopo il sottoalbero di sinistra ma prima di visitare la destra. n Quando si bypassa ordine inverso la radice viene visitata dopo i sottoalberi sinistro e destro. © Pavlovskaya T.A. (SPb NRU ITMO) 20
Binary tree traversal Questo è un altro esempio di utilizzo del metodo di scomposizione n Forward traversal visita prima la radice dell'albero, quindi i sottoalberi sinistro e destro. n In una traversata simmetrica, la radice viene visitata dopo il sottoalbero di sinistra ma prima di visitare la destra. n Quando si bypassa ordine inverso la radice viene visitata dopo i sottoalberi sinistro e destro. © Pavlovskaya T.A. (SPb NRU ITMO) 20
 Procedura di attraversamento dell'albero print_tree(tree); inizia print_tree(left_subtree) visita root print_tree(right_subtree) end; 1 6 8 10 20 ©Pavlovskaya T. A. (SPb. GU ITMO) 21 25 30 21
Procedura di attraversamento dell'albero print_tree(tree); inizia print_tree(left_subtree) visita root print_tree(right_subtree) end; 1 6 8 10 20 ©Pavlovskaya T. A. (SPb. GU ITMO) 21 25 30 21

 Metodo di riduzione della dimensione del problema Basato sull'utilizzo della relazione tra la soluzione di una data istanza del problema e la soluzione di un'istanza più piccola dello stesso problema. Una volta stabilita tale relazione, può essere utilizzata dall'alto verso il basso (ricorsivamente) o dal basso verso l'alto (nessuna ricorsione). (esempio: elevare un numero a potenza) Esistono tre varianti principali del metodo di riduzione dimensionale: n diminuzione di una quantità costante (solitamente di 1); n riduzione di un fattore costante (normalmente 2 volte); n riduzione di dimensione variabile. © Pavlovskaya T.A. (SPb NRU ITMO) 23
Metodo di riduzione della dimensione del problema Basato sull'utilizzo della relazione tra la soluzione di una data istanza del problema e la soluzione di un'istanza più piccola dello stesso problema. Una volta stabilita tale relazione, può essere utilizzata dall'alto verso il basso (ricorsivamente) o dal basso verso l'alto (nessuna ricorsione). (esempio: elevare un numero a potenza) Esistono tre varianti principali del metodo di riduzione dimensionale: n diminuzione di una quantità costante (solitamente di 1); n riduzione di un fattore costante (normalmente 2 volte); n riduzione di dimensione variabile. © Pavlovskaya T.A. (SPb NRU ITMO) 23
 Ordinamento per inserimento Si supponga che il problema dell'ordinamento di un array di dimensioni n-1 sia stato risolto. Quindi resta da inserire An al posto giusto: n Sweeping l'array da sinistra a destra n Sweep l'array da destra a sinistra n Usando una ricerca binaria per il punto di inserimento n Sebbene l'ordinamento per inserimento sia basato su un approccio ricorsivo, sarà più efficiente per implementarlo dal basso verso l'alto (iterativo). © Pavlovskaya T.A. (SPb NRU ITMO) 24
Ordinamento per inserimento Si supponga che il problema dell'ordinamento di un array di dimensioni n-1 sia stato risolto. Quindi resta da inserire An al posto giusto: n Sweeping l'array da sinistra a destra n Sweep l'array da destra a sinistra n Usando una ricerca binaria per il punto di inserimento n Sebbene l'ordinamento per inserimento sia basato su un approccio ricorsivo, sarà più efficiente per implementarlo dal basso verso l'alto (iterativo). © Pavlovskaya T.A. (SPb NRU ITMO) 24
 Implementazione pseudocodice per i = 1 to n - 1 do v = 0 e A[j] > v do A
Implementazione pseudocodice per i = 1 to n - 1 do v = 0 e A[j] > v do A
 Efficienza dell'ordinamento per inserimento n Caso peggiore: esegue lo stesso numero di confronti dell'ordinamento per selezione n Caso migliore (per l'array inizialmente ordinato): il confronto viene eseguito solo 1 volta per ogni passaggio del ciclo esterno n Caso medio (array casuale): eseguito ~2 volte meno confronti rispetto al caso di un array discendente. Quella. , il caso medio è 2 volte migliore del caso peggiore. Insieme a prestazioni eccellenti per array quasi ordinati, questo distingue l'ordinamento per inserimento da altri algoritmi elementari (selezione e bolla) n Modifica del metodo - inserimento di più elementi contemporaneamente, che vengono ordinati prima dell'inserimento. n Un'estensione dell'ordinamento per inserimento, Shellsort, fornisce un algoritmo ancora migliore per ordinare file abbastanza grandi. © Pavlovskaya T.A. (SPb NRU ITMO) 26
Efficienza dell'ordinamento per inserimento n Caso peggiore: esegue lo stesso numero di confronti dell'ordinamento per selezione n Caso migliore (per l'array inizialmente ordinato): il confronto viene eseguito solo 1 volta per ogni passaggio del ciclo esterno n Caso medio (array casuale): eseguito ~2 volte meno confronti rispetto al caso di un array discendente. Quella. , il caso medio è 2 volte migliore del caso peggiore. Insieme a prestazioni eccellenti per array quasi ordinati, questo distingue l'ordinamento per inserimento da altri algoritmi elementari (selezione e bolla) n Modifica del metodo - inserimento di più elementi contemporaneamente, che vengono ordinati prima dell'inserimento. n Un'estensione dell'ordinamento per inserimento, Shellsort, fornisce un algoritmo ancora migliore per ordinare file abbastanza grandi. © Pavlovskaya T.A. (SPb NRU ITMO) 26

 Generazione di oggetti combinatori n I tipi più importanti di oggetti combinatori sono permutazioni, combinazioni e sottoinsiemi di un dato insieme. n Di solito sorgono in compiti che richiedono considerazione varie opzioni scelta. n Inoltre, ci sono i concetti di posizionamento e partizionamento. © Pavlovskaya T.A. (SPb NRU ITMO) 28
Generazione di oggetti combinatori n I tipi più importanti di oggetti combinatori sono permutazioni, combinazioni e sottoinsiemi di un dato insieme. n Di solito sorgono in compiti che richiedono considerazione varie opzioni scelta. n Inoltre, ci sono i concetti di posizionamento e partizionamento. © Pavlovskaya T.A. (SPb NRU ITMO) 28
 Generazione di permutazioni Numero di permutazioni n Sia dato un insieme (insieme) di n elementi. n Qualsiasi elemento può prendere il primo posto nella permutazione, cioè non ci sono modi per scegliere il primo elemento. Sono rimasti (n-1) elementi per scegliere il secondo elemento nella permutazione (ci sono (n-1) modi per scegliere il secondo elemento). n Sono rimasti (n-2) elementi per scegliere il terzo elemento nella permutazione, ecc. n In totale si può ottenere un insieme ordinato di n elementi: nei seguenti modi
Generazione di permutazioni Numero di permutazioni n Sia dato un insieme (insieme) di n elementi. n Qualsiasi elemento può prendere il primo posto nella permutazione, cioè non ci sono modi per scegliere il primo elemento. Sono rimasti (n-1) elementi per scegliere il secondo elemento nella permutazione (ci sono (n-1) modi per scegliere il secondo elemento). n Sono rimasti (n-2) elementi per scegliere il terzo elemento nella permutazione, ecc. n In totale si può ottenere un insieme ordinato di n elementi: nei seguenti modi
 Applicazione del metodo di riduzione dimensionale al problema di ottenere tutte le permutazioni di n Per semplicità, assumiamo che l'insieme degli elementi da permutare sia l'insieme degli interi da 1 a n. n Il compito del più piccolo è generare tutto (n - 1)! permutazioni. n Supponendo che sia stato risolto, possiamo ottenere una soluzione al problema più grande inserendo n in ciascuna delle n posizioni possibili tra gli elementi di ciascuna delle permutazioni di n - 1 elementi. n Tutte le permutazioni ottenute in questo modo saranno diverse e il loro numero totale: n(n- 1)! =n! n È possibile inserire n nelle permutazioni generate in precedenza da sinistra a destra o da destra a sinistra. È vantaggioso iniziare da destra verso sinistra e cambiare direzione ogni volta che si passa a una nuova permutazione dell'insieme (1, . . . , n - 1). © Pavlovskaya T.A. (SPb NRU ITMO) 30
Applicazione del metodo di riduzione dimensionale al problema di ottenere tutte le permutazioni di n Per semplicità, assumiamo che l'insieme degli elementi da permutare sia l'insieme degli interi da 1 a n. n Il compito del più piccolo è generare tutto (n - 1)! permutazioni. n Supponendo che sia stato risolto, possiamo ottenere una soluzione al problema più grande inserendo n in ciascuna delle n posizioni possibili tra gli elementi di ciascuna delle permutazioni di n - 1 elementi. n Tutte le permutazioni ottenute in questo modo saranno diverse e il loro numero totale: n(n- 1)! =n! n È possibile inserire n nelle permutazioni generate in precedenza da sinistra a destra o da destra a sinistra. È vantaggioso iniziare da destra verso sinistra e cambiare direzione ogni volta che si passa a una nuova permutazione dell'insieme (1, . . . , n - 1). © Pavlovskaya T.A. (SPb NRU ITMO) 30
 Esempio (generazione ascendente di permutazioni) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (St. Pietroburgo NRU ITMO) 31
Esempio (generazione ascendente di permutazioni) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (St. Pietroburgo NRU ITMO) 31
 Algoritmo Johnson-Trotter Viene introdotta la nozione di elemento mobile. Ad ogni elemento è associata una freccia, un elemento è considerato mobile se la freccia punta ad un elemento vicino più piccolo. n Inizializzare la prima permutazione con il valore 1 2. . . n (tutte le frecce a sinistra) n finché c'è un numero di cellulare k do n Trova il numero di cellulare più grande k Scambia k e il numero vicino indicato dalla freccia k n ITMO) 32
Algoritmo Johnson-Trotter Viene introdotta la nozione di elemento mobile. Ad ogni elemento è associata una freccia, un elemento è considerato mobile se la freccia punta ad un elemento vicino più piccolo. n Inizializzare la prima permutazione con il valore 1 2. . . n (tutte le frecce a sinistra) n finché c'è un numero di cellulare k do n Trova il numero di cellulare più grande k Scambia k e il numero vicino indicato dalla freccia k n ITMO) 32
 Ordine lessicografico n Sia la prima permutazione (ad esempio 1234). n Per trovarne uno successivo: 1. Scansiona la permutazione corrente da destra a sinistra alla ricerca della prima coppia elementi vicini tale che a[i]
Ordine lessicografico n Sia la prima permutazione (ad esempio 1234). n Per trovarne uno successivo: 1. Scansiona la permutazione corrente da destra a sinistra alla ricerca della prima coppia elementi vicini tale che a[i]
 Un esempio per la comprensione dell'algoritmo
Un esempio per la comprensione dell'algoritmo
 Il numero di tutte le permutazioni di n elementi Р(n) = n! © Pavlovskaya T.A. (San Pietroburgo NRU ITMO) 35
Il numero di tutte le permutazioni di n elementi Р(n) = n! © Pavlovskaya T.A. (San Pietroburgo NRU ITMO) 35
 Sottoinsiemi n Un insieme A è un sottoinsieme di un insieme B se un qualsiasi elemento appartenente ad A appartiene anche a B: A B o A B n Ogni insieme è il suo proprio sottoinsieme. L'insieme vuoto è un sottoinsieme di qualsiasi insieme. n L'insieme di tutti i sottoinsiemi è indicato con 2 A (è anche chiamato insieme di potenze, insieme di potenze, insieme di potenze, booleano, insieme esponenziale). n Il numero di sottoinsiemi di un insieme finito costituito da n elementi è 2 n (vedi la dimostrazione in Wikipedia) © Pavlovskaya T. A. (SPb NRU ITMO) 36
Sottoinsiemi n Un insieme A è un sottoinsieme di un insieme B se un qualsiasi elemento appartenente ad A appartiene anche a B: A B o A B n Ogni insieme è il suo proprio sottoinsieme. L'insieme vuoto è un sottoinsieme di qualsiasi insieme. n L'insieme di tutti i sottoinsiemi è indicato con 2 A (è anche chiamato insieme di potenze, insieme di potenze, insieme di potenze, booleano, insieme esponenziale). n Il numero di sottoinsiemi di un insieme finito costituito da n elementi è 2 n (vedi la dimostrazione in Wikipedia) © Pavlovskaya T. A. (SPb NRU ITMO) 36
 Generazione di tutti i sottoinsiemi n Applichiamo il metodo per ridurre la dimensione del problema di 1. n Tutti i sottoinsiemi A = (a 1, . . . , an) possono essere divisi in due gruppi: quelli che contengono l'elemento an e quelli che non lo fanno. n Il primo gruppo è composto da tutti i sottoinsiemi (a 1, . . . , an-1); tutti gli elementi del secondo gruppo possono essere ottenuti aggiungendo l'elemento an ai sottoinsiemi del primo gruppo. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) righe: 000 001 010 011 100 101 110 111 n Altri ordini: densi; Codice grigio: n 000 001 010 111 100 © Pavlovskaya T. A. (San Pietroburgo NRU ITMO) 37
Generazione di tutti i sottoinsiemi n Applichiamo il metodo per ridurre la dimensione del problema di 1. n Tutti i sottoinsiemi A = (a 1, . . . , an) possono essere divisi in due gruppi: quelli che contengono l'elemento an e quelli che non lo fanno. n Il primo gruppo è composto da tutti i sottoinsiemi (a 1, . . . , an-1); tutti gli elementi del secondo gruppo possono essere ottenuti aggiungendo l'elemento an ai sottoinsiemi del primo gruppo. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) righe: 000 001 010 011 100 101 110 111 n Altri ordini: densi; Codice grigio: n 000 001 010 111 100 © Pavlovskaya T. A. (San Pietroburgo NRU ITMO) 37
 Generazione di codici Gray n È possibile costruire ricorsivamente un codice Gray per n bit da un codice per n-1 bit: n scrivendo i codici in ordine inverso n concatenando l'elenco originale e l'elenco invertito n aggiungendo 0 all'inizio di ogni codice in l'elenco originale e 1 all'inizio dei codici nell'elenco invertito. Esempio: n Codici per n = 2 bit: 00, 01, 10 n Lista codici invertiti: 10, 11, 00 n Lista combinata: 00, 01, 10, 11, 00 n Zeri aggiunti alla lista iniziale: 000, 001, 010 , 11, 00 n Unità aggiunte all'elenco invertito: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (San Pietroburgo NRU ITMO) 38
Generazione di codici Gray n È possibile costruire ricorsivamente un codice Gray per n bit da un codice per n-1 bit: n scrivendo i codici in ordine inverso n concatenando l'elenco originale e l'elenco invertito n aggiungendo 0 all'inizio di ogni codice in l'elenco originale e 1 all'inizio dei codici nell'elenco invertito. Esempio: n Codici per n = 2 bit: 00, 01, 10 n Lista codici invertiti: 10, 11, 00 n Lista combinata: 00, 01, 10, 11, 00 n Zeri aggiunti alla lista iniziale: 000, 001, 010 , 11, 00 n Unità aggiunte all'elenco invertito: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (San Pietroburgo NRU ITMO) 38
 Sottoinsiemi di elementi K n Il numero di sottoinsiemi di elementi k n (0 k n) è chiamato numero di combinazioni (coefficiente binomiale): n La soluzione diretta è inefficiente a causa della rapida crescita del fattoriale. n Di norma, la generazione di k sottoinsiemi di elementi viene eseguita in ordine lessicografico (per due sottoinsiemi qualsiasi, il primo da generare è quello i cui indici di elementi possono formare un numero di k cifre più piccolo nel numero n-ario sistema). n Metodo: n il primo elemento di un sottoinsieme di cardinalità k può essere uno qualsiasi degli elementi, partendo dal primo e terminando con la (n-k+1)-esima. n Dopo aver fissato l'indice del primo elemento del sottoinsieme, resta da selezionare k-1 elementi da elementi con indici maggiori del primo. n Inoltre, allo stesso modo, riducendo il problema a una dimensione più piccola fino a livello più basso la ricorsione non selezionerà l'ultimo elemento, dopodiché il sottoinsieme selezionato potrà essere stampato o elaborato. © Pavlovskaya T.A. (San Pietroburgo NRU ITMO) 39
Sottoinsiemi di elementi K n Il numero di sottoinsiemi di elementi k n (0 k n) è chiamato numero di combinazioni (coefficiente binomiale): n La soluzione diretta è inefficiente a causa della rapida crescita del fattoriale. n Di norma, la generazione di k sottoinsiemi di elementi viene eseguita in ordine lessicografico (per due sottoinsiemi qualsiasi, il primo da generare è quello i cui indici di elementi possono formare un numero di k cifre più piccolo nel numero n-ario sistema). n Metodo: n il primo elemento di un sottoinsieme di cardinalità k può essere uno qualsiasi degli elementi, partendo dal primo e terminando con la (n-k+1)-esima. n Dopo aver fissato l'indice del primo elemento del sottoinsieme, resta da selezionare k-1 elementi da elementi con indici maggiori del primo. n Inoltre, allo stesso modo, riducendo il problema a una dimensione più piccola fino a livello più basso la ricorsione non selezionerà l'ultimo elemento, dopodiché il sottoinsieme selezionato potrà essere stampato o elaborato. © Pavlovskaya T.A. (San Pietroburgo NRU ITMO) 39
 Esempio: combinazioni da 6 a 3 #include const int N = 6, K = 3; int a[K]; void rec(int i) ( if (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
Esempio: combinazioni da 6 a 3 #include const int N = 6, K = 3; int a[K]; void rec(int i) ( if (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
 Proprietà delle combinazioni n ogni sottoinsieme di n elementi di un dato insieme di elementi corrisponde a uno e solo un sottoinsieme di n-k elementi dello stesso insieme: n © Pavlovskaya T. A. (SPb NRU ITMO) 41
Proprietà delle combinazioni n ogni sottoinsieme di n elementi di un dato insieme di elementi corrisponde a uno e solo un sottoinsieme di n-k elementi dello stesso insieme: n © Pavlovskaya T. A. (SPb NRU ITMO) 41
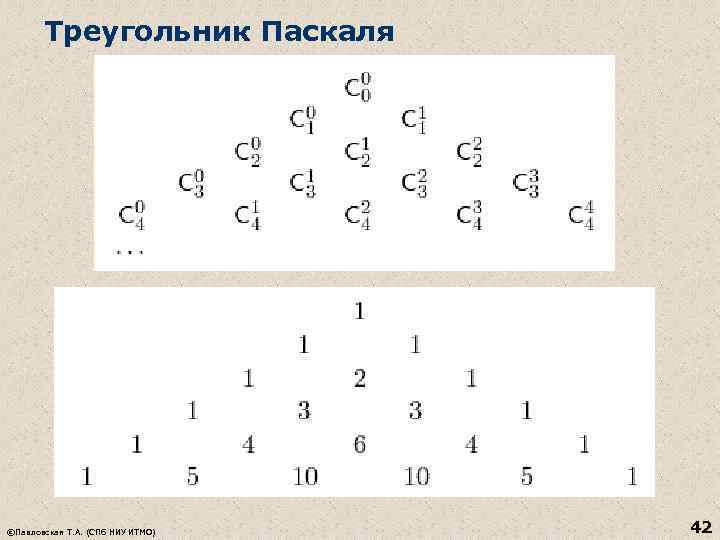

 Posizionamenti n Un posizionamento di n elementi per m è una sequenza costituita da m diversi elementi di un insieme di n elementi (combinazioni che sono costituite da dati n elementi da m elementi e differiscono negli elementi stessi o nell'ordine degli elementi ) La differenza nelle definizioni di combinazioni e posizionamenti: n Una combinazione è un sottoinsieme contenente m elementi su n (l'ordine degli elementi non è importante). n Il posizionamento è una sequenza contenente m elementi su n (l'ordine degli elementi è importante). Quando si forma una sequenza, l'ordine degli elementi è importante e quando si forma un sottoinsieme, l'ordine non è importante. © Pavlovskaya T.A. (SPb. GU ITMO) 44
Posizionamenti n Un posizionamento di n elementi per m è una sequenza costituita da m diversi elementi di un insieme di n elementi (combinazioni che sono costituite da dati n elementi da m elementi e differiscono negli elementi stessi o nell'ordine degli elementi ) La differenza nelle definizioni di combinazioni e posizionamenti: n Una combinazione è un sottoinsieme contenente m elementi su n (l'ordine degli elementi non è importante). n Il posizionamento è una sequenza contenente m elementi su n (l'ordine degli elementi è importante). Quando si forma una sequenza, l'ordine degli elementi è importante e quando si forma un sottoinsieme, l'ordine non è importante. © Pavlovskaya T.A. (SPb. GU ITMO) 44
 Numero di posizionamenti n Numero di posizionamenti da n a m: Esempio 1: Quanti numeri a due cifre ci sono in cui la cifra delle decine e quella delle unità sono diverse e dispari? Set principale: (1, 3, 5, 7, 9) - cifre dispari, n=5 n Connessione - numero a due cifre m=2, l'ordine è importante, quindi questo è un posizionamento di "da cinque per due". n Le permutazioni possono essere considerate un caso speciale di piazzamenti con m=n Esempio 2: In quanti modi si può formare una bandiera composta da tre strisce orizzontali di diversi colori se c'è un materiale di cinque colori? © Pavlovskaya T.A. (SPb NRU ITMO) 45
Numero di posizionamenti n Numero di posizionamenti da n a m: Esempio 1: Quanti numeri a due cifre ci sono in cui la cifra delle decine e quella delle unità sono diverse e dispari? Set principale: (1, 3, 5, 7, 9) - cifre dispari, n=5 n Connessione - numero a due cifre m=2, l'ordine è importante, quindi questo è un posizionamento di "da cinque per due". n Le permutazioni possono essere considerate un caso speciale di piazzamenti con m=n Esempio 2: In quanti modi si può formare una bandiera composta da tre strisce orizzontali di diversi colori se c'è un materiale di cinque colori? © Pavlovskaya T.A. (SPb NRU ITMO) 45
 Allocazioni con ripetizioni n Disposizioni con ripetizioni da n elementi dell'insieme E=(a 1, a 2, . . . , an) per k - qualsiasi sequenza finita costituita da k elementi dell'insieme dato E. n almeno in un punto hanno elementi diversi dell'insieme E. n Il numero di posizionamenti diversi con ripetizioni da n a k è uguale a nk. © Pavlovskaya T.A. (San Pietroburgo NRU ITMO) 46
Allocazioni con ripetizioni n Disposizioni con ripetizioni da n elementi dell'insieme E=(a 1, a 2, . . . , an) per k - qualsiasi sequenza finita costituita da k elementi dell'insieme dato E. n almeno in un punto hanno elementi diversi dell'insieme E. n Il numero di posizionamenti diversi con ripetizioni da n a k è uguale a nk. © Pavlovskaya T.A. (San Pietroburgo NRU ITMO) 46
 Partizione di insiemi n La partizione di un insieme è la sua rappresentazione come unione importo arbitrario sottoinsiemi disgiunti a coppie. n Numero di partizioni non ordinate di un n elemento in k parti - Numero Stirling del 2° tipo: n Numero di partizioni ordinate di un n elemento in m parti di dimensione fissa - coefficiente multinomiale: n Il numero di tutti i non ordinati le partizioni di un insieme di n elementi sono date dal numero di Bell: © Pavlovskaya T. A. (SPb NRU ITMO) 47
Partizione di insiemi n La partizione di un insieme è la sua rappresentazione come unione importo arbitrario sottoinsiemi disgiunti a coppie. n Numero di partizioni non ordinate di un n elemento in k parti - Numero Stirling del 2° tipo: n Numero di partizioni ordinate di un n elemento in m parti di dimensione fissa - coefficiente multinomiale: n Il numero di tutti i non ordinati le partizioni di un insieme di n elementi sono date dal numero di Bell: © Pavlovskaya T. A. (SPb NRU ITMO) 47
 Metodo di riduzione di un fattore costante n Esempio: ricerca binaria n Tali algoritmi sono logaritmici e, essendo molto veloci, sono piuttosto rari. Metodo di riduzione di un fattore variabile n Esempi: ricerca e inserimento in un albero di ricerca binario, ricerca per interpolazione: © Pavlovskaya T. A. (SPb. GU ITMO) 48
Metodo di riduzione di un fattore costante n Esempio: ricerca binaria n Tali algoritmi sono logaritmici e, essendo molto veloci, sono piuttosto rari. Metodo di riduzione di un fattore variabile n Esempi: ricerca e inserimento in un albero di ricerca binario, ricerca per interpolazione: © Pavlovskaya T. A. (SPb. GU ITMO) 48
 Analisi dell'efficienza n La ricerca per interpolazione richiede in media meno di log 2 n+1 confronti chiave durante la ricerca in un elenco di n valori casuali. n Questa funzione cresce così lentamente che per tutti i valori pratici reali di n può essere considerata una costante. n Tuttavia, nel peggiore dei casi, la ricerca di interpolazione degenera in una ricerca lineare, considerata la peggiore possibile. n La ricerca per interpolazione viene utilizzata al meglio per file di grandi dimensioni e per applicazioni in cui il confronto o l'accesso ai dati è un'operazione costosa. © Pavlovskaya T.A. (SPb NRU ITMO) 49
Analisi dell'efficienza n La ricerca per interpolazione richiede in media meno di log 2 n+1 confronti chiave durante la ricerca in un elenco di n valori casuali. n Questa funzione cresce così lentamente che per tutti i valori pratici reali di n può essere considerata una costante. n Tuttavia, nel peggiore dei casi, la ricerca di interpolazione degenera in una ricerca lineare, considerata la peggiore possibile. n La ricerca per interpolazione viene utilizzata al meglio per file di grandi dimensioni e per applicazioni in cui il confronto o l'accesso ai dati è un'operazione costosa. © Pavlovskaya T.A. (SPb NRU ITMO) 49
 Metodo di trasformazione n Consiste nel fatto che l'istanza del compito viene trasformata in un'altra, che per un motivo o per l'altro è più facile da risolvere. n Esistono tre varianti principali di questo metodo: © Pavlovskaya T. A. (SPb NRU ITMO) 50
Metodo di trasformazione n Consiste nel fatto che l'istanza del compito viene trasformata in un'altra, che per un motivo o per l'altro è più facile da risolvere. n Esistono tre varianti principali di questo metodo: © Pavlovskaya T. A. (SPb NRU ITMO) 50
 Esempio 1: Verifica dell'unicità degli elementi in un array n Un algoritmo di forza bruta confronta a coppie tutti gli elementi finché non vengono trovati due elementi identici o finché tutte le possibili coppie non sono state esaminate. Nel peggiore dei casi, l'efficienza è quadratica. n Puoi avvicinarti alla soluzione del problema in un altro modo: prima ordina l'array, quindi confronta solo gli elementi consecutivi. n Il tempo di esecuzione dell'algoritmo è la somma del tempo di ordinamento e del tempo per controllare gli elementi vicini. n Se si utilizza buon algoritmo ordinamento, l'intero algoritmo per verificare l'unicità degli elementi dell'array avrà anche un'efficienza di O (n log n) © Pavlovskaya T. A. (SPb NRU ITMO) 51
Esempio 1: Verifica dell'unicità degli elementi in un array n Un algoritmo di forza bruta confronta a coppie tutti gli elementi finché non vengono trovati due elementi identici o finché tutte le possibili coppie non sono state esaminate. Nel peggiore dei casi, l'efficienza è quadratica. n Puoi avvicinarti alla soluzione del problema in un altro modo: prima ordina l'array, quindi confronta solo gli elementi consecutivi. n Il tempo di esecuzione dell'algoritmo è la somma del tempo di ordinamento e del tempo per controllare gli elementi vicini. n Se si utilizza buon algoritmo ordinamento, l'intero algoritmo per verificare l'unicità degli elementi dell'array avrà anche un'efficienza di O (n log n) © Pavlovskaya T. A. (SPb NRU ITMO) 51