Die Brute-Force-Methode ist ein direkter Lösungsansatz
Problem, das normalerweise direkt auf der Problemstellung und den Definitionen der verwendeten Konzepte basiert.
Ein Brute-Force-Algorithmus zum Lösen eines allgemeinen Suchproblems wird als sequentielle Suche bezeichnet. Dieser Algorithmus vergleicht einfach die Elemente einer gegebenen Liste nacheinander mit dem Suchschlüssel, bis entweder ein Element mit dem angegebenen Schlüsselwert gefunden wird (erfolgreiche Suche) oder die gesamte Liste untersucht wird, aber das erforderliche Element nicht gefunden wird (fehlgeschlagene Suche). Oft wird ein einfacher zusätzlicher Trick angewendet: Wenn Sie den Suchschlüssel am Ende der Liste hinzufügen, wird die Suche definitiv erfolgreich sein, daher können Sie die Listenvervollständigungsprüfung in jeder Iteration des Algorithmus entfernen. Das Folgende ist der Pseudocode einer solchen verbesserten Version; Es wird davon ausgegangen, dass die Eingabedaten in Form eines Arrays vorliegen.
Wenn die ursprüngliche Liste sortiert ist, kann eine weitere Verbesserung verwendet werden: Die Suche in einer solchen Liste kann gestoppt werden, sobald ein Element gefunden wird, das nicht kleiner als der Suchschlüssel ist. Die sequentielle Suche veranschaulicht hervorragend den Brute-Force-Ansatz mit seinen charakteristischen Stärken (Einfachheit) und Schwächen (geringe Effizienz).
Es ist ziemlich offensichtlich, dass die Laufzeit dieses Algorithmus für die gleiche Liste der Größe n stark variieren kann. Im schlimmsten Fall, d.h. Wenn die Liste das gewünschte Element nicht enthält oder wenn das Element an letzter Stelle in der Liste steht, führt der Algorithmus die größte Anzahl von Schlüsselvergleichsoperationen mit allen n Elementen der Liste durch: C(n) = n.
1.2. Rabins Algorithmus.
Rabins Algorithmus ist eine Modifikation des linearen Algorithmus, er basiert auf einer sehr einfachen Idee:
„Stellen Sie sich vor, dass wir in dem Wort A, dessen Länge m ist, nach einem Muster X der Länge n suchen. Schneiden wir ein "Fenster" der Größe n aus und verschieben es entlang des Eingabewortes. Uns interessiert, ob das Wort im „Kästchen“ mit dem vorgegebenen Muster übereinstimmt. Lange Briefe vergleichen. Stattdessen legen wir eine numerische Funktion auf Wörter der Länge n fest, dann reduziert sich das Problem auf den Vergleich von Zahlen, was zweifellos schneller ist. Wenn die Werte dieser Funktion für das Wort im "Fenster" und für das Beispiel unterschiedlich sind, gibt es keine Übereinstimmung. Nur wenn die Werte gleich sind, muss nacheinander auf buchstabenweise Übereinstimmung geprüft werden.
Dieser Algorithmus führt einen linearen Durchlauf durch die Zeile (n Schritte) und einen linearen Durchlauf durch den gesamten Text (m Schritte) durch, sodass die Gesamtlaufzeit O(n+m) ist. Gleichzeitig berücksichtigen wir nicht die zeitliche Komplexität der Berechnung der Hash-Funktion, da das Wesen des Algorithmus darin besteht, dass diese Funktion so einfach zu berechnen ist, dass ihre Operation die Gesamtoperation des Algorithmus nicht beeinflusst.
Der Rabin-Algorithmus und der sequentielle Suchalgorithmus sind Algorithmen mit den geringsten Arbeitskosten, sodass sie zur Verwendung bei der Lösung einer bestimmten Klasse von Problemen geeignet sind. Diese Algorithmen sind jedoch nicht die optimalsten.
1.3. Knuth-Morris-Pratt-Algorithmus (kmp).
Das KMP-Verfahren verwendet die Vorverarbeitung des erforderlichen Strings, nämlich: Auf seiner Basis wird eine Präfixfunktion erstellt. In diesem Fall wird die folgende Idee verwendet: Wenn das Präfix (auch Suffix) eines Strings der Länge i länger als ein Zeichen ist, dann ist es auch das Präfix eines Teilstrings der Länge i-1. Daher prüfen wir das Präfix des vorherigen Teilstrings, wenn es nicht übereinstimmt, dann das Präfix seines Präfixes und so weiter. Dadurch finden wir das größte gewünschte Präfix. Die nächste zu beantwortende Frage lautet: Warum ist die Ausführungszeit der Prozedur linear, weil sie eine verschachtelte Schleife hat? Nun, erstens erfolgt die Zuweisung der Präfixfunktion genau m mal, die übrige Zeit ändert sich die Variable k. Daher ist die Gesamtlaufzeit des Programms O(n+m), also lineare Zeit.
und nächste Funktion: function show(pos, path, w, h) ( var canvas = document.getElementById("canID"); // das Canvas-Objekt abrufen var ctx = canvas.getContext("2d"); // es hat eine Kontexteigenschaft Drawing var x0 = 10, y0 = 10; // die Position der oberen linken Ecke der Karte canvas.width = w+2*x0; canvas.height = h+2*y0; // Größe der Leinwand ändern (etwas größer als w x h) ctx .beginPath(); // Beginne mit dem Zeichnen einer Polylinie ctx.moveTo(x0+pos.x,y0+pos.y)// bewege dich zur 0. Stadt for(var i=1; i Ein Beispiel für die Das Ergebnis des Funktionsaufrufs wird rechts angezeigt.Die Bedeutung der Zeichenbefehle sollte aus deren Namen und Kommentaren im Code ersichtlich sein.Zuerst wird eine geschlossene Polylinie (Reisender Pfad) gezeichnet.Dann die Kreise der Städte und darüber ihnen die Nummern der Städte. Das Arbeiten mit einem Graben in JavaScript ist etwas umständlich und in Zukunft werden wir die Klasse verwenden zeichnen, was diese Arbeit vereinfacht und Ihnen gleichzeitig ermöglicht, Bilder im SVG-Format zu erhalten.
Fehlschlag im Timer
Die Implementierung des Suchalgorithmus zum Finden des kürzesten Weges im Timer ist nicht schwierig. Um den besten Pfad in einem Array zu speichern minWeg, schreiben Sie eine Funktion zum Kopieren der Werte von Array-Elementen Quelle in ein Array des:
Function copy(des, src) ( if(des.length !== src.length) des = new Array(src.length); for(var i=0; i
Ich habe ein mathematisches Problem, das ich durch Versuch und Irrtum löse (ich glaube, es heißt Brute Force), und das Programm funktioniert hervorragend, wenn mehrere Parameter vorhanden sind, aber je mehr Variablen/Daten hinzugefügt werden, desto länger dauert die Ausführung.
Mein Problem ist, dass der Prototyp zwar funktioniert, aber für Tausende von Variablen und große Datensätze nützlich ist. Ich frage mich also, ob Brute-Force-Algorithmen skaliert werden können. Wie kann ich die Skalierung angehen?
3 Antworten
Im Allgemeinen können Sie quantifizieren, wie gut ein Algorithmus skalieren wird, indem Sie die große Ausgabenotation verwenden, um seine Wachstumsrate zu analysieren. Wenn Sie sagen, dass Ihr Algorithmus unter „Brute Force“ läuft, ist nicht klar, inwieweit er skalieren wird. Wenn Ihre "Brute-Force" -Lösung funktioniert, indem alle möglichen Teilmengen oder Kombinationen des Datensatzes aufgelistet werden, wird sie mit ziemlicher Sicherheit nicht skaliert (sie hat eine asymptotische Komplexität von O (2n) bzw. O (n!). Wenn Ihre Brute-Force-Lösung funktioniert, indem alle Elementpaare gefunden und getestet werden, kann sie recht gut skalieren (O(n 2)). Allerdings ohne zusätzliche Information Wie Ihr Algorithmus funktioniert, ist schwer zu sagen.
Per Definition sind Brute-Force-Algorithmen dumm. Mit einem intelligenteren Algorithmus (falls Sie einen haben) sind Sie viel besser dran. Ein besserer Algorithmus reduziert die zu erledigende Arbeit hoffentlich so weit, dass Sie dies tun können, ohne über mehrere Computer hinweg „skalieren“ zu müssen.
Unabhängig vom Algorithmus kommt irgendwann der Punkt, an dem die erforderliche Datenmenge oder Rechenleistung so groß ist, dass Sie auf etwas wie Hadoop zurückgreifen müssen. Aber generell reden wir hier wirklich von Big Data. Mit einem PC kann man heute schon viel machen.
Der Algorithmus zur Lösung dieses Problems ist für den von uns untersuchten Prozess für die manuelle mathematische Division sowie für die Umwandlung von Dezimalzahlen in eine andere Basis wie Oktal oder Hexadezimal geschlossen, außer dass in den beiden Beispielen nur eine kanonische Lösung berücksichtigt wird.
Um sicherzustellen, dass die Rekursion abgeschlossen wird, ist es wichtig, das Datenarray zu ordnen. Um effizient zu sein und die Anzahl der Rekursionen zu begrenzen, ist es außerdem wichtig, mit höheren Datenwerten zu beginnen.
Konkret ist hier die rekursive Implementierung von Java für dieses Problem - mit einer Kopie des Koeff-Ergebnisvektors für jede Rekursion, wie theoretisch erwartet.
java.util.Arrays importieren; public class Solver ( public static void main(String args) ( int target_sum = 100; // Voraussetzung: sortierte Werte !! int data = new int ( 5, 10, 20, 25, 40, 50 ); / / result vector, init to 0 int coeff = new int; Arrays.fill(coeff, 0); partialSum(data.length - 1, target_sum, coeff, data); ) private static void printResult(int coeff, int data) ( for ( int i = coeff.length - 1; i >= 0; i--) ( if (coeff[i] > 0) ( System.out.print(data[i] + " * " + coeff[i] + " "); ) ) System.out.println(); ) private static void partialSum(int k, int sum, int coeff, int data) ( int x_k = data[k]; for (int c = sum / x_k ; c >= 0; c--) ( coeff[k] = c; if (c * x_k == sum) ( printResult(coeff, data); Continue; ) else if (k > 0) ( // kontextbezogenes Ergebnis in parameter , lokal zum Methodenbereich int newcoeff = Arrays.copyOf(coeff, coeff.length); partialSum(k - 1, sum - c * x_k, newcoeff, data); // for-Schleife auf "c" fährt mit vorherigem fort Koeff-Gehalt ) ) ) )
Aber jetzt ist dieser Code in einem Sonderfall: letzter Test der Wert für jeden Koeffizienten ist 0, daher wird keine Kopie benötigt.
Als Schätzung der Komplexität können wir die maximale Tiefe rekursiver Aufrufe als data.length * min(( data )) verwenden. Natürlich lässt es sich nicht gut skalieren, und der Stack-Trace-Speicher (Option -Xss JVM) wird der begrenzende Faktor sein. Der Code kann bei einem großen Datensatz mit einem Fehler fehlschlagen.
Um diese Mängel zu vermeiden, ist der „Beenden“-Prozess hilfreich. Es besteht darin, den Methodenaufrufstapel durch einen Programmstapel zu ersetzen, um den Ausführungskontext für eine spätere Verarbeitung zu speichern. Hier ist der Code dafür:
java.util.Arrays importieren; java.util.ArrayDeque importieren; java.util.Queue importieren; public class NonRecursive ( // Voraussetzung: sortierte Werte !! private static final int data = new int ( 5, 10, 20, 25, 40, 50 ); // Kontext zum Speichern von Zwischenberechnungen oder einer statischen Lösungsklasse Context ( int k; int sum; int coeff; Context(int k, int sum, int coeff) ( this.k = k; this.sum = sum; this.coeff = coeff; ) ) private static void printResult(int coeff ) ( for (int i = coeff.length - 1; i >= 0; i--) ( if (coeff[i] > 0) ( System.out.print(data[i] + " * " + coeff[ i] + " "); ) ) System.out.println(); ) public static void main(String args) ( int target_sum = 100; // result vector, init to 0 int coeff = new int; Arrays.fill( coeff, 0); // Queue mit Kontexten zur Verarbeitung Queue
Aus meiner Sicht ist es schwierig, bei einer einzelnen Ausführung eines Threads effizienter zu sein - der Stack-Mechanismus erfordert jetzt Kopien des coeff-Arrays.
Die Suche nach einem Teilstring in einem String erfolgt nach einem vorgegebenen Muster, d.h. eine Folge von Zeichen, deren Länge die Länge der ursprünglichen Zeichenkette nicht überschreitet. Die Aufgabe der Suche besteht darin, festzustellen, ob eine Zeichenfolge ein bestimmtes Muster enthält, und die Position (Index) in der Zeichenfolge anzugeben, wenn eine Übereinstimmung gefunden wird.
Der Brute-Force-Algorithmus ist der einfachste und langsamste und besteht darin, alle Textpositionen zu überprüfen, um zu sehen, ob sie mit dem Anfang des Musters übereinstimmen. Stimmt der Anfang des Musters überein, dann wird der nächste Buchstabe im Muster und im Text verglichen, und so weiter, es wird die einfachste und langsamste Antwort gegeben, ob es ein solches Element gibt oder nicht, ohne dass der Index bereits sortiert ist nicht vollständige Übereinstimmung des Musters oder Unterschied im nächsten Buchstaben.
int BFSearch(Zeichen*s, Zeichen*p)
for (int i = 1; strlen(s) - strlen(p); i++)
for (int j = 1; strlen(p); j++)
wenn (p[j] != s)
wenn (j = strlen(p))
Die BFSearch-Funktion sucht nach der Teilzeichenfolge p in der Zeichenfolge s und gibt den Index des ersten Zeichens der Teilzeichenfolge oder 0 zurück, wenn die Teilzeichenfolge nicht gefunden wird. Obwohl diese Methode im Allgemeinen, wie die meisten Brute-Force-Methoden, unwirksam ist, ist sie in manchen Situationen durchaus akzeptabel.
Der schnellste unter den Algorithmen allgemeiner Zweck, der für die Suche nach einer Teilzeichenfolge in einer Zeichenfolge entwickelt wurde, ist der Boyer-Moore-Algorithmus, der von zwei Wissenschaftlern entwickelt wurde - Boyer (Robert S. Boyer) und Moore (J. Strother Moore), dessen Kern wie folgt ist.
Boyer-Moore-Algorithmus
Die einfachste Version des Boyer-Moore-Algorithmus besteht aus den folgenden Schritten. Im ersten Schritt wird eine Verschiebungstabelle für die gewünschte Probe erstellt. Der Tabellenaufbauprozess wird nachstehend beschrieben. Als nächstes werden der Anfang der Zeichenfolge und des Musters kombiniert, und der Test beginnt beim letzten Zeichen des Musters. Wenn das letzte Zeichen des Musters und das ihm entsprechende Zeichen der Zeichenfolge bei der Überlagerung nicht übereinstimmen, wird das Muster relativ zur Zeichenfolge um den aus der Offset-Tabelle erhaltenen Wert verschoben, und der Vergleich wird erneut durchgeführt, beginnend mit das letzte Zeichen des Musters. Wenn die Zeichen übereinstimmen, wird das vorletzte Zeichen des Musters verglichen und so weiter. Wenn alle Zeichen des Beispiels mit den überlagerten Zeichen des Strings übereinstimmen, wurde der Teilstring gefunden und die Suche ist beendet. Wenn ein (nicht das letzte) Zeichen des Musters nicht mit dem entsprechenden Zeichen des Strings übereinstimmt, verschieben wir das Muster um ein Zeichen nach rechts und beginnen wieder beim letzten Zeichen. Der gesamte Algorithmus wird ausgeführt, bis entweder ein Vorkommen des gewünschten Musters gefunden wird oder das Ende der Zeichenfolge erreicht ist.
Der Verschiebungswert bei einer Nichtübereinstimmung des letzten Zeichens wird nach der Regel berechnet: Die Verschiebung des Musters muss minimal sein, um das Auftreten des Musters in der Zeichenfolge nicht zu verpassen. Wenn das gegebene Zeichenfolgenzeichen im Muster vorkommt, wird das Muster so verschoben, dass das Zeichenfolgenzeichen mit dem am weitesten rechts liegenden Vorkommen dieses Zeichens im Muster übereinstimmt. Wenn das Muster dieses Zeichen überhaupt nicht enthält, wird das Muster um einen Betrag verschoben, der seiner Länge entspricht, sodass das erste Zeichen des Musters das nächste Zeichen der getesteten Zeichenfolge überlagert.
Der Offset-Wert für jedes Musterzeichen hängt nur von der Reihenfolge der Zeichen im Muster ab, daher ist es bequem, die Offsets im Voraus zu berechnen und sie als eindimensionales Array zu speichern, wobei jedes Zeichen des Alphabets einem relativen Offset entspricht bis zum letzten Zeichen des Musters. Lassen Sie uns all das oben Erklären einfaches Beispiel. Angenommen, es gibt einen Satz von fünf Zeichen: a, b, c, d, e, und Sie müssen ein Vorkommen des Musters „abbad“ in der Zeichenfolge „abeccacbadbabbad“ finden. Die folgenden Diagramme veranschaulichen alle Phasen der Algorithmusausführung:
Versatztabelle für das „abbad“-Muster.
Suchstart. Das letzte Zeichen des Musters stimmt nicht mit dem überlagerten Zeichen der Zeichenfolge überein. Verschieben Sie die Probe um 5 Positionen nach rechts:
Drei Zeichen des Musters stimmten überein, das vierte jedoch nicht. Verschieben Sie das Muster um eine Position nach rechts:
Das letzte Zeichen stimmt wieder nicht mit dem Zeichenfolgenzeichen überein. Gemäß der Verschiebungstabelle verschieben wir die Probe um 2 Positionen:
Wieder verschieben wir das Sample um 2 Positionen:
Jetzt verschieben wir das Sample gemäß der Tabelle um eine Position und erhalten das gewünschte Vorkommen des Samples:
Wir implementieren den angegebenen Algorithmus. Zunächst sollte der Datentyp „Offset-Tabelle“ definiert werden. Für eine Codetabelle mit 256 Zeichen würde die Strukturdefinition wie folgt aussehen:
BMTable MakeBMTable(char *p)
für (i = 0; i<= 255; i++) bmt->bmtarr[i] = strlen(p);
für (i = strlen(p); i<= 1; i--)
if (bmt->bmtarr] == strlen(p))
bmt->bmtarr] = strlen(p)-i;
Lassen Sie uns nun eine Funktion schreiben, die die Suche durchführt.
int BMSearch(int startpos, char *s, char *p)
pos = startpos + lp - 1;
während (Pos< strlen(s))
if (p != s) pos = pos + bmt->bmtarr];
für (i = lp - 1; i<= 1; i--)
wenn (p[i] != s)
return(pos - lp + 1);
Die BMSearch-Funktion gibt die Position des ersten Zeichens des ersten Vorkommens von Muster p in Zeichenfolge s zurück. Wenn die Sequenz p in s nicht gefunden wird, gibt die Funktion 0 zurück. Mit dem Parameter startpos können Sie die Position in der Zeichenfolge s angeben, ab der die Suche beginnen soll. Dies kann nützlich sein, wenn Sie alle Vorkommen von p in s finden möchten. Um ganz am Anfang der Zeichenfolge zu suchen, setzen Sie startpos auf 1. Wenn das Suchergebnis nicht Null ist, setzen Sie startpos auf "das vorherige Ergebnis plus die Länge des Musters", um das nächste Vorkommen von p in s zu finden.
Binäre (binäre) Suche
Die binäre Suche wird verwendet, wenn das durchsuchte Array bereits sortiert ist.
Die Variablen lb und ub enthalten jeweils die linken und rechten Grenzen des Arraysegments, in dem sich das gewünschte Element befindet. Die Suche beginnt immer mit dem Studium des mittleren Elements des Segments. Wenn der gewünschte Wert kleiner als das mittlere Element ist, müssen Sie zur Suche in der oberen Hälfte des Segments gehen, wo alle Elemente kleiner sind als das gerade überprüfte. Mit anderen Worten, der Wert von ub wird (m - 1) und die Hälfte des ursprünglichen Arrays wird in der nächsten Iteration überprüft. Somit wird als Ergebnis jeder Überprüfung der Suchbereich halbiert. Wenn das Array beispielsweise 100 Zahlen enthält, wird der Suchbereich nach der ersten Iteration auf 50 Zahlen reduziert, nach der zweiten auf 25, nach der dritten auf 13, nach der vierten auf 7 usw. Wenn die Länge des Arrays n ist, dann reichen etwa log 2 n Vergleiche aus, um das Array nach Elementen zu durchsuchen.
Algorithmenentwicklungsmethoden n Brute-Force-Methode („frontal“) n Dekompositionsmethode n Problemgrößenreduktionsmethode n Transformationsmethode n Dynamische Programmierung n Greedy-Methoden n Suchreduktionsmethoden n … ©Pavlovskaya T. A. (SPb NRU ITMO) 1

 Brute-Force-Ansatz n Direkter Ansatz zur Lösung eines Problems, der normalerweise direkt auf der Problemstellung und den Definitionen der verwendeten Konzepte basiert. Einfach zu verwenden. n Erzeugt selten schöne und effiziente Algorithmen. n Die Kosten für die Entwicklung eines effizienteren Algorithmus können allein schon inakzeptabel sein einige Probleminstanzen sollen gelöst werden n Kann nützlich sein, um kleine Probleminstanzen zu lösen. n Kann als Maß für die Bestimmung der Effektivität anderer Algorithmen dienen © Pavlovskaya T. A. (SPb NRU ITMO) 3
Brute-Force-Ansatz n Direkter Ansatz zur Lösung eines Problems, der normalerweise direkt auf der Problemstellung und den Definitionen der verwendeten Konzepte basiert. Einfach zu verwenden. n Erzeugt selten schöne und effiziente Algorithmen. n Die Kosten für die Entwicklung eines effizienteren Algorithmus können allein schon inakzeptabel sein einige Probleminstanzen sollen gelöst werden n Kann nützlich sein, um kleine Probleminstanzen zu lösen. n Kann als Maß für die Bestimmung der Effektivität anderer Algorithmen dienen © Pavlovskaya T. A. (SPb NRU ITMO) 3
 n Beispiel: Selection Sort und Bubble Sort 28 -5 ©Pavlovskaya T. A. (St. Petersburg NRU ITMO) 16 0 29 3 -4 56 4
n Beispiel: Selection Sort und Bubble Sort 28 -5 ©Pavlovskaya T. A. (St. Petersburg NRU ITMO) 16 0 29 3 -4 56 4
 Erschöpfende Aufzählung ist ein Brute-Force-Ansatz für kombinatorische Probleme. Es setzt voraus: n Generierung aller möglichen Elemente aus dem Aufgabendefinitionsbereich n Auswahl derjenigen, die die durch die Aufgabenbedingung auferlegten Beschränkungen erfüllen n Suche nach dem gewünschten Element (z. B. Optimierung des Werts der Zielfunktion der Aufgabe). Beispiele: Das Problem des Handlungsreisenden: Finden Sie den kürzesten Weg durch Berücksichtigen Sie alle Teilmengen gegebener Satz von n Objekten, die N Städten gegeben werden, so dass jede Stadt besucht wird, berechnen Sie nur einmal das Gesamtgewicht jedes von ihnen, um die Zulässigkeit zu bestimmen, und das endgültige Ziel ist das ursprüngliche. Wählen Sie aus der zulässigen Teilmenge mit dem maximalen Gewicht aus. n Erhalte alle möglichen Routen und erzeuge alle Rucksackprobleme: gegebene N Gegenstände mit gegebenem Gewicht und Kosten für einen Rucksack, der das Gewicht W tragen kann. Lade einen Permutationsrucksack von n - 1 Zwischenstädten, wobei mit den maximalen Kosten gerechnet wird. die Länge der entsprechenden Pfade und das Finden des kürzesten davon. Dies sind NP-schwere Probleme (es ist kein Algorithmus bekannt, der sie in polynomieller Zeit löst). n © Pavlovskaya T. A. (SPb NRU ITMO) 5
Erschöpfende Aufzählung ist ein Brute-Force-Ansatz für kombinatorische Probleme. Es setzt voraus: n Generierung aller möglichen Elemente aus dem Aufgabendefinitionsbereich n Auswahl derjenigen, die die durch die Aufgabenbedingung auferlegten Beschränkungen erfüllen n Suche nach dem gewünschten Element (z. B. Optimierung des Werts der Zielfunktion der Aufgabe). Beispiele: Das Problem des Handlungsreisenden: Finden Sie den kürzesten Weg durch Berücksichtigen Sie alle Teilmengen gegebener Satz von n Objekten, die N Städten gegeben werden, so dass jede Stadt besucht wird, berechnen Sie nur einmal das Gesamtgewicht jedes von ihnen, um die Zulässigkeit zu bestimmen, und das endgültige Ziel ist das ursprüngliche. Wählen Sie aus der zulässigen Teilmenge mit dem maximalen Gewicht aus. n Erhalte alle möglichen Routen und erzeuge alle Rucksackprobleme: gegebene N Gegenstände mit gegebenem Gewicht und Kosten für einen Rucksack, der das Gewicht W tragen kann. Lade einen Permutationsrucksack von n - 1 Zwischenstädten, wobei mit den maximalen Kosten gerechnet wird. die Länge der entsprechenden Pfade und das Finden des kürzesten davon. Dies sind NP-schwere Probleme (es ist kein Algorithmus bekannt, der sie in polynomieller Zeit löst). n © Pavlovskaya T. A. (SPb NRU ITMO) 5

 Dekompositionsmethode Auch bekannt als Teile und Herrsche: n Eine Aufgabeninstanz wird in mehrere kleinere Instanzen derselben Aufgabe zerlegt, die idealerweise gleich groß sind. n Kleinere Instanzen des Problems werden gelöst (normalerweise rekursiv, obwohl manchmal ein anderer Algorithmus für kleine Instanzen verwendet wird). n Gegebenenfalls wird die Lösung des ursprünglichen Problems durch Kombinieren von Lösungen kleinerer Instanzen gefunden. Die Dekompositionsmethode ist ideal für paralleles Rechnen. © Pavlovskaya T. A. (SPb NRU ITMO) 7
Dekompositionsmethode Auch bekannt als Teile und Herrsche: n Eine Aufgabeninstanz wird in mehrere kleinere Instanzen derselben Aufgabe zerlegt, die idealerweise gleich groß sind. n Kleinere Instanzen des Problems werden gelöst (normalerweise rekursiv, obwohl manchmal ein anderer Algorithmus für kleine Instanzen verwendet wird). n Gegebenenfalls wird die Lösung des ursprünglichen Problems durch Kombinieren von Lösungen kleinerer Instanzen gefunden. Die Dekompositionsmethode ist ideal für paralleles Rechnen. © Pavlovskaya T. A. (SPb NRU ITMO) 7
 Rekursive Zerlegungsgleichung n Im allgemeinen Fall kann eine Instanz eines Problems der Größe n in mehrere Instanzen der Größe n/b zerlegt werden, die gelöst werden müssen. n Verallgemeinerte rekursive Zerlegungsgleichung: (1) n Der Einfachheit halber wird angenommen, dass die Größe von n gleich der Potenz von b ist. n Die Wachstumsreihenfolge hängt von a, b und f ab. © Pavlovskaya T. A. (SPb NRU ITMO) 8
Rekursive Zerlegungsgleichung n Im allgemeinen Fall kann eine Instanz eines Problems der Größe n in mehrere Instanzen der Größe n/b zerlegt werden, die gelöst werden müssen. n Verallgemeinerte rekursive Zerlegungsgleichung: (1) n Der Einfachheit halber wird angenommen, dass die Größe von n gleich der Potenz von b ist. n Die Wachstumsreihenfolge hängt von a, b und f ab. © Pavlovskaya T. A. (SPb NRU ITMO) 8
 Der Hauptzerlegungssatz (1) n Man kann die Effizienzklasse des Algorithmus angeben, ohne die rekursive Gleichung selbst zu lösen. n Dieser Ansatz ermöglicht es, die Wachstumsreihenfolge der Lösung festzulegen, ohne die unbekannten Faktoren zu bestimmen. © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 9
Der Hauptzerlegungssatz (1) n Man kann die Effizienzklasse des Algorithmus angeben, ohne die rekursive Gleichung selbst zu lösen. n Dieser Ansatz ermöglicht es, die Wachstumsreihenfolge der Lösung festzulegen, ohne die unbekannten Faktoren zu bestimmen. © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 9
 Mergesort Sortiert das angegebene Array, indem es in zwei Hälften geteilt wird, jede Hälfte rekursiv sortiert wird und die beiden sortierten Hälften zu einem sortierten Array zusammengeführt werden: Mergesort (A) if n>1 Erste Hälfte A -> in Array B Zweite Hälfte A -> in Array C Mergesort(B) Mergesort(C) Merge(B, C, A) // Merge ©Pavlovskaya T. A. (St. Petersburg NRU ITMO) 10
Mergesort Sortiert das angegebene Array, indem es in zwei Hälften geteilt wird, jede Hälfte rekursiv sortiert wird und die beiden sortierten Hälften zu einem sortierten Array zusammengeführt werden: Mergesort (A) if n>1 Erste Hälfte A -> in Array B Zweite Hälfte A -> in Array C Mergesort(B) Mergesort(C) Merge(B, C, A) // Merge ©Pavlovskaya T. A. (St. Petersburg NRU ITMO) 10
Src="http://present5.com/presentation/54441564_438337950/image-11.jpg" alt="(!LANG:Mergesort (A) if n>1 Erste Hälfte von A -> zu Array B Zweite Hälfte von A"> Mergesort (A) if n>1 Первая половина А -> в массив В Вторая половина А > в массив С Mergesort(B) Mergesort(C) Меrgе(В, С, А) ©Павловская Т. А. (СПб НИУ ИТМО) 11!}
 Zusammenführen von Arrays n Zwei Array-Indizes zeigen nach der Initialisierung auf die ersten Elemente der zusammenzuführenden Arrays. n Die Elemente werden verglichen und das kleinere wird dem neuen Array hinzugefügt. n Der Index des kleineren Elements wird inkrementiert (er zeigt auf das Element, das unmittelbar auf das gerade kopierte folgt). Diese Operation wird wiederholt, bis eines der zusammenzuführenden Arrays erschöpft ist. Die restlichen Elemente des zweiten Arrays werden am Ende des neuen Arrays hinzugefügt. © Pavlovskaya T. A. (SPb NRU ITMO) 12
Zusammenführen von Arrays n Zwei Array-Indizes zeigen nach der Initialisierung auf die ersten Elemente der zusammenzuführenden Arrays. n Die Elemente werden verglichen und das kleinere wird dem neuen Array hinzugefügt. n Der Index des kleineren Elements wird inkrementiert (er zeigt auf das Element, das unmittelbar auf das gerade kopierte folgt). Diese Operation wird wiederholt, bis eines der zusammenzuführenden Arrays erschöpft ist. Die restlichen Elemente des zweiten Arrays werden am Ende des neuen Arrays hinzugefügt. © Pavlovskaya T. A. (SPb NRU ITMO) 12
 Merge-Sort-Analyse n Die Dateilänge sei eine Potenz von 2. n Anzahl der Schlüsselvergleiche: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 Worst Case (Anzahl der Zusammenführungsschlüsselvergleiche) n Worst Case Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n-1 Cw (n ) (n log n) – nach der Hauptsache Theorem ©Pavlovskaya T. A. (SPb NRU ITMO) (1) 13
Merge-Sort-Analyse n Die Dateilänge sei eine Potenz von 2. n Anzahl der Schlüsselvergleiche: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 Worst Case (Anzahl der Zusammenführungsschlüsselvergleiche) n Worst Case Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n-1 Cw (n ) (n log n) – nach der Hauptsache Theorem ©Pavlovskaya T. A. (SPb NRU ITMO) (1) 13
 n Die Anzahl der von Merge Sort durchgeführten Schlüsselvergleiche liegt im schlimmsten Fall sehr nahe an der theoretischen Mindestanzahl von Vergleichen für jeden vergleichsbasierten Sortieralgorithmus. n Der Hauptnachteil von Merge Sort ist der Bedarf an zusätzlichem Speicher, dessen Menge linear proportional zur Größe der Eingabedaten ist. © Pawlowskaja T. A. (SPb NRU ITMO) 14
n Die Anzahl der von Merge Sort durchgeführten Schlüsselvergleiche liegt im schlimmsten Fall sehr nahe an der theoretischen Mindestanzahl von Vergleichen für jeden vergleichsbasierten Sortieralgorithmus. n Der Hauptnachteil von Merge Sort ist der Bedarf an zusätzlichem Speicher, dessen Menge linear proportional zur Größe der Eingabedaten ist. © Pawlowskaja T. A. (SPb NRU ITMO) 14
 Quicksort Anders als Mergesort, das die Elemente eines Arrays nach ihrer Position im Array trennt, trennt Quicksort die Elemente eines Arrays nach ihren Werten. 28 56 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 1 0 29 3 -4 16 15
Quicksort Anders als Mergesort, das die Elemente eines Arrays nach ihrer Position im Array trennt, trennt Quicksort die Elemente eines Arrays nach ihren Werten. 28 56 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 1 0 29 3 -4 16 15
 Beschreibung des Algorithmus n Wählen Sie ein Pivot-Element aus. n Führen Sie eine Permutation von Elementen durch, um eine Partition zu erhalten, wenn alle Elemente bis zu einer Position s das Element A [s] nicht überschreiten und die Elemente nach Position s nicht kleiner als es sind. n Offensichtlich befindet sich A [s] nach der Teilung an der Endposition, und wir können die beiden Subarrays von Elementen vor und nach A [s] unabhängig voneinander sortieren (mit derselben oder einer anderen Methode) ©Pavlovskaya T. A. (SPb NRU ITMO) 16
Beschreibung des Algorithmus n Wählen Sie ein Pivot-Element aus. n Führen Sie eine Permutation von Elementen durch, um eine Partition zu erhalten, wenn alle Elemente bis zu einer Position s das Element A [s] nicht überschreiten und die Elemente nach Position s nicht kleiner als es sind. n Offensichtlich befindet sich A [s] nach der Teilung an der Endposition, und wir können die beiden Subarrays von Elementen vor und nach A [s] unabhängig voneinander sortieren (mit derselben oder einer anderen Methode) ©Pavlovskaya T. A. (SPb NRU ITMO) 16
 Das Verfahren zum Permutieren der Elemente n Effektive Methode, basierend auf zwei Subarray-Durchgängen - von links nach rechts und von rechts nach links. Bei jedem Durchlauf werden die Elemente mit dem Pivot verglichen. n Links-nach-rechts-Pass (i) überspringt Elemente, die kleiner als der Drehpunkt sind, und stoppt beim ersten Element, das nicht kleiner als der Drehpunkt ist. n Pass from right to left (j) überspringt Elemente größer als Pivot und stoppt beim ersten Element, das nicht größer als Pivot ist. n Wenn sich die Scan-Indizes nicht schneiden, tauschen wir die gefundenen Elemente aus und setzen die Durchgänge fort. n Wenn sich die Indizes schneiden, tauschen wir das Pivot-Element mit Aj aus ©Pavlovskaya T. A. (SPb NRU ITMO) 17
Das Verfahren zum Permutieren der Elemente n Effektive Methode, basierend auf zwei Subarray-Durchgängen - von links nach rechts und von rechts nach links. Bei jedem Durchlauf werden die Elemente mit dem Pivot verglichen. n Links-nach-rechts-Pass (i) überspringt Elemente, die kleiner als der Drehpunkt sind, und stoppt beim ersten Element, das nicht kleiner als der Drehpunkt ist. n Pass from right to left (j) überspringt Elemente größer als Pivot und stoppt beim ersten Element, das nicht größer als Pivot ist. n Wenn sich die Scan-Indizes nicht schneiden, tauschen wir die gefundenen Elemente aus und setzen die Durchgänge fort. n Wenn sich die Indizes schneiden, tauschen wir das Pivot-Element mit Aj aus ©Pavlovskaya T. A. (SPb NRU ITMO) 17
 Effizienz von Quicksort n Bester Fall: Alle Partitionen befinden sich in der Mitte der entsprechenden Subarrays. n Ungünstigster Fall, alle Partitionen sind so, dass eines der Subarrays leer ist und die Größe des zweiten um 1 kleiner ist als die Größe des partitionierten Arrays (quadratische Abhängigkeit). n Im durchschnittlichen Fall nehmen wir an, dass die Partitionierung in jeder Position mit der gleichen Wahrscheinlichkeit durchgeführt werden kann: Cavg 2 n ln n 1, 38 n log 2 n © Pavlovskaya T. A. (SPb NRU ITMO) 18
Effizienz von Quicksort n Bester Fall: Alle Partitionen befinden sich in der Mitte der entsprechenden Subarrays. n Ungünstigster Fall, alle Partitionen sind so, dass eines der Subarrays leer ist und die Größe des zweiten um 1 kleiner ist als die Größe des partitionierten Arrays (quadratische Abhängigkeit). n Im durchschnittlichen Fall nehmen wir an, dass die Partitionierung in jeder Position mit der gleichen Wahrscheinlichkeit durchgeführt werden kann: Cavg 2 n ln n 1, 38 n log 2 n © Pavlovskaya T. A. (SPb NRU ITMO) 18
 Algorithmusverbesserungen n verbesserte Pivot-Auswahlmethoden n Umstellung auf einfachere Sortierung für kleine Subarrays n Beseitigung der Rekursion Zusammengenommen können diese Verbesserungen die Laufzeit des Algorithmus um 20-25 % reduzieren (R. Sedgwick) © Pavlovskaya T. A. (SPb NRU ITMO) 19
Algorithmusverbesserungen n verbesserte Pivot-Auswahlmethoden n Umstellung auf einfachere Sortierung für kleine Subarrays n Beseitigung der Rekursion Zusammengenommen können diese Verbesserungen die Laufzeit des Algorithmus um 20-25 % reduzieren (R. Sedgwick) © Pavlovskaya T. A. (SPb NRU ITMO) 19
 Traversierung eines binären Baums Dies ist ein weiteres Beispiel für die Verwendung der Dekompositionsmethode. n Vorwärtstraversierung besucht zuerst die Wurzel des Baums und dann die linken und rechten Teilbäume. n Bei einer symmetrischen Traversierung wird die Wurzel nach dem linken Teilbaum besucht, aber vor dem Besuch des rechten. n Beim Bypass umgekehrte Reihenfolge die Wurzel wird nach den linken und rechten Unterbäumen besucht. © Pawlowskaja T. A. (SPb NRU ITMO) 20
Traversierung eines binären Baums Dies ist ein weiteres Beispiel für die Verwendung der Dekompositionsmethode. n Vorwärtstraversierung besucht zuerst die Wurzel des Baums und dann die linken und rechten Teilbäume. n Bei einer symmetrischen Traversierung wird die Wurzel nach dem linken Teilbaum besucht, aber vor dem Besuch des rechten. n Beim Bypass umgekehrte Reihenfolge die Wurzel wird nach den linken und rechten Unterbäumen besucht. © Pawlowskaja T. A. (SPb NRU ITMO) 20
 Baumtraversierungsprozedur print_tree(tree); start print_tree(left_subtree) visit root print_tree(right_subtree) end; 1 6 8 10 20 ©Pavlovskaya T. A. (SPb. GU ITMO) 21 25 30 21
Baumtraversierungsprozedur print_tree(tree); start print_tree(left_subtree) visit root print_tree(right_subtree) end; 1 6 8 10 20 ©Pavlovskaya T. A. (SPb. GU ITMO) 21 25 30 21

 Methode zur Verringerung der Problemgröße Basiert auf der Verwendung der Beziehung zwischen der Lösung einer gegebenen Instanz des Problems und der Lösung einer kleineren Instanz desselben Problems. Sobald eine solche Beziehung hergestellt ist, kann sie entweder von oben nach unten (rekursiv) oder von unten nach oben (keine Rekursion) verwendet werden. (Beispiel - Potenzieren einer Zahl) Es gibt drei Hauptvarianten der Methode zur Größenreduzierung: n Verringerung um einen konstanten Betrag (normalerweise um 1); n Reduktion um einen konstanten Faktor (meist 2-fach); n Variable Größenreduzierung. © Pavlovskaya T. A. (SPb NRU ITMO) 23
Methode zur Verringerung der Problemgröße Basiert auf der Verwendung der Beziehung zwischen der Lösung einer gegebenen Instanz des Problems und der Lösung einer kleineren Instanz desselben Problems. Sobald eine solche Beziehung hergestellt ist, kann sie entweder von oben nach unten (rekursiv) oder von unten nach oben (keine Rekursion) verwendet werden. (Beispiel - Potenzieren einer Zahl) Es gibt drei Hauptvarianten der Methode zur Größenreduzierung: n Verringerung um einen konstanten Betrag (normalerweise um 1); n Reduktion um einen konstanten Faktor (meist 2-fach); n Variable Größenreduzierung. © Pavlovskaya T. A. (SPb NRU ITMO) 23
 Insertion Sort Nehmen wir an, dass das Problem des Sortierens eines Arrays von Dimensionen n-1 gelöst wurde. Dann muss noch An an der richtigen Stelle eingefügt werden: n Sweeping des Arrays von links nach rechts n Sweeping des Arrays von rechts nach links n Verwenden einer binären Suche nach dem Einfügepunkt n Obwohl Insertion Sort auf einem rekursiven Ansatz basiert, wird es so sein effizienter, es von unten nach oben (iterativ) zu implementieren. © Pavlovskaya T. A. (SPb NRU ITMO) 24
Insertion Sort Nehmen wir an, dass das Problem des Sortierens eines Arrays von Dimensionen n-1 gelöst wurde. Dann muss noch An an der richtigen Stelle eingefügt werden: n Sweeping des Arrays von links nach rechts n Sweeping des Arrays von rechts nach links n Verwenden einer binären Suche nach dem Einfügepunkt n Obwohl Insertion Sort auf einem rekursiven Ansatz basiert, wird es so sein effizienter, es von unten nach oben (iterativ) zu implementieren. © Pavlovskaya T. A. (SPb NRU ITMO) 24
 Pseudocode-Implementierung für i = 1 bis n - 1 do v = 0 und A[j] > v do A
Pseudocode-Implementierung für i = 1 bis n - 1 do v = 0 und A[j] > v do A
 Effizienz der Einfügesortierung n Schlechtester Fall: führt so viele Vergleiche durch wie die Auswahlsortierung n Bester Fall (für das anfänglich sortierte Array): Der Vergleich wird nur einmal für jeden Durchgang der äußeren Schleife durchgeführt n Durchschnittlicher Fall (zufälliges Array): durchgeführt ~2 Mal weniger Vergleiche als bei einem absteigenden Array. Dass. , der durchschnittliche Fall ist 2 mal besser als der schlimmste Fall. Zusammen mit der hervorragenden Leistung für fast sortierte Arrays unterscheidet dies Insertion Sort von anderen elementaren (Auswahl- und Bubble-) Algorithmen. n Modifikation der Methode - gleichzeitiges Einfügen mehrerer Elemente, die vor dem Einfügen sortiert werden. n Eine Erweiterung von Insertion Sort, Shellsort, bietet einen noch besseren Algorithmus zum Sortieren ziemlich großer Dateien. © Pawlowskaja T. A. (SPb NRU ITMO) 26
Effizienz der Einfügesortierung n Schlechtester Fall: führt so viele Vergleiche durch wie die Auswahlsortierung n Bester Fall (für das anfänglich sortierte Array): Der Vergleich wird nur einmal für jeden Durchgang der äußeren Schleife durchgeführt n Durchschnittlicher Fall (zufälliges Array): durchgeführt ~2 Mal weniger Vergleiche als bei einem absteigenden Array. Dass. , der durchschnittliche Fall ist 2 mal besser als der schlimmste Fall. Zusammen mit der hervorragenden Leistung für fast sortierte Arrays unterscheidet dies Insertion Sort von anderen elementaren (Auswahl- und Bubble-) Algorithmen. n Modifikation der Methode - gleichzeitiges Einfügen mehrerer Elemente, die vor dem Einfügen sortiert werden. n Eine Erweiterung von Insertion Sort, Shellsort, bietet einen noch besseren Algorithmus zum Sortieren ziemlich großer Dateien. © Pawlowskaja T. A. (SPb NRU ITMO) 26

 Erzeugung kombinatorischer Objekte n Die wichtigsten Arten kombinatorischer Objekte sind Permutationen, Kombinationen und Teilmengen einer gegebenen Menge. n Meist entstehen sie bei Aufgaben, die einer Überlegung bedürfen Verschiedene Optionen Auswahl. n Darüber hinaus gibt es die Konzepte der Platzierung und Partitionierung. © Pawlowskaja T. A. (SPb NRU ITMO) 28
Erzeugung kombinatorischer Objekte n Die wichtigsten Arten kombinatorischer Objekte sind Permutationen, Kombinationen und Teilmengen einer gegebenen Menge. n Meist entstehen sie bei Aufgaben, die einer Überlegung bedürfen Verschiedene Optionen Auswahl. n Darüber hinaus gibt es die Konzepte der Platzierung und Partitionierung. © Pawlowskaja T. A. (SPb NRU ITMO) 28
 Permutationserzeugung Anzahl der Permutationen n Gegeben sei eine n-elementige Menge (Menge). n Jedes Element kann den ersten Platz in der Permutation einnehmen, dh es gibt n Möglichkeiten, das erste Element auszuwählen. Es sind (n-1) Elemente übrig, um das zweite Element in der Permutation auszuwählen (es gibt (n-1) Möglichkeiten, das zweite Element auszuwählen). n Es bleiben (n-2) Elemente übrig, um das dritte Element in der Permutation auszuwählen usw. n Insgesamt kann eine geordnete Menge mit n Elementen erhalten werden: auf folgende Weise
Permutationserzeugung Anzahl der Permutationen n Gegeben sei eine n-elementige Menge (Menge). n Jedes Element kann den ersten Platz in der Permutation einnehmen, dh es gibt n Möglichkeiten, das erste Element auszuwählen. Es sind (n-1) Elemente übrig, um das zweite Element in der Permutation auszuwählen (es gibt (n-1) Möglichkeiten, das zweite Element auszuwählen). n Es bleiben (n-2) Elemente übrig, um das dritte Element in der Permutation auszuwählen usw. n Insgesamt kann eine geordnete Menge mit n Elementen erhalten werden: auf folgende Weise
 Anwendung der Größenreduktionsmethode auf das Problem, alle Permutationen von n zu erhalten. Der Einfachheit halber nehmen wir an, dass die Menge der zu permutierenden Elemente die Menge der ganzen Zahlen von 1 bis n ist. n Die Aufgabe des kleineren ist es, alle (n - 1) zu erzeugen! Permutationen. n Unter der Annahme, dass es gelöst wurde, können wir eine Lösung für das größere Problem erhalten, indem wir n an jeder der n möglichen Positionen unter den Elementen jeder der Permutationen von n - 1 Elementen einfügen. n Alle auf diese Weise erhaltenen Permutationen werden unterschiedlich sein, und ihre Gesamtzahl: n(n- 1)! =n! n Sie können n in zuvor generierte Permutationen von links nach rechts oder von rechts nach links einfügen. Es ist vorteilhaft, von rechts nach links zu beginnen und die Richtung jedes Mal zu ändern, wenn Sie zu einer neuen Permutation des Satzes (1, . . . , n - 1) wechseln. © Pawlowskaja T. A. (SPb NRU ITMO) 30
Anwendung der Größenreduktionsmethode auf das Problem, alle Permutationen von n zu erhalten. Der Einfachheit halber nehmen wir an, dass die Menge der zu permutierenden Elemente die Menge der ganzen Zahlen von 1 bis n ist. n Die Aufgabe des kleineren ist es, alle (n - 1) zu erzeugen! Permutationen. n Unter der Annahme, dass es gelöst wurde, können wir eine Lösung für das größere Problem erhalten, indem wir n an jeder der n möglichen Positionen unter den Elementen jeder der Permutationen von n - 1 Elementen einfügen. n Alle auf diese Weise erhaltenen Permutationen werden unterschiedlich sein, und ihre Gesamtzahl: n(n- 1)! =n! n Sie können n in zuvor generierte Permutationen von links nach rechts oder von rechts nach links einfügen. Es ist vorteilhaft, von rechts nach links zu beginnen und die Richtung jedes Mal zu ändern, wenn Sie zu einer neuen Permutation des Satzes (1, . . . , n - 1) wechseln. © Pawlowskaja T. A. (SPb NRU ITMO) 30
 Beispiel (Aufwärtsgenerierung von Permutationen) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 31
Beispiel (Aufwärtsgenerierung von Permutationen) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 31
 Johnson-Trotter-Algorithmus Der Begriff eines mobilen Elements wird eingeführt. Jedem Element ist ein Pfeil zugeordnet, ein Element gilt als beweglich, wenn der Pfeil auf ein kleineres Nachbarelement zeigt. n Initialisieren Sie die erste Permutation mit dem Wert 1 2. . . n (alle Pfeile nach links) n solange es eine Handynummer gibt k do n Finden Sie die größte Handynummer k tauschen Sie k und die benachbarte Nummer, auf die der Pfeil zeigt k n ITMO) 32
Johnson-Trotter-Algorithmus Der Begriff eines mobilen Elements wird eingeführt. Jedem Element ist ein Pfeil zugeordnet, ein Element gilt als beweglich, wenn der Pfeil auf ein kleineres Nachbarelement zeigt. n Initialisieren Sie die erste Permutation mit dem Wert 1 2. . . n (alle Pfeile nach links) n solange es eine Handynummer gibt k do n Finden Sie die größte Handynummer k tauschen Sie k und die benachbarte Nummer, auf die der Pfeil zeigt k n ITMO) 32
 Lexikographische Reihenfolge n Sei die erste Permutation (zB 1234). n So finden Sie jeweils das nächste Paar: 1. Scannen Sie die aktuelle Permutation von rechts nach links auf der Suche nach dem ersten Paar benachbarte Elemente so dass a[i]
Lexikographische Reihenfolge n Sei die erste Permutation (zB 1234). n So finden Sie jeweils das nächste Paar: 1. Scannen Sie die aktuelle Permutation von rechts nach links auf der Suche nach dem ersten Paar benachbarte Elemente so dass a[i]
 Ein Beispiel zum Verständnis des Algorithmus
Ein Beispiel zum Verständnis des Algorithmus
 Die Anzahl aller Permutationen von n Elementen Р(n) = n! © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 35
Die Anzahl aller Permutationen von n Elementen Р(n) = n! © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 35
 Teilmengen n Eine Menge A ist eine Teilmenge einer Menge B, wenn jedes Element, das zu A gehört, auch zu B gehört: A B oder A B n Jede Menge ist ihre eigene Teilmenge. Die leere Menge ist eine Teilmenge einer beliebigen Menge. n Die Menge aller Teilmengen wird mit 2 A bezeichnet (sie wird auch Potenzmenge, Potenzmenge, Potenzmenge, Boolean, Exponentialmenge genannt). n Die Anzahl der Teilmengen einer endlichen Menge bestehend aus n Elementen ist 2 n (siehe Beweis in Wikipedia) © Pavlovskaya T. A. (SPb NRU ITMO) 36
Teilmengen n Eine Menge A ist eine Teilmenge einer Menge B, wenn jedes Element, das zu A gehört, auch zu B gehört: A B oder A B n Jede Menge ist ihre eigene Teilmenge. Die leere Menge ist eine Teilmenge einer beliebigen Menge. n Die Menge aller Teilmengen wird mit 2 A bezeichnet (sie wird auch Potenzmenge, Potenzmenge, Potenzmenge, Boolean, Exponentialmenge genannt). n Die Anzahl der Teilmengen einer endlichen Menge bestehend aus n Elementen ist 2 n (siehe Beweis in Wikipedia) © Pavlovskaya T. A. (SPb NRU ITMO) 36
 Generierung aller Teilmengen n Wenden wir die Methode an, das Problem um 1 zu verkleinern. n Alle Teilmengen A = (a 1, . . . , an) können in zwei Gruppen unterteilt werden - diejenigen, die das Element an enthalten, und diejenigen das nicht. n Die erste Gruppe besteht aus allen Teilmengen (a 1, . . . , an-1); alle Elemente der zweiten Gruppe können durch Hinzufügen des Elements an zu den Teilmengen der ersten Gruppe erhalten werden. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) Zeilen: 000 001 010 011 100 101 110 111 n Andere Ordnungen: dicht; Gray-Code: n 000 001 010 111 100 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 37
Generierung aller Teilmengen n Wenden wir die Methode an, das Problem um 1 zu verkleinern. n Alle Teilmengen A = (a 1, . . . , an) können in zwei Gruppen unterteilt werden - diejenigen, die das Element an enthalten, und diejenigen das nicht. n Die erste Gruppe besteht aus allen Teilmengen (a 1, . . . , an-1); alle Elemente der zweiten Gruppe können durch Hinzufügen des Elements an zu den Teilmengen der ersten Gruppe erhalten werden. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) Zeilen: 000 001 010 011 100 101 110 111 n Andere Ordnungen: dicht; Gray-Code: n 000 001 010 111 100 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 37
 Gray-Codes erzeugen n Ein Gray-Code für n Bits kann rekursiv aus einem Code für n-1 Bits aufgebaut werden durch: n Schreiben der Codes in umgekehrter Reihenfolge n Verketten der ursprünglichen Liste und der umgekehrten Liste n Anhängen von 0 an den Anfang jedes Codes in der ursprünglichen Liste und 1 an den Anfang der Codes in der umgekehrten Liste. Beispiel: n Codes für n = 2 Bit: 00, 01, 10 n Umgekehrte Codeliste: 10, 11, 00 n Kombinierte Liste: 00, 01, 10, 11, 00 n Nullen zur Anfangsliste hinzugefügt: 000, 001, 010 , 11, 00 n Einheiten, die der invertierten Liste hinzugefügt wurden: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 38
Gray-Codes erzeugen n Ein Gray-Code für n Bits kann rekursiv aus einem Code für n-1 Bits aufgebaut werden durch: n Schreiben der Codes in umgekehrter Reihenfolge n Verketten der ursprünglichen Liste und der umgekehrten Liste n Anhängen von 0 an den Anfang jedes Codes in der ursprünglichen Liste und 1 an den Anfang der Codes in der umgekehrten Liste. Beispiel: n Codes für n = 2 Bit: 00, 01, 10 n Umgekehrte Codeliste: 10, 11, 00 n Kombinierte Liste: 00, 01, 10, 11, 00 n Nullen zur Anfangsliste hinzugefügt: 000, 001, 010 , 11, 00 n Einheiten, die der invertierten Liste hinzugefügt wurden: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 38
 K-Element-Teilmengen n Die Anzahl der k-Element-Teilmengen n (0 k n) wird als Anzahl der Kombinationen (Binomialkoeffizient) bezeichnet: n Die direkte Lösung ist wegen des schnellen Wachstums der Fakultät ineffizient. n Die Generierung von k-elementigen Teilmengen erfolgt in der Regel in lexikographischer Reihenfolge (bei zwei beliebigen Teilmengen wird zuerst diejenige erzeugt, deren Elementindizes verwendet werden können, um eine kleinere k-stellige Zahl im n zu bilden -äres Zahlensystem). n Methode: n das erste Element einer Teilmenge der Kardinalität k kann jedes der Elemente sein, beginnend mit dem ersten und endend mit dem (n-k+1)-ten. n Nachdem der Index des ersten Elements der Teilmenge festgelegt ist, müssen k-1 Elemente aus Elementen mit größeren Indizes als dem ersten ausgewählt werden. n Des Weiteren wird das Problem in ähnlicher Weise auf eine kleinere Dimension reduziert, bis niedrigstes Level Rekursion wählt nicht das letzte Element aus, wonach die ausgewählte Teilmenge gedruckt oder verarbeitet werden kann. © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 39
K-Element-Teilmengen n Die Anzahl der k-Element-Teilmengen n (0 k n) wird als Anzahl der Kombinationen (Binomialkoeffizient) bezeichnet: n Die direkte Lösung ist wegen des schnellen Wachstums der Fakultät ineffizient. n Die Generierung von k-elementigen Teilmengen erfolgt in der Regel in lexikographischer Reihenfolge (bei zwei beliebigen Teilmengen wird zuerst diejenige erzeugt, deren Elementindizes verwendet werden können, um eine kleinere k-stellige Zahl im n zu bilden -äres Zahlensystem). n Methode: n das erste Element einer Teilmenge der Kardinalität k kann jedes der Elemente sein, beginnend mit dem ersten und endend mit dem (n-k+1)-ten. n Nachdem der Index des ersten Elements der Teilmenge festgelegt ist, müssen k-1 Elemente aus Elementen mit größeren Indizes als dem ersten ausgewählt werden. n Des Weiteren wird das Problem in ähnlicher Weise auf eine kleinere Dimension reduziert, bis niedrigstes Level Rekursion wählt nicht das letzte Element aus, wonach die ausgewählte Teilmenge gedruckt oder verarbeitet werden kann. © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 39
 Beispiel: Kombinationen von 6 bis 3 #include const int N = 6, K = 3; int a[K]; void rec(int i) ( if (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
Beispiel: Kombinationen von 6 bis 3 #include const int N = 6, K = 3; int a[K]; void rec(int i) ( if (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
 Eigenschaften von Kombinationen n Jede n-elementige Teilmenge einer gegebenen Elementmenge entspricht einer und nur einer n-k-elementigen Teilmenge derselben Menge: n © Pavlovskaya T. A. (SPb NRU ITMO) 41
Eigenschaften von Kombinationen n Jede n-elementige Teilmenge einer gegebenen Elementmenge entspricht einer und nur einer n-k-elementigen Teilmenge derselben Menge: n © Pavlovskaya T. A. (SPb NRU ITMO) 41
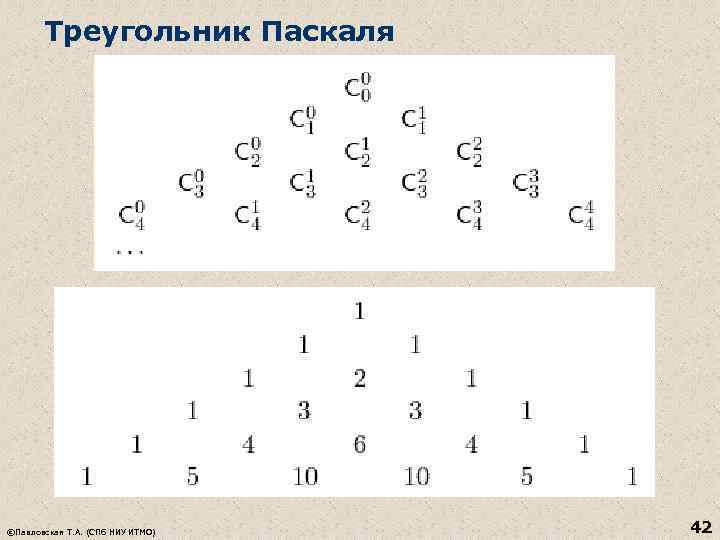

 Platzierungen n Eine Platzierung von n Elementen mal m ist eine Folge, die aus m verschiedenen Elementen einer n-elementigen Menge besteht (Kombinationen, die aus gegebenen n Elementen mal m Elementen bestehen und sich entweder in den Elementen selbst oder in der Reihenfolge der Elemente unterscheiden ) Der Unterschied in den Definitionen von Kombinationen und Platzierungen: n Eine Kombination ist eine Teilmenge, die m Elemente von n enthält (die Reihenfolge der Elemente ist nicht wichtig). n Platzierung ist eine Folge, die m Elemente von n enthält (die Reihenfolge der Elemente ist wichtig). Beim Bilden einer Sequenz ist die Reihenfolge der Elemente wichtig, und beim Bilden einer Teilmenge ist die Reihenfolge nicht wichtig. © Pawlowskaja T. A. (SPb. GU ITMO) 44
Platzierungen n Eine Platzierung von n Elementen mal m ist eine Folge, die aus m verschiedenen Elementen einer n-elementigen Menge besteht (Kombinationen, die aus gegebenen n Elementen mal m Elementen bestehen und sich entweder in den Elementen selbst oder in der Reihenfolge der Elemente unterscheiden ) Der Unterschied in den Definitionen von Kombinationen und Platzierungen: n Eine Kombination ist eine Teilmenge, die m Elemente von n enthält (die Reihenfolge der Elemente ist nicht wichtig). n Platzierung ist eine Folge, die m Elemente von n enthält (die Reihenfolge der Elemente ist wichtig). Beim Bilden einer Sequenz ist die Reihenfolge der Elemente wichtig, und beim Bilden einer Teilmenge ist die Reihenfolge nicht wichtig. © Pawlowskaja T. A. (SPb. GU ITMO) 44
 Anzahl der Stellen n Anzahl der Stellen von n bis m: Beispiel 1: Wie viele zweistellige Zahlen gibt es, bei denen die Zehnerstelle und die Einerstelle unterschiedlich und ungerade sind? Hauptsatz: (1, 3, 5, 7, 9) - ungerade Ziffern, n = 5 n Verbindung - zweistellige Zahl m = 2, die Reihenfolge ist wichtig, daher ist dies eine Platzierung von "aus fünf mal zwei". n Permutationen können als Spezialfall von Platzierungen mit m=n betrachtet werden. Beispiel 2: Auf wie viele Arten kann eine Flagge aus drei horizontalen Streifen unterschiedlicher Farbe gebildet werden, wenn ein Material aus fünf Farben vorhanden ist? © Pawlowskaja T. A. (SPb NRU ITMO) 45
Anzahl der Stellen n Anzahl der Stellen von n bis m: Beispiel 1: Wie viele zweistellige Zahlen gibt es, bei denen die Zehnerstelle und die Einerstelle unterschiedlich und ungerade sind? Hauptsatz: (1, 3, 5, 7, 9) - ungerade Ziffern, n = 5 n Verbindung - zweistellige Zahl m = 2, die Reihenfolge ist wichtig, daher ist dies eine Platzierung von "aus fünf mal zwei". n Permutationen können als Spezialfall von Platzierungen mit m=n betrachtet werden. Beispiel 2: Auf wie viele Arten kann eine Flagge aus drei horizontalen Streifen unterschiedlicher Farbe gebildet werden, wenn ein Material aus fünf Farben vorhanden ist? © Pawlowskaja T. A. (SPb NRU ITMO) 45
 Belegungen mit Wiederholungen n Belegungen mit Wiederholungen aus n Elementen der Menge E=(a 1, a 2, . an mindestens einer Stelle haben sie unterschiedliche Elemente der Menge E. n Die Anzahl der unterschiedlichen Platzierungen mit Wiederholungen von n bis k ist gleich nk. © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 46
Belegungen mit Wiederholungen n Belegungen mit Wiederholungen aus n Elementen der Menge E=(a 1, a 2, . an mindestens einer Stelle haben sie unterschiedliche Elemente der Menge E. n Die Anzahl der unterschiedlichen Platzierungen mit Wiederholungen von n bis k ist gleich nk. © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 46
 Partitionierung von Mengen n Partitionierung einer Menge ist ihre Darstellung als Vereinigung beliebiger Betrag paarweise disjunkte Teilmengen. n Anzahl der ungeordneten Zerlegungen einer n-elementigen Menge in k Teile - Stirlingzahl 2. Art: n Anzahl der geordneten Zerlegungen einer n-elementigen Menge in m Teile fester Größe - Multinomialkoeffizient: n Die Anzahl aller ungeordneten Partitionen einer n-elementigen Menge ist durch die Bell-Zahl gegeben: © Pavlovskaya T. A. (SPb NRU ITMO) 47
Partitionierung von Mengen n Partitionierung einer Menge ist ihre Darstellung als Vereinigung beliebiger Betrag paarweise disjunkte Teilmengen. n Anzahl der ungeordneten Zerlegungen einer n-elementigen Menge in k Teile - Stirlingzahl 2. Art: n Anzahl der geordneten Zerlegungen einer n-elementigen Menge in m Teile fester Größe - Multinomialkoeffizient: n Die Anzahl aller ungeordneten Partitionen einer n-elementigen Menge ist durch die Bell-Zahl gegeben: © Pavlovskaya T. A. (SPb NRU ITMO) 47
 Verfahren zum Reduzieren um einen konstanten Faktor n Beispiel: Binäre Suche n Solche Algorithmen sind logarithmisch und, da sie sehr schnell sind, ziemlich selten. Methode der Reduktion um einen variablen Faktor n Beispiele: Suche und Einfügen in einen binären Suchbaum, Interpolationssuche: © Pavlovskaya T. A. (SPb. GU ITMO) 48
Verfahren zum Reduzieren um einen konstanten Faktor n Beispiel: Binäre Suche n Solche Algorithmen sind logarithmisch und, da sie sehr schnell sind, ziemlich selten. Methode der Reduktion um einen variablen Faktor n Beispiele: Suche und Einfügen in einen binären Suchbaum, Interpolationssuche: © Pavlovskaya T. A. (SPb. GU ITMO) 48
 Effizienzanalyse n Die Interpolationssuche erfordert im Durchschnitt weniger als log 2 n+1 Schlüsselvergleiche, wenn eine Liste mit n Zufallswerten durchsucht wird. n Diese Funktion wächst so langsam, dass sie für alle realen praktischen Werte von n als Konstante betrachtet werden kann. n Im ungünstigsten Fall degeneriert die Interpolationssuche jedoch in eine lineare Suche, die als die schlechtestmögliche angesehen wird. n Die Interpolationssuche eignet sich am besten für große Dateien und für Anwendungen, bei denen der Vergleich oder Zugriff auf Daten teuer ist. © Pawlowskaja T. A. (SPb NRU ITMO) 49
Effizienzanalyse n Die Interpolationssuche erfordert im Durchschnitt weniger als log 2 n+1 Schlüsselvergleiche, wenn eine Liste mit n Zufallswerten durchsucht wird. n Diese Funktion wächst so langsam, dass sie für alle realen praktischen Werte von n als Konstante betrachtet werden kann. n Im ungünstigsten Fall degeneriert die Interpolationssuche jedoch in eine lineare Suche, die als die schlechtestmögliche angesehen wird. n Die Interpolationssuche eignet sich am besten für große Dateien und für Anwendungen, bei denen der Vergleich oder Zugriff auf Daten teuer ist. © Pawlowskaja T. A. (SPb NRU ITMO) 49
 Transformationsmethode n Es besteht darin, dass die Aufgabeninstanz in eine andere transformiert wird, die aus dem einen oder anderen Grund einfacher zu lösen ist. n Es gibt drei Hauptvarianten dieser Methode: © Pavlovskaya T. A. (SPb NRU ITMO) 50
Transformationsmethode n Es besteht darin, dass die Aufgabeninstanz in eine andere transformiert wird, die aus dem einen oder anderen Grund einfacher zu lösen ist. n Es gibt drei Hauptvarianten dieser Methode: © Pavlovskaya T. A. (SPb NRU ITMO) 50
 Beispiel 1: Überprüfen der Eindeutigkeit von Elementen in einem Array n Ein Brute-Force-Algorithmus vergleicht alle Elemente paarweise, bis zwei identische Elemente gefunden werden oder bis alle möglichen Paare untersucht wurden. Im schlimmsten Fall ist der Wirkungsgrad quadratisch. n Sie können die Lösung des Problems auch auf andere Weise angehen - sortieren Sie zuerst das Array und vergleichen Sie dann nur aufeinanderfolgende Elemente. n Die Laufzeit des Algorithmus ist die Summe aus der Sortierzeit und der Zeit zur Prüfung benachbarter Elemente. n Wenn Sie verwenden guter Algorithmus Sortieren wird der gesamte Algorithmus zur Überprüfung der Eindeutigkeit von Array-Elementen ebenfalls eine Effizienz von O (n log n) haben © Pavlovskaya T. A. (SPb NRU ITMO) 51
Beispiel 1: Überprüfen der Eindeutigkeit von Elementen in einem Array n Ein Brute-Force-Algorithmus vergleicht alle Elemente paarweise, bis zwei identische Elemente gefunden werden oder bis alle möglichen Paare untersucht wurden. Im schlimmsten Fall ist der Wirkungsgrad quadratisch. n Sie können die Lösung des Problems auch auf andere Weise angehen - sortieren Sie zuerst das Array und vergleichen Sie dann nur aufeinanderfolgende Elemente. n Die Laufzeit des Algorithmus ist die Summe aus der Sortierzeit und der Zeit zur Prüfung benachbarter Elemente. n Wenn Sie verwenden guter Algorithmus Sortieren wird der gesamte Algorithmus zur Überprüfung der Eindeutigkeit von Array-Elementen ebenfalls eine Effizienz von O (n log n) haben © Pavlovskaya T. A. (SPb NRU ITMO) 51