Metóda hrubej sily je priamy prístup k riešeniu
problém, zvyčajne založený priamo na problémovom vyhlásení a definíciách pojmov, ktoré používa.
Algoritmus hrubej sily na riešenie všeobecného problému vyhľadávania sa nazýva sekvenčné vyhľadávanie. Tento algoritmus jednoducho porovnáva prvky daného zoznamu s vyhľadávacím kľúčom, kým sa nenájde prvok so zadanou hodnotou kľúča (úspešné vyhľadávanie), alebo sa preskúma celý zoznam, ale požadovaný prvok sa nenájde (neúspešné vyhľadávanie). Často sa používa jednoduchý dodatočný trik: ak pridáte vyhľadávací kľúč na koniec zoznamu, vyhľadávanie bude určite úspešné, preto môžete v každej iterácii algoritmu odstrániť kontrolu dokončenia zoznamu. Nasleduje pseudokód takejto vylepšenej verzie; predpokladá sa, že vstupné údaje sú vo forme poľa.
Ak je pôvodný zoznam zoradený, možno použiť ešte jedno vylepšenie: vyhľadávanie v takomto zozname je možné zastaviť hneď, ako sa nájde prvok, ktorý nie je menší ako vyhľadávací kľúč. Sekvenčné vyhľadávanie poskytuje vynikajúcu ilustráciu prístupu hrubej sily s jeho charakteristickými silnými stránkami (jednoduchosť) a slabými stránkami (nízka účinnosť).
Je celkom zrejmé, že doba chodu tohto algoritmu sa môže značne líšiť pre rovnaký zoznam veľkosti n. V najhoršom prípade, t.j. keď zoznam neobsahuje požadovaný prvok alebo keď sa prvok nachádza na poslednom mieste v zozname, algoritmus vykoná najväčší počet operácií porovnávania kľúčov so všetkými n prvkami zoznamu: C(n) = n.
1.2. Rabinov algoritmus.
Rabinov algoritmus je modifikáciou lineárneho algoritmu, je založený na veľmi jednoduchej myšlienke:
„Predstavte si, že v slove A, ktorého dĺžka je m, hľadáme vzor X dĺžky n. Vystrihneme „okno“ veľkosti n a posunieme ho po vstupnom slove. Zaujíma nás, či sa slovo v „boxe“ zhoduje s daným vzorom. Porovnávanie písmen na dlhú dobu. Namiesto toho opravíme nejakú číselnú funkciu na slová dĺžky n, potom sa problém zredukuje na porovnávanie čísel, ktoré je nepochybne rýchlejšie. Ak sú hodnoty tejto funkcie v slove v „okne“ a na vzorke odlišné, potom neexistuje žiadna zhoda. Iba ak sú hodnoty rovnaké, je potrebné postupne kontrolovať zhodu písmena po písmene.
Tento algoritmus vykonáva lineárny prechod riadkom (n krokov) a lineárny prechod celým textom (m krokov), takže celkový čas chodu je O(n+m). Zároveň neberieme do úvahy časovú náročnosť výpočtu hašovacej funkcie, keďže podstatou algoritmu je, že táto funkcia je tak ľahko vypočítateľná, že jej činnosť neovplyvňuje celkovú činnosť algoritmu.
Rabinov algoritmus a sekvenčný vyhľadávací algoritmus sú algoritmy s najnižšími nákladmi na prácu, takže sú vhodné na použitie pri riešení určitej triedy problémov. Tieto algoritmy však nie sú najoptimálnejšie.
1.3. Algoritmus Knuth-Morris-Pratt (kmp).
Metóda KMP využíva predspracovanie požadovaného reťazca, a to: na jeho základe sa vytvorí prefixová funkcia. V tomto prípade sa používa nasledujúca myšlienka: ak je predpona (aka prípona) reťazca dĺžky i dlhšia ako jeden znak, potom je to aj predpona podreťazca dĺžky i-1. Skontrolujeme teda predponu predchádzajúceho podreťazca, ak sa nezhoduje, tak predponu jeho predpony atď. Tým nájdeme najväčšiu požadovanú predponu. Ďalšia otázka na zodpovedanie je: prečo je čas vykonania procedúry lineárny, pretože má vnorenú slučku? No, po prvé, priradenie prefixovej funkcie nastane presne m-krát, zvyšok času sa premenná k zmení. Preto je celkový čas chodu programu O(n+m), teda lineárny čas.
a ďalšia funkcia: function show(pos, path, w, h) ( var canvas = document.getElementById("canID"); // získanie objektu canvas var ctx = canvas.getContext("2d"); // má vlastnosť context kresba var x0 = 10, y0 = 10; // poloha ľavého horného rohu plátna mapy.width = w+2*x0; canvas.height = h+2*y0; // zmena veľkosti plátna (o niečo väčšie než w x v) ctx .beginPath(); // začnite kresliť čiaru ctx.moveTo(x0+pos.x,y0+pos.y)// presun do 0. mesta for(var i=1; i Príklad výsledok volania funkcie je zobrazený vpravo. Význam príkazov na kreslenie by mal byť jasný z ich názvu a komentárov v kóde. Najprv sa nakreslí uzavretá lomená čiara (cesta obchodníka). Potom kruhy miest a navrchu im čísla miest. Práca s priekopou v JavaScripte je trochu ťažkopádna a v budúcnosti budeme používať triedu kresliť, ktorý túto prácu zjednodušuje a zároveň umožňuje získať obrázky vo formáte svg.
Busta v časovači
Implementácia vyhľadávacieho algoritmu na nájdenie najkratšej cesty v časovači nie je náročná. Ak chcete uložiť najlepšiu cestu do poľa minWay, napíšte funkciu na kopírovanie hodnôt prvkov poľa src do poľa des:
Funkcia copy(des, src) ( if(des.length !== src.length) des = new Array(src.length); for(var i=0; i
Mám matematický problém, ktorý riešim metódou pokus-omyl (myslím, že sa to volá hrubá sila) a program funguje dobre, keď je tam viacero parametrov, ale keď sa pridáva viac premenných/údajov, jeho spustenie trvá dlhšie a dlhšie.
Môj problém je, že zatiaľ čo prototyp funguje, je užitočný pre tisíce premenných a veľké súbory údajov; tak by ma zaujímalo, či je možné škálovať algoritmy hrubej sily. Ako môžem pristupovať k jeho škálovaniu?
3 odpovede
Vo všeobecnosti môžete kvantifikovať, ako dobre sa bude algoritmus škálovať, pomocou veľkej výstupnej notácie na analýzu rýchlosti rastu. Keď hovoríte, že váš algoritmus beží pod „hrubou silou“, nie je jasné, do akej miery sa bude škálovať. Ak vaše riešenie „hrubej sily“ funguje na základe zoznamu všetkých možných podmnožín alebo kombinácií súboru údajov, potom sa takmer určite nebude škálovať (bude mať asymptotickú zložitosť O(2n) alebo O(n!). Ak vaše riešenie hrubou silou funguje tak, že nájdete všetky páry prvkov a otestujete ich, môže sa celkom dobre škálovať (O(n 2)). Avšak bez Ďalšie informácie ako váš algoritmus funguje, je ťažké povedať.
Podľa definície sú algoritmy hrubej sily hlúpe. Budete na tom oveľa lepšie s inteligentnejším algoritmom (ak nejaký máte). Lepší algoritmus zníži prácu, ktorú je potrebné vykonať, dúfajme, že do takej miery, že to môžete urobiť bez potreby „škálovania“ na viacerých počítačoch.
Bez ohľadu na algoritmus príde bod, keď je množstvo údajov alebo požadovaný výkon spracovania také veľké, že musíte použiť niečo ako Hadoop. Vo všeobecnosti tu však skutočne hovoríme o veľkých dátach. S jedným PC sa už v dnešnej dobe dá urobiť veľa.
Algoritmus na riešenie tohto problému je uzavretý s procesom, ktorý študujeme pre manuálne matematické delenie, ako aj pre prevod z desiatkovej na iný základ, ako je osmičkový alebo hexadecimálny, s výnimkou toho, že v dvoch príkladoch sa uvažuje len s jedným kanonickým riešením.
Aby ste sa uistili, že sa rekurzia dokončí, je dôležité objednať dátové pole. Pre efektívnosť a obmedzenie počtu rekurzií je tiež dôležité začať s vyššími hodnotami údajov.
Konkrétne tu je rekurzívna implementácia Java pre tento problém - s kópiou vektora výsledného koeficientu pre každú rekurziu, ako sa teoreticky očakáva.
Importovať java.util.Arrays; public class Solver ( public static void main(String args) ( int target_sum = 100; // predpoklad: zoradené hodnoty!! int data = new int ( 5, 10, 20, 25, 40, 50 ); / / výsledkový vektor, init na 0 int coeff = new int; Arrays.fill(coeff, 0); partialSum(data.length - 1, target_sum, coeff, data); ) private static void printResult(int coeff, int data) ( for ( int i = coeff.length - 1; i >= 0; i--) ( if (coeff[i] > 0) ( System.out.print(data[i] + " * " + coeff[i] + " "); ) ) System.out.println(); ) private static void parcialSum(int k, int suma, int coeff, int data) ( int x_k = data[k]; for (int c = suma / x_k ; c >= 0; c--) ( coeff[k] = c; if (c * x_k == súčet) ( printResult(coeff, data); continue; ) else if (k > 0) ( // kontextový výsledok v parametroch , lokálny rozsah metódy int newcoeff = Arrays.copyOf(koeff, coeff.length); čiastočný súčet (k - 1, suma - c * x_k, newcoeff, data); // pre slučku na "c" pokračuje predchádzajúcim obsah koeficientu ) ) ) )
Ale teraz je tento kód v špeciálnom prípade: posledný test hodnota pre každý koeficient je 0, takže nie je potrebná žiadna kópia.
Ako odhad zložitosti môžeme použiť maximálnu hĺbku rekurzívnych hovorov ako data.length * min(( data )) . Samozrejme, že sa nebude dobre škálovať a limitujúcim faktorom bude pamäť sledovania zásobníka (možnosť -Xss JVM). Kód môže zlyhať s chybou pre veľký súbor údajov.
Aby sa predišlo týmto nedostatkom, je nápomocný proces „ukončenia“. Spočíva v nahradení zásobníka volania metódy zásobníkom programu na uloženie kontextu vykonávania pre neskoršie spracovanie. Tu je kód na to:
Importovať java.util.Arrays; import java.util.ArrayDeque; import java.util.Queue; public class NonRecursive ( // nevyhnutná podmienka: zoradené hodnoty!! private static final int data = new int ( 5, 10, 20, 25, 40, 50 ); // Kontext na uloženie prechodného výpočtu alebo statickej triedy riešenia Kontext ( int k; int sum; int coeff; Context(int k, int sum, int coeff) ( this.k = k; this.sum = sum; this.coeff = coeff; ) ) private static void printResult(int coeff ) ( for (int i = coeff.length - 1; i >= 0; i--) ( if (coeff[i] > 0) ( System.out.print(data[i] + " * " + coeff[ i] + " "); ) ) System.out.println(); ) public static void main(String args) ( int target_sum = 100; // vektor výsledku, init na 0 int coeff = new int; Arrays.fill( coeff, 0); // fronta s kontextami na spracovanie Queue
Z môjho pohľadu je ťažké byť efektívnejší pri jedinom vykonaní vlákna - zásobníkový mechanizmus teraz vyžaduje kópie poľa coeff.
Hľadanie podreťazca v reťazci prebieha podľa daného vzoru, t.j. nejaká postupnosť znakov, ktorých dĺžka nepresahuje dĺžku pôvodného reťazca. Úlohou vyhľadávania je určiť, či reťazec obsahuje daný vzor, a v prípade nájdenia zhody uviesť umiestnenie (index) v reťazci.
Algoritmus hrubej sily je najjednoduchší a najpomalší a pozostáva z kontroly všetkých pozícií textu, aby sa zistilo, či sa zhodujú so začiatkom vzoru. Ak sa začiatok vzoru zhoduje, potom sa porovná ďalšie písmeno vo vzore a v texte atď. nie je úplná zhoda vzoru alebo rozdiel v nasledujúcom písmene.
int BFSearch(znak*s, znak*p)
for (int i = 1; strlen(s) - strlen(p); i++)
for (int j = 1; strlen(p); j++)
ak (p[j] != s)
if (j = strlen(p))
Funkcia BFSearch vyhľadá podreťazec p v reťazci s a vráti index prvého znaku podreťazca alebo 0, ak sa podreťazec nenájde. Hoci vo všeobecnosti je táto metóda, ako väčšina metód hrubou silou, neúčinná, v niektorých situáciách je celkom prijateľná.
Najrýchlejší medzi algoritmami všeobecný účel, určený na hľadanie podreťazca v reťazci, je Boyer-Mooreov algoritmus, ktorý vyvinuli dvaja vedci - Boyer (Robert S. Boyer) a Moore (J. Strother Moore), ktorého podstata je nasledovná.
Boyer-Mooreov algoritmus
Najjednoduchšia verzia Boyer-Mooreovho algoritmu pozostáva z nasledujúcich krokov. V prvom kroku sa zostaví tabuľka posunov pre požadovanú vzorku. Postup konštrukcie stola bude popísaný nižšie. Potom sa skombinuje začiatok reťazca a vzor a test začne od posledného znaku vzoru. Ak sa posledný znak vzoru a jemu zodpovedajúci znak reťazca pri prekrytí nezhodujú, vzor sa voči reťazcu posunie o hodnotu získanú z tabuľky ofsetov a porovnanie sa vykoná znova, počnúc od posledný znak vzoru. Ak sa znaky zhodujú, porovnáva sa predposledný znak vzoru atď. Ak sa všetky znaky vzorky zhodujú s prekrývajúcimi sa znakmi reťazca, potom sa podreťazec našiel a vyhľadávanie je ukončené. Ak sa niektorý (nie posledný) znak vzoru nezhoduje s príslušným znakom reťazca, posunieme vzor o jeden znak doprava a začneme znova od posledného znaku. Celý algoritmus sa vykonáva, kým sa nenájde výskyt požadovaného vzoru alebo sa nedosiahne koniec reťazca.
Hodnota posunu v prípade nesúladu posledného znaku sa vypočíta podľa pravidla: posun vzoru musí byť minimálny, aby sa nepremeškal výskyt vzoru v reťazci. Ak sa daný znak reťazca vyskytuje vo vzore, vzor sa posunie tak, aby sa znak reťazca zhodoval s výskytom tohto znaku vo vzore úplne vpravo. Ak vzor tento znak vôbec neobsahuje, vzor sa posunie o hodnotu rovnajúcu sa jeho dĺžke, takže prvý znak vzoru sa prekryje s ďalším znakom testovaného reťazca.
Hodnota posunu pre každý znak vzoru závisí iba od poradia znakov vo vzore, preto je vhodné vopred vypočítať posuny a uložiť ich ako jednorozmerné pole, kde každý znak abecedy zodpovedá relatívnemu posunu. do posledného znaku vzoru. Poďme si vysvetliť všetko vyššie jednoduchý príklad. Nech existuje množina piatich znakov: a, b, c, d, e a musíte nájsť výskyt vzoru "abbad" v reťazci "abeccacbadbabbad". Nasledujúce diagramy znázorňujú všetky fázy vykonávania algoritmu:
Offsetová tabuľka pre vzor „abbad“.
Spustenie vyhľadávania. Posledný znak vzoru sa nezhoduje so znakom superponovaného reťazca. Posuňte vzorku doprava o 5 pozícií:
Tri znaky vzoru sa zhodovali, ale štvrtý nie. Posuňte vzor o jednu pozíciu doprava:
Posledný znak opäť nezodpovedá znaku reťazca. V súlade s tabuľkou posunov posúvame vzorku o 2 pozície:
Opäť posunieme vzorku o 2 pozície:
Teraz v súlade s tabuľkou posunieme vzorku o jednu pozíciu a dostaneme požadovaný výskyt vzorky:
Implementujeme zadaný algoritmus. V prvom rade treba definovať dátový typ "offsetová tabuľka". Pre tabuľku kódov s 256 znakmi by definícia štruktúry vyzerala takto:
BMTable MakeBMTable (char *p)
pre (i = 0; i<= 255; i++) bmt->bmtarr[i] = strlen(p);
pre (i = strlen(p); i<= 1; i--)
if (bmt->bmtarr] == strlen(p))
bmt->bmtarr] = strlen(p)-i;
Teraz napíšme funkciu, ktorá vykoná vyhľadávanie.
int BMSearch(int startpos, char *s, char *p)
pos = startpos + lp - 1;
zatiaľ čo (poz< strlen(s))
if (p != s) poz = poz + bmt->bmtarr];
pre (i = lp - 1; i<= 1; i--)
ak (p[i] != s)
return(pos - lp + 1);
Funkcia BMSearch vráti pozíciu prvého znaku prvého výskytu vzoru p v reťazci s. Ak sa sekvencia p v s nenájde, funkcia vráti 0. Parameter startpos umožňuje určiť pozíciu v reťazci s, od ktorej sa má začať hľadať. To môže byť užitočné, ak chcete nájsť všetky výskyty p v s. Ak chcete hľadať od úplného začiatku reťazca, nastavte startpos na 1. Ak je výsledok vyhľadávania nenulový, potom, aby ste našli ďalší výskyt p v s, nastavte startpos na "predchádzajúci výsledok plus dĺžka vzoru".
Binárne (binárne) vyhľadávanie
Binárne vyhľadávanie sa používa vtedy, keď je vyhľadávané pole už zoradené.
Premenné lb a ub obsahujú ľavú a pravú hranicu segmentu poľa, kde sa nachádza požadovaný prvok. Vyhľadávanie vždy začína štúdiom stredného prvku segmentu. Ak je požadovaná hodnota menšia ako stredný prvok, musíte prejsť na vyhľadávanie v hornej polovici segmentu, kde sú všetky prvky menšie ako práve začiarknuté. Inými slovami, hodnota ub sa stane (m - 1) a polovica pôvodného poľa sa skontroluje v ďalšej iterácii. V dôsledku každej kontroly sa teda oblasť vyhľadávania zmenší na polovicu. Napríklad, ak je v poli 100 čísel, potom sa po prvej iterácii oblasť vyhľadávania zmenší na 50 čísel, po druhom na 25, po treťom na 13, po štvrtom na 7 atď. Ak je dĺžka poľa n, potom približne log 2 n porovnaní stačí na vyhľadanie prvkov v poli.
Metódy vývoja algoritmov n Metóda hrubej sily (“head on”) n Metóda rozkladu n Metóda redukcie veľkosti problému n Transformačná metóda n Dynamické programovanie n Nenásytné metódy n Metódy redukcie vyhľadávania n … © Pavlovskaya T. A. (SPb NRU ITMO) 1

 Prístup hrubou silou n Priamy prístup k riešeniu problému, zvyčajne založený priamo na vyhlásení problému a definíciách pojmov, ktoré používa, jednoduché použitie n Zriedkavo vytvára krásne a efektívne algoritmy n Náklady na vývoj efektívnejšieho algoritmu môžu byť neprijateľné, ak sa má vyriešiť len niekoľko problémových prípadov n Môže byť užitočné pri riešení malých problémových prípadov. n Môže slúžiť ako meradlo na určenie účinnosti iných algoritmov © Pavlovskaya T. A. (SPb NRU ITMO) 3
Prístup hrubou silou n Priamy prístup k riešeniu problému, zvyčajne založený priamo na vyhlásení problému a definíciách pojmov, ktoré používa, jednoduché použitie n Zriedkavo vytvára krásne a efektívne algoritmy n Náklady na vývoj efektívnejšieho algoritmu môžu byť neprijateľné, ak sa má vyriešiť len niekoľko problémových prípadov n Môže byť užitočné pri riešení malých problémových prípadov. n Môže slúžiť ako meradlo na určenie účinnosti iných algoritmov © Pavlovskaya T. A. (SPb NRU ITMO) 3
 n Príklad: výberové triedenie a bublinkové triedenie 28 -5 ©Pavlovskaya T. A. (St. Petersburg NRU ITMO) 16 0 29 3 -4 56 4
n Príklad: výberové triedenie a bublinkové triedenie 28 -5 ©Pavlovskaya T. A. (St. Petersburg NRU ITMO) 16 0 29 3 -4 56 4
 Vyčerpávajúci zoznam je prístupom ku kombinatorickým problémom hrubou silou. Predpokladá: n generovanie všetkých možných prvkov z oblasti definície problému n výber tých, ktoré spĺňajú obmedzenia dané problémovou podmienkou n hľadanie požadovaného prvku (napríklad optimalizácia hodnoty účelovej funkcie problému). Príklady: Problém cestujúceho predajcu: Nájdite najkratšiu cestu cez Zvážte všetky podmnožiny daný set z n objektov pridelených N mestám, takže každé mesto je navštívené, vypočítajte iba celkovú hmotnosť každého z nich, aby ste určili prípustnosť, raz a konečný cieľ je pôvodný. vyberte si z povolenej podmnožiny s maximálnou hmotnosťou. n Získajte všetky možné trasy, vygenerujúc všetky problémy s batohom: ak je daných N položiek danej hmotnosti a stojí batoh, ktorý znesie hmotnosť W. Nahrajte batoh s permutáciami n - 1 medziľahlých miest, počítajte s maximálnymi nákladmi. dĺžku zodpovedajúcich ciest a nájdenie najkratšej z nich. Toto sú NP-ťažké problémy (nie je známy žiadny algoritmus, ktorý by ich riešil v polynomiálnom čase). n © Pavlovskaya T. A. (SPb NRU ITMO) 5
Vyčerpávajúci zoznam je prístupom ku kombinatorickým problémom hrubou silou. Predpokladá: n generovanie všetkých možných prvkov z oblasti definície problému n výber tých, ktoré spĺňajú obmedzenia dané problémovou podmienkou n hľadanie požadovaného prvku (napríklad optimalizácia hodnoty účelovej funkcie problému). Príklady: Problém cestujúceho predajcu: Nájdite najkratšiu cestu cez Zvážte všetky podmnožiny daný set z n objektov pridelených N mestám, takže každé mesto je navštívené, vypočítajte iba celkovú hmotnosť každého z nich, aby ste určili prípustnosť, raz a konečný cieľ je pôvodný. vyberte si z povolenej podmnožiny s maximálnou hmotnosťou. n Získajte všetky možné trasy, vygenerujúc všetky problémy s batohom: ak je daných N položiek danej hmotnosti a stojí batoh, ktorý znesie hmotnosť W. Nahrajte batoh s permutáciami n - 1 medziľahlých miest, počítajte s maximálnymi nákladmi. dĺžku zodpovedajúcich ciest a nájdenie najkratšej z nich. Toto sú NP-ťažké problémy (nie je známy žiadny algoritmus, ktorý by ich riešil v polynomiálnom čase). n © Pavlovskaya T. A. (SPb NRU ITMO) 5

 Metóda rozkladu Tiež známa ako rozdeľuj a panuj: n Inštancia úlohy je rozdelená na niekoľko menších inštancií tej istej úlohy, ideálne rovnakej veľkosti. n Menšie prípady problému sa riešia (zvyčajne rekurzívne, aj keď niekedy sa pre malé prípady používa nejaký iný algoritmus). n V prípade potreby sa riešenie pôvodného problému nájde kombináciou riešení menších inštancií. Metóda rozkladu je ideálna pre paralelné výpočty. © Pavlovskaya T. A. (SPb NRU ITMO) 7
Metóda rozkladu Tiež známa ako rozdeľuj a panuj: n Inštancia úlohy je rozdelená na niekoľko menších inštancií tej istej úlohy, ideálne rovnakej veľkosti. n Menšie prípady problému sa riešia (zvyčajne rekurzívne, aj keď niekedy sa pre malé prípady používa nejaký iný algoritmus). n V prípade potreby sa riešenie pôvodného problému nájde kombináciou riešení menších inštancií. Metóda rozkladu je ideálna pre paralelné výpočty. © Pavlovskaya T. A. (SPb NRU ITMO) 7
 Rovnica rekurzívneho rozkladu n Vo všeobecnom prípade možno inštanciu problému veľkosti n rozdeliť na niekoľko prípadov veľkosti n/b, ktoré je potrebné vyriešiť. n Zovšeobecnená rovnica rekurzívneho rozkladu: (1) n Pre jednoduchosť sa predpokladá, že veľkosť n sa rovná mocnine b. n Poradie rastu závisí od a, b a f. © Pavlovskaya T. A. (SPb NRU ITMO) 8
Rovnica rekurzívneho rozkladu n Vo všeobecnom prípade možno inštanciu problému veľkosti n rozdeliť na niekoľko prípadov veľkosti n/b, ktoré je potrebné vyriešiť. n Zovšeobecnená rovnica rekurzívneho rozkladu: (1) n Pre jednoduchosť sa predpokladá, že veľkosť n sa rovná mocnine b. n Poradie rastu závisí od a, b a f. © Pavlovskaya T. A. (SPb NRU ITMO) 8
 Hlavná dekompozičná veta (1) n Triedu účinnosti algoritmu je možné špecifikovať bez riešenia samotnej rekurzívnej rovnice. n Tento prístup umožňuje stanoviť poradie rastu riešenia bez určovania neznámych faktorov. © Pavlovskaya T. A. (NRU ITMO Petrohradu) 9
Hlavná dekompozičná veta (1) n Triedu účinnosti algoritmu je možné špecifikovať bez riešenia samotnej rekurzívnej rovnice. n Tento prístup umožňuje stanoviť poradie rastu riešenia bez určovania neznámych faktorov. © Pavlovskaya T. A. (NRU ITMO Petrohradu) 9
 Zlúčiť Zoradí dané pole tak, že ho rozdelí na dve polovice, každú polovicu zoradí rekurzívne a zlúči dve zoradené polovice do jedného zoradeného poľa: Zlúčiť (A) ak n>1 Prvá polovica A -> do poľa B Druhá polovica A -> do pole C Mergesort(B) Mergesort(C) Merge(B, C, A) // merge ©Pavlovskaya T. A. (St. Petersburg NRU ITMO) 10
Zlúčiť Zoradí dané pole tak, že ho rozdelí na dve polovice, každú polovicu zoradí rekurzívne a zlúči dve zoradené polovice do jedného zoradeného poľa: Zlúčiť (A) ak n>1 Prvá polovica A -> do poľa B Druhá polovica A -> do pole C Mergesort(B) Mergesort(C) Merge(B, C, A) // merge ©Pavlovskaya T. A. (St. Petersburg NRU ITMO) 10
Src="http://present5.com/presentation/54441564_438337950/image-11.jpg" alt="(!LANG:Mergesort (A) ak n>1 Prvá polovica A -> do poľa B Druhá polovica A"> Mergesort (A) if n>1 Первая половина А -> в массив В Вторая половина А > в массив С Mergesort(B) Mergesort(C) Меrgе(В, С, А) ©Павловская Т. А. (СПб НИУ ИТМО) 11!}
 Zlučovanie polí n Dva indexy polí po inicializácii ukazujú na prvé prvky polí, ktoré sa majú zlúčiť. n Prvky sa porovnajú a menší sa pridá do nového poľa. n Index menšieho prvku sa zvýši (ukazuje na prvok bezprostredne nasledujúci za práve skopírovaným). Táto operácia sa opakuje, kým sa nevyčerpá jedno z polí, ktoré sa majú zlúčiť. Zvyšné prvky druhého poľa sa pridajú na koniec nového poľa. © Pavlovskaya T. A. (SPb NRU ITMO) 12
Zlučovanie polí n Dva indexy polí po inicializácii ukazujú na prvé prvky polí, ktoré sa majú zlúčiť. n Prvky sa porovnajú a menší sa pridá do nového poľa. n Index menšieho prvku sa zvýši (ukazuje na prvok bezprostredne nasledujúci za práve skopírovaným). Táto operácia sa opakuje, kým sa nevyčerpá jedno z polí, ktoré sa majú zlúčiť. Zvyšné prvky druhého poľa sa pridajú na koniec nového poľa. © Pavlovskaya T. A. (SPb NRU ITMO) 12
 Analýza triedenia zlúčením n Dĺžka súboru nech je mocninou 2. n Počet porovnaní kľúčov: C(n) = 2*C(n/2) + Zlúčiť (n) n > 1, C(1)=0 n Zlúčiť (n) = n-1 najhorší prípad (počet porovnaní kľúčov zlúčenia) n Najhorší prípad Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n-1 Cw (n ) (n log n) – podľa hl Veta ©Pavlovskaya T. A. (SPb NRU ITMO) (1) 13
Analýza triedenia zlúčením n Dĺžka súboru nech je mocninou 2. n Počet porovnaní kľúčov: C(n) = 2*C(n/2) + Zlúčiť (n) n > 1, C(1)=0 n Zlúčiť (n) = n-1 najhorší prípad (počet porovnaní kľúčov zlúčenia) n Najhorší prípad Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n-1 Cw (n ) (n log n) – podľa hl Veta ©Pavlovskaya T. A. (SPb NRU ITMO) (1) 13
 n Počet kľúčových porovnaní vykonaných zlučovacím triedením je prinajhoršom veľmi blízko teoretickému minimálnemu počtu porovnaní pre akýkoľvek triediaci algoritmus založený na porovnávaní. n Hlavnou nevýhodou merge sort je potreba dodatočnej pamäte, ktorej množstvo je lineárne úmerné veľkosti vstupných dát. © Pavlovskaya T. A. (SPb NRU ITMO) 14
n Počet kľúčových porovnaní vykonaných zlučovacím triedením je prinajhoršom veľmi blízko teoretickému minimálnemu počtu porovnaní pre akýkoľvek triediaci algoritmus založený na porovnávaní. n Hlavnou nevýhodou merge sort je potreba dodatočnej pamäte, ktorej množstvo je lineárne úmerné veľkosti vstupných dát. © Pavlovskaya T. A. (SPb NRU ITMO) 14
 Rýchle triedenie Na rozdiel od mergesort, ktorý oddeľuje prvky poľa podľa ich pozície v poli, rýchle triedenie oddeľuje prvky poľa podľa ich hodnôt. 28 56 © Pavlovskaya T. A. (Petrohrad NRU ITMO) 1 0 29 3 -4 16 15
Rýchle triedenie Na rozdiel od mergesort, ktorý oddeľuje prvky poľa podľa ich pozície v poli, rýchle triedenie oddeľuje prvky poľa podľa ich hodnôt. 28 56 © Pavlovskaya T. A. (Petrohrad NRU ITMO) 1 0 29 3 -4 16 15
 Opis algoritmu n Výber otočného prvku n Vykonajte permutáciu prvkov na získanie rozdelenia, keď všetky prvky do niektorých pozícií s nepresahujú prvok A [s] a prvky za pozíciou s nie sú menšie ako tento. n Je zrejmé, že po rozdelení je A [s] v konečnej pozícii a dve podpole prvkov pred a za A [s] môžeme zoradiť nezávisle (pomocou rovnakej alebo inej metódy) © Pavlovskaya T. A. (SPb NRU ITMO) 16
Opis algoritmu n Výber otočného prvku n Vykonajte permutáciu prvkov na získanie rozdelenia, keď všetky prvky do niektorých pozícií s nepresahujú prvok A [s] a prvky za pozíciou s nie sú menšie ako tento. n Je zrejmé, že po rozdelení je A [s] v konečnej pozícii a dve podpole prvkov pred a za A [s] môžeme zoradiť nezávisle (pomocou rovnakej alebo inej metódy) © Pavlovskaya T. A. (SPb NRU ITMO) 16
 Postup pre permutáciu prvkov n Efektívna metóda, na základe dvoch prechodov podpolia – zľava doprava a sprava doľava. Pri každom prihrávke sa prvky porovnávajú s pivotom. n Prechod zľava doprava (i) preskočí prvky menšie ako je otočný čap a zastaví sa na prvom prvku, ktorý nie je menší ako čap. n Prejdenie sprava doľava (j) preskočí elementy väčšie ako pivot a zastaví sa na prvom elemente nie viac ako pivot. n Ak sa indexy skenovania nepretínajú, vymeníme nájdené prvky a pokračujeme v priechodoch. n Ak sa indexy pretínajú, vymeníme pivotový prvok s Aj ©Pavlovskaya T. A. (SPb NRU ITMO) 17
Postup pre permutáciu prvkov n Efektívna metóda, na základe dvoch prechodov podpolia – zľava doprava a sprava doľava. Pri každom prihrávke sa prvky porovnávajú s pivotom. n Prechod zľava doprava (i) preskočí prvky menšie ako je otočný čap a zastaví sa na prvom prvku, ktorý nie je menší ako čap. n Prejdenie sprava doľava (j) preskočí elementy väčšie ako pivot a zastaví sa na prvom elemente nie viac ako pivot. n Ak sa indexy skenovania nepretínajú, vymeníme nájdené prvky a pokračujeme v priechodoch. n Ak sa indexy pretínajú, vymeníme pivotový prvok s Aj ©Pavlovskaya T. A. (SPb NRU ITMO) 17
 Efektívnosť rýchleho triedenia n Najlepší prípad: všetky oddiely sú v strede zodpovedajúcich podpolí n V najhoršom prípade sú všetky oddiely také, že jedno z podpolí je prázdne a veľkosť druhého je o 1 menšia ako veľkosť poľa, ktoré má byť delené (kvadratická závislosť). n V priemernom prípade predpokladáme, že rozdelenie je možné vykonať v každej pozícii s rovnakou pravdepodobnosťou: Cavg 2 n ln n 1, 38 n log 2 n © Pavlovskaya T. A. (SPb NRU ITMO) 18
Efektívnosť rýchleho triedenia n Najlepší prípad: všetky oddiely sú v strede zodpovedajúcich podpolí n V najhoršom prípade sú všetky oddiely také, že jedno z podpolí je prázdne a veľkosť druhého je o 1 menšia ako veľkosť poľa, ktoré má byť delené (kvadratická závislosť). n V priemernom prípade predpokladáme, že rozdelenie je možné vykonať v každej pozícii s rovnakou pravdepodobnosťou: Cavg 2 n ln n 1, 38 n log 2 n © Pavlovskaya T. A. (SPb NRU ITMO) 18
 Vylepšenia algoritmov n vylepšené metódy výberu pivot n prechod na jednoduchšie triedenie pre malé podpolia n odstránenie rekurzie Tieto vylepšenia môžu spolu skrátiť čas chodu algoritmu o 20 – 25 % (R. Sedgwick) © Pavlovskaya T. A. (SPb NRU ITMO) 19
Vylepšenia algoritmov n vylepšené metódy výberu pivot n prechod na jednoduchšie triedenie pre malé podpolia n odstránenie rekurzie Tieto vylepšenia môžu spolu skrátiť čas chodu algoritmu o 20 – 25 % (R. Sedgwick) © Pavlovskaya T. A. (SPb NRU ITMO) 19
 Prechádzanie binárnym stromom Toto je ďalší príklad použitia metódy rozkladu n Dopredný prechod navštevuje najprv koreň stromu, potom ľavý a pravý podstrom. n Pri symetrickom prechode sa koreň navštívi po ľavom podstrome, ale pred návštevou pravého. n Pri obchádzaní opačné poradie koreň je navštívený po ľavom a pravom podstrome. © Pavlovskaya T. A. (SPb NRU ITMO) 20
Prechádzanie binárnym stromom Toto je ďalší príklad použitia metódy rozkladu n Dopredný prechod navštevuje najprv koreň stromu, potom ľavý a pravý podstrom. n Pri symetrickom prechode sa koreň navštívi po ľavom podstrome, ale pred návštevou pravého. n Pri obchádzaní opačné poradie koreň je navštívený po ľavom a pravom podstrome. © Pavlovskaya T. A. (SPb NRU ITMO) 20
 Postup prechodu cez strom print_tree(strom); begin print_tree(left_subtree) visit root print_tree(pravý_podstrom) end; 1 6 8 10 20 ©Pavlovskaya T. A. (SPb. GU ITMO) 21 25 30 21
Postup prechodu cez strom print_tree(strom); begin print_tree(left_subtree) visit root print_tree(pravý_podstrom) end; 1 6 8 10 20 ©Pavlovskaya T. A. (SPb. GU ITMO) 21 25 30 21

 Metóda redukcie veľkosti problému Založená na použití vzťahu medzi riešením daného prípadu problému a riešením menšieho prípadu toho istého problému. Akonáhle je takýto vzťah vytvorený, môže byť použitý buď zhora nadol (rekurzívne) alebo zdola nahor (bez rekurzie). (príklad - zvýšenie čísla na mocninu) Existujú tri hlavné varianty metódy zmenšenia veľkosti: n zníženie o konštantnú hodnotu (zvyčajne o 1); n zníženie o konštantný faktor (zvyčajne 2-krát); n variabilné zmenšenie veľkosti. © Pavlovskaya T. A. (SPb NRU ITMO) 23
Metóda redukcie veľkosti problému Založená na použití vzťahu medzi riešením daného prípadu problému a riešením menšieho prípadu toho istého problému. Akonáhle je takýto vzťah vytvorený, môže byť použitý buď zhora nadol (rekurzívne) alebo zdola nahor (bez rekurzie). (príklad - zvýšenie čísla na mocninu) Existujú tri hlavné varianty metódy zmenšenia veľkosti: n zníženie o konštantnú hodnotu (zvyčajne o 1); n zníženie o konštantný faktor (zvyčajne 2-krát); n variabilné zmenšenie veľkosti. © Pavlovskaya T. A. (SPb NRU ITMO) 23
 Vloženie triedenia Predpokladajme, že problém triedenia poľa rozmerov n-1 bol vyriešený. Potom zostáva vložiť An na správne miesto: n Rozmetanie poľa zľava doprava n Rozmetanie poľa sprava doľava n Použitie binárneho vyhľadávania pre bod vloženia n Hoci je triedenie vkladania založené na rekurzívnom prístupe, bude efektívnejšie ju implementovať zdola nahor (iteratívne). © Pavlovskaya T. A. (SPb NRU ITMO) 24
Vloženie triedenia Predpokladajme, že problém triedenia poľa rozmerov n-1 bol vyriešený. Potom zostáva vložiť An na správne miesto: n Rozmetanie poľa zľava doprava n Rozmetanie poľa sprava doľava n Použitie binárneho vyhľadávania pre bod vloženia n Hoci je triedenie vkladania založené na rekurzívnom prístupe, bude efektívnejšie ju implementovať zdola nahor (iteratívne). © Pavlovskaya T. A. (SPb NRU ITMO) 24
 Implementácia pseudokódu pre i = 1 až n - 1 do v = 0 a A[j] > v do A
Implementácia pseudokódu pre i = 1 až n - 1 do v = 0 a A[j] > v do A
 Efektívnosť zoradenia vloženia n Najhorší prípad: vykoná rovnaký počet porovnaní ako triedenie výberu n Najlepší prípad (pre pôvodne zoradené pole): porovnanie sa vykoná iba raz pre každý prechod vonkajšej slučky n Priemerný prípad (náhodné pole): vykoná sa ~2-krát menej porovnaní ako v prípade zostupného poľa. To. , priemerný prípad je 2-krát lepší ako najhorší prípad. Spolu s vynikajúcim výkonom pre takmer triedené polia to odlišuje triedenie vkladania od iných elementárnych (výberových a bublinových) algoritmov. n Úprava metódy - vkladanie viacerých prvkov súčasne, ktoré sa pred vložením triedia. n Rozšírenie triedenia vkladania, Shellsort, poskytuje ešte lepší algoritmus na triedenie pomerne veľkých súborov. © Pavlovskaya T. A. (SPb NRU ITMO) 26
Efektívnosť zoradenia vloženia n Najhorší prípad: vykoná rovnaký počet porovnaní ako triedenie výberu n Najlepší prípad (pre pôvodne zoradené pole): porovnanie sa vykoná iba raz pre každý prechod vonkajšej slučky n Priemerný prípad (náhodné pole): vykoná sa ~2-krát menej porovnaní ako v prípade zostupného poľa. To. , priemerný prípad je 2-krát lepší ako najhorší prípad. Spolu s vynikajúcim výkonom pre takmer triedené polia to odlišuje triedenie vkladania od iných elementárnych (výberových a bublinových) algoritmov. n Úprava metódy - vkladanie viacerých prvkov súčasne, ktoré sa pred vložením triedia. n Rozšírenie triedenia vkladania, Shellsort, poskytuje ešte lepší algoritmus na triedenie pomerne veľkých súborov. © Pavlovskaya T. A. (SPb NRU ITMO) 26

 Generovanie kombinatorických objektov n Najdôležitejšími typmi kombinatorických objektov sú permutácie, kombinácie a podmnožiny danej množiny. n Zvyčajne vznikajú pri úlohách, ktoré si vyžadujú zváženie rôzne možnosti výber. n Okrem toho existujú koncepty umiestnenia a rozdelenia. © Pavlovskaya T. A. (SPb NRU ITMO) 28
Generovanie kombinatorických objektov n Najdôležitejšími typmi kombinatorických objektov sú permutácie, kombinácie a podmnožiny danej množiny. n Zvyčajne vznikajú pri úlohách, ktoré si vyžadujú zváženie rôzne možnosti výber. n Okrem toho existujú koncepty umiestnenia a rozdelenia. © Pavlovskaya T. A. (SPb NRU ITMO) 28
 Generovanie permutácií Počet permutácií n Nech je daná n-prvková množina (množina). n Akýkoľvek prvok môže obsadiť prvé miesto v permutácii, to znamená, že existuje n spôsobov, ako vybrať prvý prvok. Zostáva (n-1) prvkov na výber druhého prvku v permutácii (existuje (n-1) spôsobov, ako vybrať druhý prvok). n Zostáva (n-2) prvkov na výber tretieho prvku v permutácii atď. n Celkovo možno získať n-prvkovú usporiadanú množinu: nasledujúcimi spôsobmi
Generovanie permutácií Počet permutácií n Nech je daná n-prvková množina (množina). n Akýkoľvek prvok môže obsadiť prvé miesto v permutácii, to znamená, že existuje n spôsobov, ako vybrať prvý prvok. Zostáva (n-1) prvkov na výber druhého prvku v permutácii (existuje (n-1) spôsobov, ako vybrať druhý prvok). n Zostáva (n-2) prvkov na výber tretieho prvku v permutácii atď. n Celkovo možno získať n-prvkovú usporiadanú množinu: nasledujúcimi spôsobmi
 Aplikácia metódy zmenšenia veľkosti na problém získania všetkých permutácií n Pre jednoduchosť predpokladáme, že množina prvkov, ktoré sa majú permutovať, je množina celých čísel od 1 do n. n Úlohou menšieho je vygenerovať všetky (n - 1)! permutácií. n Za predpokladu, že je vyriešený, môžeme získať riešenie väčšieho problému vložením n do každej z n možných pozícií medzi prvky každej z permutácií n - 1 prvkov. n Všetky takto získané permutácie budú rôzne a ich celkový počet: n(n- 1)! =n! n Do predtým vygenerovaných permutácií môžete vložiť n zľava doprava alebo sprava doľava. Je výhodné začať sprava doľava a zmeniť smer zakaždým, keď prejdete na novú permutáciu množiny (1, . . . , n - 1). © Pavlovskaya T. A. (SPb NRU ITMO) 30
Aplikácia metódy zmenšenia veľkosti na problém získania všetkých permutácií n Pre jednoduchosť predpokladáme, že množina prvkov, ktoré sa majú permutovať, je množina celých čísel od 1 do n. n Úlohou menšieho je vygenerovať všetky (n - 1)! permutácií. n Za predpokladu, že je vyriešený, môžeme získať riešenie väčšieho problému vložením n do každej z n možných pozícií medzi prvky každej z permutácií n - 1 prvkov. n Všetky takto získané permutácie budú rôzne a ich celkový počet: n(n- 1)! =n! n Do predtým vygenerovaných permutácií môžete vložiť n zľava doprava alebo sprava doľava. Je výhodné začať sprava doľava a zmeniť smer zakaždým, keď prejdete na novú permutáciu množiny (1, . . . , n - 1). © Pavlovskaya T. A. (SPb NRU ITMO) 30
 Príklad (generovanie permutácií smerom nahor) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 31
Príklad (generovanie permutácií smerom nahor) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 31
 Johnson-Trotterov algoritmus Zavádza sa pojem mobilného prvku. Ku každému prvku je priradená šípka, prvok sa považuje za mobilný, ak šípka ukazuje na menší susedný prvok. n Inicializujte prvú permutáciu s hodnotou 1 2. . . n (všetky šípky doľava) n kým je mobilné číslo k do n Nájdite najväčšie mobilné číslo k Vymeňte k a susedné číslo, na ktoré ukazuje šípka k n ITMO) 32
Johnson-Trotterov algoritmus Zavádza sa pojem mobilného prvku. Ku každému prvku je priradená šípka, prvok sa považuje za mobilný, ak šípka ukazuje na menší susedný prvok. n Inicializujte prvú permutáciu s hodnotou 1 2. . . n (všetky šípky doľava) n kým je mobilné číslo k do n Nájdite najväčšie mobilné číslo k Vymeňte k a susedné číslo, na ktoré ukazuje šípka k n ITMO) 32
 Lexikografický poriadok n Nech je prvá permutácia (napríklad 1234). n Ak chcete nájsť každú ďalšiu: 1. Naskenujte aktuálnu permutáciu sprava doľava pri hľadaní prvého páru susedné prvky tak, že [i]
Lexikografický poriadok n Nech je prvá permutácia (napríklad 1234). n Ak chcete nájsť každú ďalšiu: 1. Naskenujte aktuálnu permutáciu sprava doľava pri hľadaní prvého páru susedné prvky tak, že [i]
 Príklad na pochopenie algoritmu
Príklad na pochopenie algoritmu
 Počet všetkých permutácií n prvkov Р(n) = n! © Pavlovskaya T. A. (NRU ITMO Petrohradu) 35
Počet všetkých permutácií n prvkov Р(n) = n! © Pavlovskaya T. A. (NRU ITMO Petrohradu) 35
 Podmnožiny n Množina A je podmnožinou množiny B, ak niektorý prvok patriaci do A patrí aj do B: A B alebo A B n Každá množina je vlastnou podmnožinou. Prázdna množina je podmnožinou ľubovoľnej množiny. n Množinu všetkých podmnožín označujeme 2 A (nazýva sa aj výkonová súprava, výkonová súprava, výkonová súprava, booleovská, exponenciálna množina). n Počet podmnožín konečnej množiny pozostávajúcej z n prvkov je 2 n (pozri dôkaz vo Wikipédii) © Pavlovskaya T. A. (SPb NRU ITMO) 36
Podmnožiny n Množina A je podmnožinou množiny B, ak niektorý prvok patriaci do A patrí aj do B: A B alebo A B n Každá množina je vlastnou podmnožinou. Prázdna množina je podmnožinou ľubovoľnej množiny. n Množinu všetkých podmnožín označujeme 2 A (nazýva sa aj výkonová súprava, výkonová súprava, výkonová súprava, booleovská, exponenciálna množina). n Počet podmnožín konečnej množiny pozostávajúcej z n prvkov je 2 n (pozri dôkaz vo Wikipédii) © Pavlovskaya T. A. (SPb NRU ITMO) 36
 Generovanie všetkých podmnožín n Aplikujme metódu zmenšenia veľkosti problému o 1. n Všetky podmnožiny A = (a 1, . . . , an) môžeme rozdeliť do dvoch skupín - tie, ktoré obsahujú prvok an a tie že nie. n Prvá skupina sú všetky podmnožiny (a 1,..., an-1); všetky prvky druhej skupiny možno získať pridaním prvku a do podmnožín prvej skupiny. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) riadky: 000 001 010 011 100 101 110 111 n Ostatné objednávky: husté; Sivý kód: n 000 001 010 111 100 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 37
Generovanie všetkých podmnožín n Aplikujme metódu zmenšenia veľkosti problému o 1. n Všetky podmnožiny A = (a 1, . . . , an) môžeme rozdeliť do dvoch skupín - tie, ktoré obsahujú prvok an a tie že nie. n Prvá skupina sú všetky podmnožiny (a 1,..., an-1); všetky prvky druhej skupiny možno získať pridaním prvku a do podmnožín prvej skupiny. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) riadky: 000 001 010 011 100 101 110 111 n Ostatné objednávky: husté; Sivý kód: n 000 001 010 111 100 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 37
 Generovanie Grayových kódov n Grayov kód pre n bitov možno rekurzívne zostaviť z kódu pre n-1 bitov: n zápisom kódov v opačnom poradí n zreťazením pôvodného zoznamu a obráteného zoznamu n pripojením 0 na začiatok každého kódu v pôvodný zoznam a 1 na začiatok kódov v opačnom zozname. Príklad: n Kódy pre n = 2 bity: 00, 01, 10 n Obrátený zoznam kódov: 10, 11, 00 n Kombinovaný zoznam: 00, 01, 10, 11, 00 n Do pôvodného zoznamu pridané nuly: 000, 001, 010 , 11, 00 n Jednotky pridané do prevráteného zoznamu: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 38
Generovanie Grayových kódov n Grayov kód pre n bitov možno rekurzívne zostaviť z kódu pre n-1 bitov: n zápisom kódov v opačnom poradí n zreťazením pôvodného zoznamu a obráteného zoznamu n pripojením 0 na začiatok každého kódu v pôvodný zoznam a 1 na začiatok kódov v opačnom zozname. Príklad: n Kódy pre n = 2 bity: 00, 01, 10 n Obrátený zoznam kódov: 10, 11, 00 n Kombinovaný zoznam: 00, 01, 10, 11, 00 n Do pôvodného zoznamu pridané nuly: 000, 001, 010 , 11, 00 n Jednotky pridané do prevráteného zoznamu: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (St. Petersburg NRU ITMO) 38
 K-prvkové podmnožiny n Počet k-prvkových podmnožín n (0 k n) sa nazýva počet kombinácií (binomický koeficient): n Priame riešenie je neefektívne pre rýchly rast faktoriálu. n Generovanie k-prvkových podmnožín sa spravidla uskutočňuje v lexikografickom poradí (pre ľubovoľné dve podmnožiny sa ako prvá vygeneruje tá, ktorej indexy prvkov môžu tvoriť menšie k-ciferné číslo v n-árnom čísle systém). n Metóda: n prvým prvkom podmnožiny mohutnosti k môže byť ktorýkoľvek z prvkov, počnúc prvým a končiac (n-k+1)-tým. n Po zafixovaní indexu prvého prvku podmnožiny zostáva vybrať k-1 prvkov z prvkov s indexmi väčšími ako prvý. n Ďalej, podobne, zmenšenie problému na menší rozmer až najnižšia úroveň rekurzia nevyberie posledný prvok, po ktorom je možné vytlačiť alebo spracovať zvolenú podmnožinu. © Pavlovskaya T. A. (NRU ITMO Petrohradu) 39
K-prvkové podmnožiny n Počet k-prvkových podmnožín n (0 k n) sa nazýva počet kombinácií (binomický koeficient): n Priame riešenie je neefektívne pre rýchly rast faktoriálu. n Generovanie k-prvkových podmnožín sa spravidla uskutočňuje v lexikografickom poradí (pre ľubovoľné dve podmnožiny sa ako prvá vygeneruje tá, ktorej indexy prvkov môžu tvoriť menšie k-ciferné číslo v n-árnom čísle systém). n Metóda: n prvým prvkom podmnožiny mohutnosti k môže byť ktorýkoľvek z prvkov, počnúc prvým a končiac (n-k+1)-tým. n Po zafixovaní indexu prvého prvku podmnožiny zostáva vybrať k-1 prvkov z prvkov s indexmi väčšími ako prvý. n Ďalej, podobne, zmenšenie problému na menší rozmer až najnižšia úroveň rekurzia nevyberie posledný prvok, po ktorom je možné vytlačiť alebo spracovať zvolenú podmnožinu. © Pavlovskaya T. A. (NRU ITMO Petrohradu) 39
 Príklad: kombinácie 6 až 3 #include const int N = 6, K = 3; int a[K]; void rec(int i) ( ak (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
Príklad: kombinácie 6 až 3 #include const int N = 6, K = 3; int a[K]; void rec(int i) ( ak (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
 Vlastnosti kombinácií n každej n-prvkovej podmnožine danej množiny prvkov zodpovedá jedna a len jedna n-prvková podmnožina tej istej množiny: n © Pavlovskaya T. A. (SPb NRU ITMO) 41
Vlastnosti kombinácií n každej n-prvkovej podmnožine danej množiny prvkov zodpovedá jedna a len jedna n-prvková podmnožina tej istej množiny: n © Pavlovskaya T. A. (SPb NRU ITMO) 41
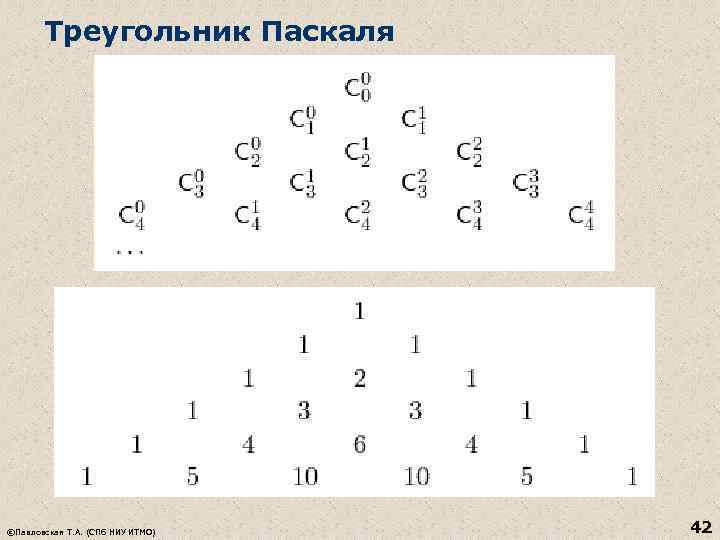

 Umiestnenia n Umiestnenie n prvkov podľa m je postupnosť pozostávajúca z m rôznych prvkov nejakej n-prvkovej množiny (kombinácie, ktoré sa skladajú z daných n prvkov pomocou m prvkov a líšia sa buď samotnými prvkami, alebo poradím prvkov ) Rozdiel v definíciách kombinácií a umiestnení: n Kombinácia je podmnožina obsahujúca m prvkov z n (poradie prvkov nie je dôležité). n Umiestnenie je postupnosť obsahujúca m prvkov z n (poradie prvkov je dôležité). Pri vytváraní postupnosti je dôležité poradie prvkov a pri vytváraní podmnožiny poradie nie je dôležité. © Pavlovskaya T. A. (SPb. GU ITMO) 44
Umiestnenia n Umiestnenie n prvkov podľa m je postupnosť pozostávajúca z m rôznych prvkov nejakej n-prvkovej množiny (kombinácie, ktoré sa skladajú z daných n prvkov pomocou m prvkov a líšia sa buď samotnými prvkami, alebo poradím prvkov ) Rozdiel v definíciách kombinácií a umiestnení: n Kombinácia je podmnožina obsahujúca m prvkov z n (poradie prvkov nie je dôležité). n Umiestnenie je postupnosť obsahujúca m prvkov z n (poradie prvkov je dôležité). Pri vytváraní postupnosti je dôležité poradie prvkov a pri vytváraní podmnožiny poradie nie je dôležité. © Pavlovskaya T. A. (SPb. GU ITMO) 44
 Počet umiestnení n Počet umiestnení od n do m: Príklad 1: Koľko je dvojciferných čísel, v ktorých sú desiatky a jedničky rôzne a nepárne? Hlavná sada: (1, 3, 5, 7, 9) - nepárne číslice, n=5 n Zapojenie - dvojmiestne číslo m=2, dôležité je poradie, ide teda o umiestnenie "od päť po dvoch". n Permutácie možno považovať za špeciálny prípad umiestnení s m=n Príklad 2: Koľkými spôsobmi možno vytvoriť vlajku pozostávajúcu z troch vodorovných pruhov rôznych farieb, ak existuje materiál piatich farieb? © Pavlovskaya T. A. (SPb NRU ITMO) 45
Počet umiestnení n Počet umiestnení od n do m: Príklad 1: Koľko je dvojciferných čísel, v ktorých sú desiatky a jedničky rôzne a nepárne? Hlavná sada: (1, 3, 5, 7, 9) - nepárne číslice, n=5 n Zapojenie - dvojmiestne číslo m=2, dôležité je poradie, ide teda o umiestnenie "od päť po dvoch". n Permutácie možno považovať za špeciálny prípad umiestnení s m=n Príklad 2: Koľkými spôsobmi možno vytvoriť vlajku pozostávajúcu z troch vodorovných pruhov rôznych farieb, ak existuje materiál piatich farieb? © Pavlovskaya T. A. (SPb NRU ITMO) 45
 Alokácie s opakovaniami n Usporiadania s opakovaniami z n prvkov množiny E=(a 1, a 2, . . . , an) po k - ľubovoľná konečná postupnosť pozostávajúca z k prvkov danej množiny E. n aspoň na jednom mieste majú rôzne prvky množiny E. n Počet rôznych umiestnení s opakovaniami od n do k sa rovná nk. © Pavlovskaya T. A. (NRU ITMO Petrohradu) 46
Alokácie s opakovaniami n Usporiadania s opakovaniami z n prvkov množiny E=(a 1, a 2, . . . , an) po k - ľubovoľná konečná postupnosť pozostávajúca z k prvkov danej množiny E. n aspoň na jednom mieste majú rôzne prvky množiny E. n Počet rôznych umiestnení s opakovaniami od n do k sa rovná nk. © Pavlovskaya T. A. (NRU ITMO Petrohradu) 46
 Rozdelenie množín n Rozdelenie množiny je jej znázornenie ako zväzok ľubovoľná suma párovo disjunktné podmnožiny. n Počet neusporiadaných dielikov n-prvkovej množiny na k dielov - Stirlingovo číslo 2. druhu: n Počet usporiadaných dielikov n-prvkovej množiny na m dielov pevnej veľkosti - multinomický koeficient: n Počet všetkých neusporiadaných partície n-prvkovej množiny sú dané Bellovým číslom: © Pavlovskaya T. A. (SPb NRU ITMO) 47
Rozdelenie množín n Rozdelenie množiny je jej znázornenie ako zväzok ľubovoľná suma párovo disjunktné podmnožiny. n Počet neusporiadaných dielikov n-prvkovej množiny na k dielov - Stirlingovo číslo 2. druhu: n Počet usporiadaných dielikov n-prvkovej množiny na m dielov pevnej veľkosti - multinomický koeficient: n Počet všetkých neusporiadaných partície n-prvkovej množiny sú dané Bellovým číslom: © Pavlovskaya T. A. (SPb NRU ITMO) 47
 Metóda redukcie o konštantný faktor n Príklad: binárne vyhľadávanie n Takéto algoritmy sú logaritmické a keďže sú veľmi rýchle, sú pomerne zriedkavé. Metóda redukcie premenným faktorom n Príklady: vyhľadávanie a vkladanie do binárneho vyhľadávacieho stromu, interpolačné vyhľadávanie: © Pavlovskaya T. A. (SPb. GU ITMO) 48
Metóda redukcie o konštantný faktor n Príklad: binárne vyhľadávanie n Takéto algoritmy sú logaritmické a keďže sú veľmi rýchle, sú pomerne zriedkavé. Metóda redukcie premenným faktorom n Príklady: vyhľadávanie a vkladanie do binárneho vyhľadávacieho stromu, interpolačné vyhľadávanie: © Pavlovskaya T. A. (SPb. GU ITMO) 48
 Analýza účinnosti n Interpolačné vyhľadávanie vyžaduje v priemere menej ako log 2 n+1 kľúčových porovnaní pri prehľadávaní zoznamu n náhodných hodnôt. n Táto funkcia rastie tak pomaly, že pre všetky reálne praktické hodnoty n ju možno považovať za konštantu. n V najhoršom prípade sa však interpolačné vyhľadávanie zvrhne na lineárne vyhľadávanie, ktoré sa považuje za najhoršie možné. n Interpolačné vyhľadávanie sa najlepšie používa pre veľké súbory a pre aplikácie, kde je porovnávanie alebo prístup k údajom nákladná operácia. © Pavlovskaya T. A. (SPb NRU ITMO) 49
Analýza účinnosti n Interpolačné vyhľadávanie vyžaduje v priemere menej ako log 2 n+1 kľúčových porovnaní pri prehľadávaní zoznamu n náhodných hodnôt. n Táto funkcia rastie tak pomaly, že pre všetky reálne praktické hodnoty n ju možno považovať za konštantu. n V najhoršom prípade sa však interpolačné vyhľadávanie zvrhne na lineárne vyhľadávanie, ktoré sa považuje za najhoršie možné. n Interpolačné vyhľadávanie sa najlepšie používa pre veľké súbory a pre aplikácie, kde je porovnávanie alebo prístup k údajom nákladná operácia. © Pavlovskaya T. A. (SPb NRU ITMO) 49
 Transformačná metóda n Spočíva v tom, že inštancia úlohy sa transformuje na inú, ktorá je z jedného alebo druhého dôvodu ľahšie riešiteľná. n Existujú tri hlavné varianty tejto metódy: © Pavlovskaya T. A. (SPb NRU ITMO) 50
Transformačná metóda n Spočíva v tom, že inštancia úlohy sa transformuje na inú, ktorá je z jedného alebo druhého dôvodu ľahšie riešiteľná. n Existujú tri hlavné varianty tejto metódy: © Pavlovskaya T. A. (SPb NRU ITMO) 50
 Príklad 1: Kontrola jedinečnosti prvkov v poli n Algoritmus hrubej sily párovo porovnáva všetky prvky, kým sa nenájdu dva identické prvky, alebo kým sa nepreskúmajú všetky možné dvojice. V najhoršom prípade je účinnosť kvadratická. n K riešeniu úlohy môžete pristupovať aj inak – najprv pole zoradiť a potom porovnávať iba po sebe idúce prvky. n Čas chodu algoritmu je súčtom času triedenia a času na kontrolu susedných prvkov. n Ak používate dobrý algoritmus triedenie, celý algoritmus na kontrolu jedinečnosti prvkov poľa bude mať tiež účinnosť O (n log n) © Pavlovskaya T. A. (SPb NRU ITMO) 51
Príklad 1: Kontrola jedinečnosti prvkov v poli n Algoritmus hrubej sily párovo porovnáva všetky prvky, kým sa nenájdu dva identické prvky, alebo kým sa nepreskúmajú všetky možné dvojice. V najhoršom prípade je účinnosť kvadratická. n K riešeniu úlohy môžete pristupovať aj inak – najprv pole zoradiť a potom porovnávať iba po sebe idúce prvky. n Čas chodu algoritmu je súčtom času triedenia a času na kontrolu susedných prvkov. n Ak používate dobrý algoritmus triedenie, celý algoritmus na kontrolu jedinečnosti prvkov poľa bude mať tiež účinnosť O (n log n) © Pavlovskaya T. A. (SPb NRU ITMO) 51