Qu'est-ce qu'uri. Qu'est-ce qu'une URL et comment l'utiliser. Le spam le plus dangereux est personnel
30.12.2020
Tutoriels Windows
Les utilisateurs se demandent souvent quelle est l'URL d'un fichier (site Web), comment la trouver et quelle est la valeur d'un tel accessoire. Notre article apportera les réponses nécessaires.
Quelle est l'URL
Uniform Resource Locator signifie "indicateur d'emplacement de site Web". Un identifiant URL se compose d'un nom de domaine et d'un chemin vers une page spécifique avec le nom de son fichier. L'inventeur de l'URL était Tim Berners-Lee, membre du Conseil européen de la guerre nucléaire à Genève. Au moment de sa création en 1990, une URL de site est simplement l'adresse sur le système où se trouve le fichier. Pour connaître l'URL du site, il suffit de regarder barre d'adresse, et pour déterminer l'adresse du fichier, vous devez vous rendre sur menu contextuel en cliquant sur l'objet correspondant avec le bouton droit de la souris. Présentant de nombreux avantages, notamment la disponibilité de la navigation sur le Web, une telle adresse présente également un inconvénient - la possibilité de travailler exclusivement avec l'alphabet latin, certains symboles et chiffres. S'il est nécessaire d'utiliser l'alphabet cyrillique, une conversion spéciale est effectuée.
Variétés d'URL
Statique - n'implique pas de modifications de la page.
URL dynamique - ce que c'est, vous pouvez comprendre si vous imaginez un formulaire de recherche ou un autre outil de navigation dans lequel des informations sont générées en fonction des demandes entrantes.
Une adresse avec un ID de session qui est ajouté chaque fois que les utilisateurs visitent la page.
La signification de l'URL dans la promotion SEO
Les moteurs de recherche prennent en compte les clés incluses dans l'URL. Le plus grand impact sur la promotion des moteurs de recherche mots clés dans le domaine et les sous-domaines.
Si l'adresse du site est informative, elle augmente également le classement. Le robot de recherche est très susceptible de l'émettre en réponse à une requête d'actualité.
L'URL qui correspond à la requête est mise en surbrillance dans Résultats de recherche en gras, attirant davantage l'attention et augmentant le taux de clics.
Selon diverses sources, de 50 à 95 % de tous les e-mails dans le monde sont des spams de cyber-escrocs. Les objectifs de l'envoi de telles lettres sont simples: infecter l'ordinateur du destinataire avec un virus, voler les mots de passe des utilisateurs, forcer une personne à transférer de l'argent «à une association caritative», saisir des données personnelles carte bancaire ou envoyer des numérisations de documents.
Le spam est souvent ennuyeux à première vue : mise en page tordue, texte traduit automatiquement, formulaires de saisie de mot de passe directement dans la ligne d'objet. Mais il existe des lettres malveillantes qui ont l'air décentes, jouent subtilement sur les émotions d'une personne et ne soulèvent aucun doute sur leur véracité.
L'article parlera de 4 types de lettres frauduleuses, qui sont le plus souvent suivies par les Russes.
1. Lettres des « organismes gouvernementaux »



Les fraudeurs peuvent se faire passer pour des contribuables fonds de pension, Rospotrebnadzor, station sanitaire et épidémiologique et autres organisations gouvernementales. Pour plus de persuasion, des filigranes, des scans de sceaux et des symboles d'état sont insérés dans la lettre. Le plus souvent, la tâche des criminels est d'effrayer une personne et de la convaincre d'ouvrir un fichier contenant un virus en pièce jointe.
Il s'agit généralement d'un rançongiciel ou d'un bloqueur Windows qui désactive l'ordinateur et vous oblige à envoyer un SMS payant pour reprendre le travail. Un fichier malveillant peut être déguisé en une ordonnance du tribunal ou une citation à comparaître pour appeler le chef de l'organisation.
La peur et la curiosité éteignent la conscience de l'utilisateur. Les forums de comptables décrivent des cas où des employés d'organisations ont apporté des fichiers contenant des virus sur leur ordinateur personnel, car ils ne pouvaient pas les ouvrir au bureau en raison d'un antivirus.
Parfois, les escrocs vous demandent d'envoyer des documents en réponse à une lettre afin de collecter des informations sur l'entreprise qui seront utiles pour d'autres stratagèmes de fraude. L'année dernière, un groupe d'escrocs a réussi à escroquer beaucoup de gens en utilisant la distraction "demande papier fax".
Lorsqu'un comptable ou un responsable a lu ceci, il a immédiatement maudit le bureau des impôts : "Il y a des mammouths assis là, e-mine !" et a changé ses pensées de la lettre elle-même à la solution problèmes techniques avec dépêche.
2. Lettres de "banques"


Les bloqueurs Windows et les ransomwares peuvent se cacher dans de fausses lettres non seulement d'organisations gouvernementales, mais aussi de banques. Les messages "Un prêt a été contracté à votre nom, consultez le procès" peuvent vraiment faire peur et provoquer une grande envie d'ouvrir le dossier.
De plus, une personne peut être persuadée d'entrer un faux Espace personnel, offrant de voir les bonus accumulés ou de recevoir un prix qu'il a gagné à la loterie Sberbank.
Moins souvent, les escrocs envoient des factures pour payer les frais de service et les intérêts supplémentaires sur un prêt, pour 50 à 200 roubles, qui sont plus faciles à payer qu'à gérer.
3. Lettres de "collègues"/"partenaires"
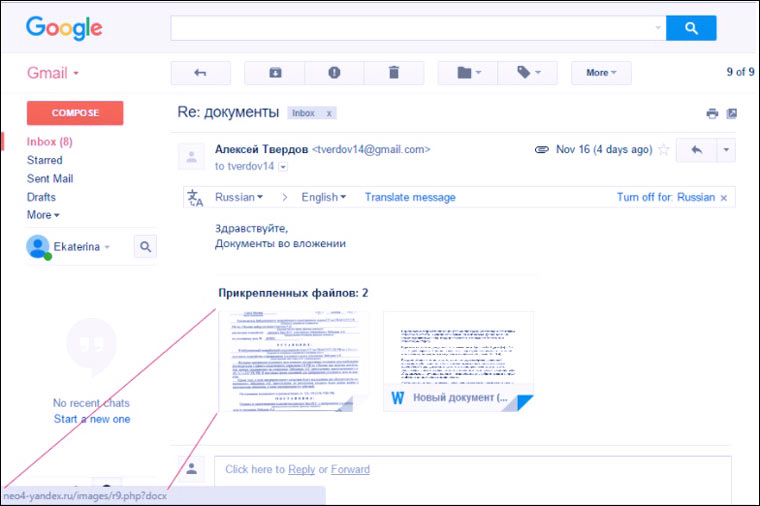
Certaines personnes reçoivent des dizaines de lettres commerciales avec des documents pendant la journée de travail. Avec une telle charge, vous pouvez facilement tomber dans le piège "Re:" dans la ligne d'objet et oublier que vous n'avez pas encore correspondu avec cette personne.
Surtout si le champ empoisonneur dit "Alexander Ivanov", "Ekaterina Smirnova" ou tout autre simple Nom russe qui ne restent absolument pas dans la mémoire d'une personne qui travaille constamment avec les gens.
Si l'objectif des fraudeurs n'est pas de collecter des paiements par SMS pour déverrouiller Windows, mais de nuire à une entreprise particulière, des lettres contenant des virus et des liens de phishing peuvent être envoyées au nom de vrais employés. Une liste des employés peut être collectée sur les réseaux sociaux ou consultée sur le site Internet de l'entreprise.
Si une personne voit une lettre dans la boîte aux lettres d'une personne d'un département voisin, alors elle ne la regarde pas de près, elle peut même ignorer les avertissements de l'antivirus et ouvrir le fichier coûte que coûte.
4. Lettres de Google/Yandex/Mail


Google envoie parfois des e-mails aux propriétaires Boîtes Gmail que quelqu'un a essayé de se connecter à votre compte ou que l'espace sur le Google Drive. Les fraudeurs les copient avec succès et forcent les utilisateurs à entrer des mots de passe sur de faux sites.
De fausses lettres de "l'administration du service" sont également reçues par les utilisateurs de Yandex.Mail, Mail.ru et d'autres services de messagerie. Les légendes standard sont : "votre adresse a été mise sur liste noire", "le mot de passe a expiré", "tous les e-mails de votre adresse seront ajoutés au dossier spam", "regardez la liste des e-mails non livrés". Comme dans les trois paragraphes précédents, les principales armes des criminels sont la peur et la curiosité des utilisateurs.
Comment se protéger ?

Installez un antivirus sur tous vos appareils pour qu'il bloque automatiquement fichiers malveillants. Si, pour une raison quelconque, vous ne souhaitez pas l'utiliser, vérifiez toutes les pièces jointes au moins légèrement suspectes. virustotal.com
Ne saisissez jamais les mots de passe manuellement. Utilisez des gestionnaires de mots de passe sur tous les appareils. Ils ne vous offriront jamais l'option de mots de passe pour entrer sur de faux sites. Si, pour une raison quelconque, vous ne souhaitez pas les utiliser, saisissez manuellement L'URL de la page sur lequel vous allez entrer le mot de passe. Cela s'applique à tous les systèmes d'exploitation.
Dans la mesure du possible, activez la vérification du mot de passe par SMS ou l'authentification à deux facteurs. Et bien sûr, il convient de rappeler que vous ne pouvez pas envoyer de numérisations de documents, de données de passeport et transférer de l'argent à des étrangers.
Peut-être que beaucoup de lecteurs, en regardant les captures d'écran des lettres, ont pensé : « Suis-je idiot d'ouvrir des fichiers à partir de telles lettres ? À un kilomètre de distance, vous pouvez voir qu'il s'agit d'un montage. Je ne m'embêterai pas avec un gestionnaire de mots de passe et une authentification à deux facteurs. Je vais juste faire attention."
Oui, la plupart des e-mails frauduleux peuvent être exposés visuellement. Mais cela ne s'applique pas lorsque l'attaque est dirigée spécifiquement contre vous.
Le spam le plus dangereux est personnel

Si une femme jalouse veut lire le courrier de son mari, alors Google lui proposera des dizaines de sites proposant le service "Piratage de courrier et de profils sur les réseaux sociaux sans prépaiement".
Le schéma de leur travail est simple : ils envoient des e-mails de phishing de haute qualité à une personne, qui sont soigneusement composés, soigneusement présentés et prennent en compte les caractéristiques personnelles d'une personne. Ces escrocs essaient sincèrement d'accrocher une victime spécifique. Ils se renseignent auprès de la cliente sur son entourage, ses goûts, ses faiblesses. Cela peut prendre une heure ou plus pour développer une attaque contre une personne spécifique, mais l'effort est payant.
Si la victime est attrapée, ils envoient au client un écran de la boîte et lui demandent de payer (le prix moyen est d'environ 100 $) pour leurs services. Après réception de l'argent, ils envoient un mot de passe de la boîte ou une archive avec toutes les lettres.
Il arrive souvent que lorsqu'une personne reçoive une lettre avec un lien vers le fichier «Vidéo compromettante sur Tanya Kotova» ( enregistreur de frappe caché) de son frère, alors rempli de curiosité. Si la lettre est accompagnée d'un texte contenant des détails connus d'un cercle restreint de personnes, la personne nie immédiatement la possibilité que le frère ait pu être piraté ou que quelqu'un d'autre se fasse passer pour lui. La victime se détend et désactive le putain d'antivirus pour ouvrir le fichier.
De tels services sont accessibles non seulement aux épouses jalouses, mais également aux concurrents peu scrupuleux. Dans de tels cas, le prix est plus élevé et les méthodes sont plus minces.
Ne comptez pas sur votre attention et votre bon sens. Au cas où, laissez un antivirus sans émotion et un gestionnaire de mots de passe vous assurer.
PS Pourquoi les spammeurs écrivent-ils des e-mails aussi « stupides » ?
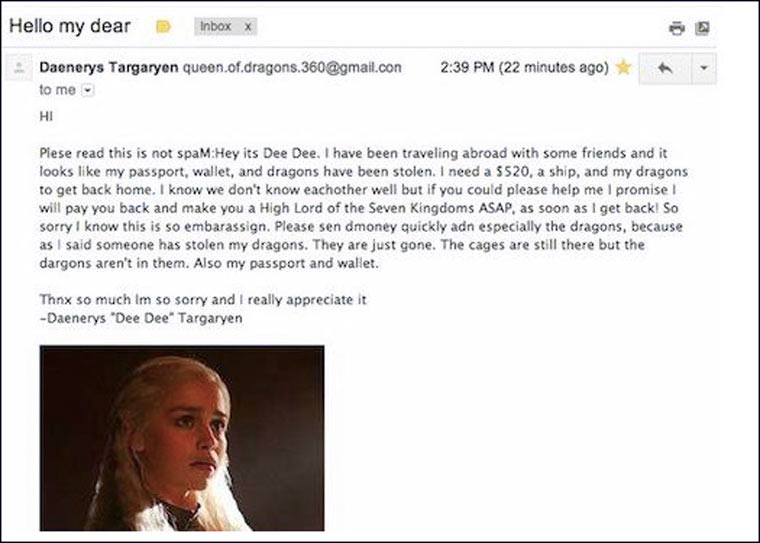
Les e-mails frauduleux soigneusement rédigés sont relativement rares. Si vous allez dans le dossier spam, vous pouvez vous amuser du fond du cœur. Quel genre de personnages ne sont pas inventés par les escrocs pour extorquer de l'argent : le directeur du FBI, l'héroïne de la série Game of Thrones, un voyant qui vous a été envoyé par des puissances supérieures et il veut dire le secret de votre avenir pour $ 15 dollars, un tueur qui vous a ordonné, mais il propose sincèrement de payer.
Une abondance de points d'exclamation, des boutons dans le corps de la lettre, une adresse d'expéditeur étrange, une salutation sans nom, traduction automatique, des erreurs grossières dans le texte, un excès évident de créativité - les lettres dans le dossier spam "crient" simplement à propos de leur origine sombre.
Pourquoi les escrocs qui envoient leurs messages à des millions de destinataires ne veulent-ils pas passer quelques heures à écrire une lettre soignée et épargner 20 dollars à un traducteur pour augmenter la réponse du public ?
Dans une étude Microsoft Pourquoi les escrocs nigérians disent-ils qu'ils viennent du Nigéria ? la question "Pourquoi les escrocs continuent-ils d'envoyer des lettres au nom de milliardaires du Nigeria, alors que le grand public connaît les "lettres nigérianes" depuis 20 ans", est analysée en profondeur. Selon les statistiques, plus de 99,99 % des destinataires ignorent ces spams.
Vous pouvez vous perdre non seulement dans la forêt, mais aussi en ligne. Et cela peut être dû au mauvais chemin ou à la mauvaise adresse menant à la ressource. Vous ne savez pas ce qu'est une URL ? Alors, avant d'entreprendre un nouveau voyage dans l'espace virtuel, abordons le système des adresses électroniques.
Quelle est l'URL
Une URL est une norme généralement acceptée pour écrire une adresse et indiquer l'emplacement d'une ressource sur Internet. De l'anglais son nom ( Localisateur de ressources uniformes) se traduit par Uniform Resource Locator. Vous pouvez trouver un décodage antérieur de l'abréviation URL - Localisateur universel de ressources (Localisateur universel de resources). Mais les deux significations complètent le concept d'URL plutôt que de se chevaucher.
Le format de base d'une entrée de structure d'URL ressemble à ceci :
://:@:/?#
- renvoie le plus souvent au protocole.
login – login utilisateur utilisé pour l'autorisation sur la ressource.
mot de passe - mot de passe utilisateur pour l'autorisation.
host est le nom de domaine de l'hôte.
port - le port hôte utilisé lors de la connexion.
URL - le chemin où se trouve la ressource demandée sur le serveur.
paramètres et ancre– la valeur des variables et l'identifiant sur une certaine ressource.
Passer la valeur des variables dans la chaîne de requête n'est possible qu'en utilisant la méthode GET.
Tenez compte du format URL de l'adresse de la page de la ressource demandée sur exemples pratiques. Sur le côté client L'URL s'affiche dans la barre d'adresse du navigateur :
Les options les plus courantes sont :
- http://en.wikipedia.org/wiki/Main_page- http est utilisé pour envoyer la requête ( Protocole de transfert hypertexte);
- https://ru.wikipedia.org/wiki/Main_page- https est utilisé comme méthode de transfert. Est une forme sécurisée du protocole http qui utilise le cryptage (SSL ou TLS );
- fttp://wikipedia.org/wiki/file.txt– protocole de transfert de fichiers fttp ;
- http://mail.ru/script.php?num=10&type=new&v=text– en passant des valeurs de variables dans la chaîne de requête à l'aide de la méthode GET.
Tout format d'URL est principalement une chaîne de caractères. Il peut inclure :
2 ; Des lettres.
2 ; Chiffres arabes (0-9).
2 ; Caractères réservés ("+", "=", "!" et autres).
2 ; Caractères spéciaux - nous y reviendrons plus en détail.
Utilisation de caractères spéciaux dans les URL
Bien entendu, ces caractères trop "spéciaux" ne sont pas utilisés dans l'URL. Mais il y en a quelques-uns :
- ? – sert à séparer le bloc avec les paramètres transférés dans la chaîne de requête ;
- & - sépare les paramètres passés les uns des autres ;
- = - sépare la variable dans le paramètre de sa valeur ;
- : - sert à séparer le protocole du reste de l'URL ;
- # - le caractère est utilisé dans la partie locale de l'adresse. Permet d'accéder à une partie spécifique de la page demandée ;
- @ - Spécifié dans les données d'enregistrement de l'utilisateur et lors du transfert de données à l'aide du protocole mailto.
Mais tout ceci n'est qu'une théorie. Par conséquent, avant d'apprendre le reste, regardons un petit exemple pratique.
Exemple illustratif
Pour plus de clarté, prenons ce simple formulaire d'inscription :
Voici son code :
Formulaire d'inscription
Dans la première ligne au début du formulaire, nous avons écrit un fichier de gestionnaire (php) pour celui-ci et une méthode de transfert de données via l'URL du serveur :
Voici maintenant le code du fichier de gestionnaire (1.php):
Votre pseudo :".$_GET["nick"]."
"; écho "
Votre âge :".$_GET["âge"]."
";
?>
Entrez les données dans le formulaire et envoyez-le au serveur pour traitement. Voici ce à quoi nous aboutirons :
Faites attention au format de l'URL dans la barre d'adresse de la première capture d'écran. Après avoir saisi les données et cliqué sur le bouton "Envoi des données", les valeurs de tous les champs sont envoyées au serveur pour traitement. Et nous sommes redirigés vers la page 1.php , où se trouve le code du gestionnaire.
Avant de regarder le résultat du traitement, jetez un œil à la barre d'adresse dans la deuxième figure. Il affiche les valeurs des champs soumis pour traitement à l'aide de la méthode GET.
La méthode POST est utilisée pour masquer les données envoyées au serveur. L'URL ci-dessus ressemblerait alors à ceci :
http://localhost/home/1.php .
Format de l'URL du site Web
Le plus souvent, les sites utilisent une URL arborescente. Autrement dit, l'adresse URL correcte se compose de plusieurs éléments imbriqués, dont le dernier est la page Web souhaitée.
Pour plus de clarté, prenons une URL spécifique, qui est une des branches de l'adresse de notre site :
https://www.html
Décomposons-le morceau par morceau :
- www.site - cette partie est nom de domaine placer. Si vous le tapez dans la barre d'adresse de votre navigateur, il vous amènera à la page principale du site. Dans la plupart des cas, il s'agit de l'indice. html ;
- modèles- cette partie L'adresse pointe vers une section spécifique du site. Dans notre cas, il s'agit de la section avec des modèles ;
- page_2.html - est l'élément final de l'URL menant à la page Web de la section thématique de la ressource.
Le plus souvent, les adresses URL des sections principales affichent entièrement le plan du site. Mais tout n'est pas si simple avec des redirections sur des sites déployés basés sur des moteurs populaires (CMS).
Caractéristiques de la création d'URL dans WordPress
Dans WordPress, comme dans tout moteur construit sur php, la génération de toutes les pages du site est dynamique. C'est-à-dire qu'une partie est extraite d'un modèle, l'autre est générée à la volée sur la base de plusieurs.... Mais une telle volatilité a un inconvénient important - la présence de morceaux de paramètres transmis dans l'URL.
De plus, cela porte atteinte non seulement à la composante esthétique de l'affichage des adresses, mais est également perçu de manière ambiguë par les moteurs de recherche. Et cela peut affecter négativement la promotion du site :
Par conséquent, il est préférable d'utiliser des URL propres sur votre site. Mais où puis-je les obtenir si le système CMS ne prévoit pas la possibilité de les modifier.
Les URL propres sont des adresses qui ne contiennent pas de paramètres passés (dans le cas de WordPress, des éléments de requête de base de données), mais uniquement le chemin d'accès au document. Autrement dit, https://www..html est un exemple d'URL propre.
Le moyen le plus simple de personnaliser l'affichage des URL dans WordPress consiste à utiliser des plugins spécialisés.
Litiges sur cette question - comment écrire correctement l'URL, avec ou sans barre oblique à la fin ? - ont été et seront. Les arguments sont variés et souvent contradictoires. Et il existe deux types de gains pour une fausse représentation d'un URL (Uniform Resource Locator). De la part des moteurs de recherche, ce sont soi-disant des pénalités pour les pages en double. En termes de performances, il s'agit supposément d'une redirection supplémentaire vers la page de la bonne entrée, générée automatiquement par le serveur.
Cependant, l'analyse spécifications techniques Les normes Internet, en particulier le document "RFC 1738 - Uniform Resource Locators (URL)", nous devons admettre que les deux options pour enregistrer l'adresse d'une ressource Web sont formellement correctes, et la sanction pour l'utilisation de l'une ou l'autre option n'est rien de plus qu'une bizarrerie moteur de recherche ou des histoires de pseudo-SEO-shnikov.
D'un point de vue concis, l'option sans slash à la fin semble plus correcte, que votre lien adresse un "fichier" sur le serveur ou un "dossier", dont la preuve indirecte sera démontrée ci-dessous. Mais il n'y a pas une seule déclaration dans le document indiquant qu'une autre option est incorrecte ou fait référence à une ressource complètement différente.
Je ne vais pas vous charger avec une traduction de plusieurs pages de la RFC mentionnée, car, premièrement, le but de la question était des barres obliques à la fin de l'URL, et deuxièmement, la publication s'adresse aux simples utilisateurs de moteurs, y compris ceux qui ne s'intéressent pas à tous les détails, ils attendent de brèves explications et des preuves substantielles. En conséquence, je vais citer des extraits de ce document en preuve et expliquer. Ceux qui ne sont pas intéressés peuvent immédiatement regarder la conclusion à la fin de l'article.
Syntaxe générale des URL
Tout d'abord, j'attire l'attention sur un extrait du paragraphe 2. General URL Syntax (syntaxe générale des URL). Dans chaque cas, je donnerai un fragment du texte dans la langue originale, puis une traduction en russe.
Les URL sont utilisées pour "localiser" les ressources, en fournissant une identification abstraite de l'emplacement de la ressource. Les URL sont utilisées pour "localiser" les ressources en fournissant une identification abstraite de l'emplacement de la ressource.
Autrement dit, l'URL elle-même est une pure abstraction. Qu'il puisse nous sembler extérieurement similaire au nom d'un fichier ou d'un dossier ne signifie nullement une indication physique de tel ou tel fichier, et non d'un autre dans l'espace fichier du serveur. Cela sera explicitement indiqué plus loin dans le document.
La note En général, en ce qui concerne les liens http, en principe, il est faux de dire que, par exemple,
- http://domain.com/path/subpath/filename.txt- pointe prétendument vers un fichier
- http://domain.com/path/subpath/- pointe soi-disant vers un dossier
- http://domain.com/path - pointe supposément à tort vers un dossier
Nous avons juste l'habitude de dire cela parce qu'il est pratique d'associer des liens à des fichiers sur le site. En fait, tous ces liens pointent vers une ressource, n'indiquant en aucun cas le type de ressource. Ce qui est caché derrière chaque ressource, c'est-à-dire quel type de fichier ou de dossier réel et quel type de contenu sera donné par un tel lien, est déjà déterminé par la configuration du serveur.
Il est important de comprendre que dans les liens, il n'y a pas de "fichier", "dossier", "sous-dossier", "texte", "image", "html", "script", "feuille de style", etc. Aucune barre oblique à la fin ou son absence ne signifie absolument rien jusqu'à ce que le lien passe par la transformation à l'intérieur du serveur, et il décide lui-même où le lien pointe réellement et quel type de contenu est caché derrière. Seule cette décision fait référence à l'architecture interne du serveur.
Schémas hiérarchiques
Ce qui suit est un extrait du paragraphe 2.3 Schémas hiérarchiques et liens relatifs.
Certains schémas d'URL (tels que les schémas ftp, http et de fichiers) contiennent des noms qui peuvent être considérés comme hiérarchiques ; les composants de la hiérarchie sont séparés par "/". Certains schémas d'URL (tels que ftp, http et file) contiennent des noms qui peuvent être considérés comme hiérarchiques ; les éléments de la hiérarchie sont séparés par "/".
C'est-à-dire qu'il est avancé que dans des schémas d'adressage séparés, il n'est pas interdit d'impliquer hiérarchiquement le contenu du localisateur de ressources, et il n'a pas encore été stipulé que la hiérarchie équivaut à n'importe quelle forme, par exemple un fichier.
Syntaxe générale du diagramme de réseau
Voici un extrait du paragraphe 3.1. Common Internet Scheme Syntax (syntaxe de schéma de réseau commun).
//:@:/Certaines ou toutes les pièces" :@", ":",
":", et "/ " peuvent être exclus. Certaines ou toutes les parties " :@", ":",
":" et "/ " peut être exclu.
La note Ceci, soit dit en passant, est une réponse à une question dérivée de celle que nous examinons. Souvent, ils se disputent sur cette question: comment donner un lien vers un domaine (hôte) - sans barre oblique à la fin ou avec une barre oblique?
Comment http://domaine.com/ ou http://domaine.com ?
Et ainsi de suite. C'est juste que la première barre oblique après le nom d'hôte est là pour séparer le nom de chemin du nom d'hôte. Le même paragraphe du document dit ceci :
Url-path Le reste du localisateur se compose de données spécifiques au schéma, et est connu sous le nom de "url-path". Il fournit les détails d'accès à la ressource spécifiée. Notez que le "/" entre l'hôte (ou le port) et l'url-path ne fait PAS partie de l'url-path. Le reste du localisateur se compose de données spécifiques au schéma et est connu sous le nom de "url-path" (chemin d'URL). Il donne des détails sur la manière d'accéder à la ressource spécifiée. Notez que le caractère "/" entre l'hôte (ou le port) et le chemin de l'URL ne fait pas partie du chemin de l'url.
Vous n'êtes en aucun cas obligé de mettre ce caractère de fin, ou de ne pas le mettre lorsque l'url-path est une chaîne vide (comme beaucoup d'entre nous diraient lorsque l'URL fait référence à la racine du site). Personne n'a le droit de vous pénaliser "pour deux prises de la page principale", car selon le cahier des charges, dans les deux cas vous liez l'URL à la même ressource.
Nous allons continuer un autre extrait du même paragraphe.
La syntaxe url-path dépend du schéma utilisé, tout comme la manière dont il est interprété. La syntaxe url-path dépend du schéma utilisé, ainsi que de la manière dont il est interprété.
Ceci est une autre confirmation que chaque schéma de localisation a son propre concept de "hiérarchie" et la façon dont il est interprété.
Hiérarchie
Pour certains systèmes de fichiers, le "/" utilisé pour indiquer la structure hiérarchique de l'URL correspond au délimiteur utilisé pour construire une hiérarchie de noms de fichiers, et ainsi, le nom de fichier ressemblera au chemin de l'URL. Cela ne signifie PAS que l'URL est un nom de fichier Unix. Le caractère "/" est utilisé pour indiquer la structure hiérarchique de l'URL selon le séparateur utilisé dans la construction de la hiérarchie des noms de fichiers, et donc dans certains systèmes de fichiers, le nom de fichier ressemble au chemin de l'URL. Mais cela ne signifie pas que l'URL est un nom de fichier de type Unix.
Bien que ce paragraphe s'applique au schéma ftp, ses déclarations s'appliquent à d'autres schémas (http, gopher, prospero, etc.). Ce n'est que dans le schéma de fichiers que la barre oblique signifie logiquement la même chose que dans les noms de fichiers, par exemple file://server_or_device/path/subpath/filename.txt.
http
Une URL HTTP prend la forme : http:// :/?où et Sont tels que décrits à la section 3.1. Si: Est omis, le port par défaut est 80. Aucun nom d'utilisateur ou mot de passe n'est autorisé. Est un sélecteur HTTP, et est une chaîne de requête. La Est facultatif, tout comme le et son "?" précédent. Si ni l'un ni l'autre Ni est présent, le "/" peut également être omis. Au sein de la Et Composants, "/", ";", "?" sont réservés. Le caractère "/" peut être utilisé dans HTTP pour désigner une structure hiérarchique. L'URL du schéma http prend la forme : http:// :/?où et Comme décrit au paragraphe 3.1. Si un: Omis, le port par défaut est supposé être 80. Le nom d'utilisateur ou le mot de passe n'est pas valide. C'est un sélecteur HTTP, et - chaîne de requête. Il est facultatif, tout comme avec le caractère "?" précédent. Si ni l'un ni l'autre Ni ne sont pas présents, le caractère "/" peut également être omis. Dans les éléments Et personnages "/", ";", "?" sont réservés. Le caractère "/" peut être utilisé dans HTTP pour définir une structure hiérarchique.
La note Il indique également que vous pouvez spécifier un lien sans barre oblique finale. Dans ce cas, nous parlions d'une situation où le chemin du lien est vide - pointe vers la racine de l'hôte.
Notation formelle
Et enfin, un extrait du paragraphe 5. BNF pour les schémas d'URL spécifiques (notation formelle pour les schémas d'URL spécifiques).
Ici, les pièces optionnelles sont indiquées entre crochets. Un astérisque avant une parenthèse indique 0 ou plusieurs répétitions du fragment comme indiqué entre parenthèses. La barre verticale doit être comprise comme OU.
Hostport = host [ ":" port ] ... ... httpurl = "http://" hostport [ "/" hpath [ "?" chercher]] hpath= hsegment *[ "/" hsegment ] hsegment = *[ uchar | ";" | ":" | "@" | "&" | "=" ] recherche = *[ uchar | ";" | ":" | "@" | "&" | "=" ] ... ... lowalpha = "a" | "b" | "c" | "d" | "e" | "f" | "g" | h | "je" | "je" | "k" | "je" | "m" | "n" | "o" | p | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z" hialpha = "A" | "B" | "C" | "D" | "E" | "F" | "G" | "H" | "je" | "J" | "K" | "L" | "M" | "N" | "O" | "P" | Q | "R" | "S" | "T" | U | "V" | W | "X" | "Y" | "Z" alpha = lowalpha | chiffre hialpha = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" sûr = "$" | "-" | "_" | "." | "+" supplémentaire = "!" | "*" | """ | "(" | ")" | "," hexadécimal = chiffre | "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" | "c" | "d" | "e" | "f" escape = "%" hex hex non réservé = alpha | chiffre | sûr | extra uchar = non réservé | escape
Faites attention à la manière exacte dont l'élément hpath est formé selon les règles - le chemin du lien. Les éléments hsegment d'un chemin - les segments - sont séparés par une barre oblique. Comme s'il faisait allusion à l'idée importante que la barre oblique divise le chemin en parties hiérarchiques et est toujours à l'intérieur. En principe, il n'est pas exclu que le dernier élément de hsegment soit une chaîne vide (ceci découle de sa définition), puis qu'un slash fermant apparaisse involontairement à la fin de l'URL.
Conclusion
La division d'un chemin en segments à l'aide d'un slash implique la présence de noms non vides de ces segments. Ainsi, un lien avec une barre oblique à la fin semble illogique (bien que non interdit) dans le sens où il semble pointer vers un dernier segment du chemin, mais, de plus, ne nomme en aucune façon ce segment. Tout comme le lien est illogique (mais aussi pas interdit) http://domain.com/level1////levelX, qui ne nomme pas les segments de chemin intermédiaires si le chemin est considéré non pas comme un ensemble de paramètres, mais comme une structure hiérarchique.
En langage familier, le contenu sémantique des deux liens peut être expliqué comme suit :
- - adresses au point de départ par défaut du deuxième niveau de la hiérarchie
- - s'adresse à un point indéfini à l'intérieur du deuxième niveau de la hiérarchie, c'est-à-dire comme si le serveur était affecté à la tâche "nous nous référons au deuxième niveau de la hiérarchie, et vous déterminez vous-même quel point vous considérez comme le point par défaut premier dans ce niveau."
De tout ce qui précède, il résulte, ce qui est similaire à la façon dont les liens
- http://domaine.com
- http://domaine.com/
diriger le visiteur vers la racine du site, et par exemple des liens
- http://domain.com/level1/level2
- http://domain.com/level1/level2/
diriger le visiteur vers le deuxième niveau de la hiérarchie des ressources. Et le fait qu'un certain serveur puisse interpréter la barre oblique à la fin à sa manière et commencer à rediriger en interne vers le point de départ par défaut du niveau - disons, vers le fichier index.html, est déjà un cas particulier d'une configuration spécifique. Tout comme dans la mise en œuvre du système d'URL lisible par l'homme, toutes les entrées de redirection utilisant le module serveur mod_rewrite définissent leur propre concept (inhérent à un moteur particulier) de la structure hiérarchique de l'URL, dans laquelle les éléments de chemin peuvent être assimilés à des paramètres de requête. et n'ont rien à voir avec structure de fichier site (exemple classique : http://domain.com/ru/path , l'élément ru est un paramètre de la langue courante, pas un dossier sur le site).
J'insiste sur le fait qu'il s'agit de la connaissance interne du serveur, de par sa configuration, ainsi que du moteur installé sur le site. Un service externe, disons le même moteur de recherche, ne peut pas faire de conjectures et n'a aucune idée si et comment les liens avec et sans barre oblique diffèrent, à moins que le serveur du site ne soit spécifiquement configuré pour afficher un contenu différent sur ces liens.
Noter
Au niveau de la mise en œuvre, la question des barres obliques aux extrémités n'est pas d'une importance fondamentale, ce qui est confirmé par de nombreux portails éminents. Sur certains, tous les liens se terminent par une barre oblique, sur d'autres - sans barre oblique. L'essentiel est que le contenu des liens ne se révèle pas différent, et pour Yandex, vous devez également enregistrer une redirection 301 à partir des liens que vous n'utilisez pas (par exemple, se terminant par une barre oblique) vers ceux que vous utilisez . Le fait est que, selon des affirmations non confirmées du service d'assistance Yandex, ce moteur de recherche peut prétendument faire des erreurs et non "coller" (mémoriser à sa connaissance) ou, avec un certain retard, coller des adresses slash sans slash en une seule.

Voici un exemple d'implémentation d'une telle redirection à l'aide du fichier racine .htaccess :
# si l'url d'entrée se termine par une barre oblique (em, ami), # définissez la 301e redirection vers la page sans barre oblique RewriteCond %(REQUEST_URI) ^/.+/$ RewriteRule ^(.*?)/+$ http:/ /%(HTTP_HOST )/$1
Google (encore une fois, selon des informations non confirmées par l'expérience), ces redirections ne sont pas importantes, car il sait soi-disant coller ces adresses correctement et sans redirections.
Rappelles toi De nombreuses personnes se considèrent comme des spécialistes du référencement. Mais tous ne sont pas comme ça. De plus, le sujet du référencement est souvent spéculé sans connaissance ni raison appropriées, simplement dans l'attente que vous êtes également ignorant dans ce domaine, de sorte que vous pouvez facilement croire en n'importe quelles "nouilles". Lorsqu'on vous dit que certaines de vos pages "sont sorties de l'index", utilisez la très bonne recommandation de Yandex : vous pouvez vous renseigner sur les erreurs d'indexation, le cas échéant, dans le service Yandex.Webmaster. Dans ce service, vous pouvez toujours voir une liste de vos pages dans la recherche et une liste des pages exclues de la recherche pour une raison quelconque. Google a un service similaire. Faites confiance à cette connaissance, et non à l'opinion de pseudo-spécialistes qui ont entendu quelque chose du coin de leur oreille quelque part, et sur cette base vous recommandent de faire ce qu'ils pensent être la seule bonne chose.
Ici Un article très intéressant, Little Known SEO Facts, publié en avril 2017. Il existe une vaste étude avec de nombreuses captures d'écran, qui a commencé dans le but de tester la validité de plusieurs jugements populaires dans le domaine de la promotion des moteurs de recherche et de transmettre les résultats au propriétaire moyen du site à l'aide d'exemples compréhensibles. La même étude démontre incidemment au jeune lecteur un certain nombre de caractéristiques évidentes, banales et plutôt même discrètes, mais toujours surprenantes, des résultats de recherche organiques dans Recherches Google et Yandex.
Ici Bien que le lien suivant ait peu à voir avec le référencement, il sera toujours attrayant pour les maîtres du référencement qui recherchent maintenant des commandes supplémentaires. Une offre commerciale est placée sous le lien, les gars ont trouvé une façon intéressante d'utiliser le site. Les entreprises privées se voient proposer de créer un panneau d'affichage en ligne basé sur un thème particulier, sous le contrôle duquel le site, ou plutôt son premier écran, ressemble à une bannière s'étendant sur des panneaux publicitaires extérieurs. Sur le smartphone, j'ai tourné l'écran, l'étirement est devenu vertical et occupe toute la surface de l'écran, s'est retourné, est devenu horizontal et à nouveau plein écran. Et sous le premier écran, il y a un appendice de texte où les utilisateurs ne font généralement pas défiler, mais le moteur de recherche voit bien ce texte. Ainsi, les pinocchios les plus intelligents du commerce régional achètent ces panneaux d'affichage en ligne bon marché comme une alternative rentable publicité contextuelle et le Réseau Display de Yandex et Google. Et pour profiter au maximum de traîner au local index de recherche, pour promouvoir leur bouclier, ils sont prêts à payer immédiatement de l'argent pour un tas de textes de référencement, ce qui sent le montant non aigre. À en juger par les rumeurs, des commandes de 30 kilo roubles passent, et puisque les gars sous-traitent leurs partenaires à des SEO, ici vous pouvez construire des ponts de partenariat et obtenir de bons revenus.
: J'ai toujours voulu comprendre cela, mais sa signification était si petite qu'il y avait toujours une raison de ne pas le faire :)
Et vous vous demandiez : URL - qu'est-ce que c'est?
Je tombe toujours sur ça, mais je ne voulais toujours pas comprendre la différence entre les termes URI, URL, URN, et puis soudain un post (malheureusement, il est déjà tombé dans l'oubli), j'ai décidé - je vais le lire moi-même, et dire aux autres, même si, comme mentionné ci-dessus, rien ne changera à cela, mais j'aime parfois épeler, alors lisez le traducteur sensé :
Avez-vous déjà prêté attention à la barre d'adresse de votre navigateur ? Qu'est-ce que c'est ça? URI, URL ou URN ? Beaucoup d'entre nous ne font pas la distinction entre URI, URL, URN, et certains d'entre nous n'ont même jamais entendu parler des termes URI et URN, tout le monde utilise simplement le terme URL. Essayons de comprendre cela ensemble.
Explication des abréviations
URI - Uniform Resource Identifier (identificateur uniforme identifiant Ressource)
URL - Uniform Resource Locator (unifié localisateur Ressource)
URN - Nom de ressource uniforme (uniforme Nom Ressource)
Attention, ici la vérité réside dans les petites choses, mais jusqu'à présent rien n'est clair, une sorte de gâchis. Allons plus loin.
Définition
URI : indique le nom et l'adresse d'une ressource sur le Web. Généralement divisé en URL et URN, l'URL et l'URN sont donc les composants d'un URI.
URL : l'adresse d'une ressource sur le Web. L'URL définit l'emplacement de la ressource et comment y accéder.
URN : le nom d'une ressource sur le Web. L'intérêt d'un URN est qu'il ne définit que le nom d'un élément spécifique qui peut être trouvé à plusieurs endroits spécifiques.
Rien de mieux qu'un exemple concret
URI = http://site/2009/09/uri-url-urn.html
URL = http://site
URL=/2009/09/uri-url-urn.html
Résumé
URI est le concept d'un identifiant abstrait, tandis que URL et URN sont des implémentations concrètes d'adresses et de noms.
J'espère que tout est clair pour tout le monde. Soyez intelligent!
La perception de chacun de nous est individuelle, donc - argumentez et lisez les discussions dans les commentaires de l'article, il y a beaucoup de choses intéressantes.